第 25 章:理解垃圾回收器(Understanding the Garbage Collector)
原文:Anil Madhavapeddy and Yaron Minsky, Real World OCaml: Functional Programming for the Masses, Second Edition, Chapter 25。维护者已确认本书为开源书籍,可翻译并发布用于学习研究。
本章包含 Stephen Weeks 和 Sadiq Jaffer 的贡献。
第 24 章已经描述过单个 OCaml 变量的运行时格式。执行程序时,OCaml 会通过定期扫描已分配值,并在它们不再需要时释放它们,来管理这些变量的生命周期。这意味着应用不需要手动实现内存管理,也会极大降低内存泄漏悄悄进入代码的可能性。
OCaml 运行时是一个 C 库,它提供可由正在运行的 OCaml 程序调用的例程。运行时管理一个堆(heap),也就是从操作系统获取的一组内存区域。运行时使用这些内存保存堆块(heap block),并响应 OCaml 程序的分配请求,用 OCaml 值填充它们。
25.1 标记-清扫垃圾回收(Mark and Sweep Garbage Collection)
当已分配堆块池中没有足够内存来满足分配请求时,运行时系统会调用垃圾回收器(GC)。OCaml 程序不能在用完一个值后显式释放它。相反,GC 会定期判断哪些值是活的(live),哪些值是死的(dead),也就是不再使用的。死值会被收集,其内存会重新提供给应用复用。
GC 不会在值被分配和使用时持续跟踪它们。相反,它会从应用总能访问到的一组根(root)值开始,例如栈,定期扫描这些值。GC 会维护一个有向图,其中堆块是节点;如果堆块 b1 的某个字段是指向堆块 b2 的指针,那么就有一条从 b1 到 b2 的边。
从根出发沿图中的边可达的所有块都必须保留,不可达块则可由应用复用。OCaml 用于执行这种堆遍历的算法通常称为标记-清扫(mark and sweep)垃圾回收。接下来会进一步解释。
25.2 分代垃圾回收(Generational Garbage Collection)
通常的 OCaml 编程风格会分配许多小值,它们只使用很短时间,随后再也不会被访问。OCaml 利用这一事实,通过使用分代(generational)GC 来提升性能。
分代 GC 会根据块存活的时间长短,维护不同的内存区域来保存块。OCaml 的堆被拆成两个这样的区域:
- 一个小的、固定大小的小堆(minor heap),多数块最初都会分配到这里。
- 一个更大的、大小可变的大堆(major heap),用于保存存活时间更长的块。
典型函数式编程风格意味着年轻块往往很快死亡,而老块往往比年轻块存活更久。这通常称为分代假设(generational hypothesis)。
OCaml 对大堆和小堆使用不同内存布局和垃圾回收算法,以适应这种分代差异。接下来会更详细地解释它们的不同之处。
注:
Gc模块与OCAMLRUNPARAMOCaml 提供几种机制来查询和修改运行时系统的行为。
Gc模块在 OCaml 代码中提供这些功能,本章余下部分会频繁提到它。和其他几个标准库模块一样,Core 会修改标准 OCaml 库中的Gc接口。下面的解释会假定你已经打开了Core。也可以在启动应用前设置
OCAMLRUNPARAM环境变量,以控制 OCaml 程序的行为。这让你无需重新编译就能设置 GC 参数,例如基准测试不同设置的效果。OCAMLRUNPARAM的格式记录在 OCaml 手册中。
25.3 快速小堆(The Fast Minor Heap)
小堆保存大多数短生命周期值。它由一个连续的虚拟内存块组成,其中包含一串 OCaml 块。如果有空间,分配新块就是快速的常数时间操作,只需要几条 CPU 指令。
为了对小堆进行垃圾回收,OCaml 使用复制式收集(copying collection),把小堆中所有活块移动到大堆。这项工作与小堆中活块数量成正比,而根据分代假设,这个数量通常很小。一般来说,垃圾回收器运行时会 stop the world,也就是暂停应用;因此,让它快速完成非常重要,这样应用才能以最小中断继续运行。
25.3.1 在小堆上分配(Allocating on the Minor Heap)
小堆是一块连续虚拟内存,通常只有几 MB 大小,因此可以快速扫描。
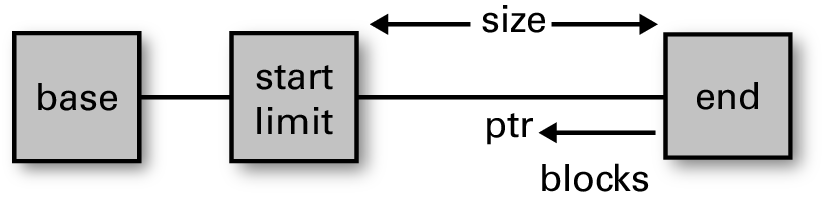
运行时把小堆边界存放在两个指针中,用于界定堆区域的开始和结束(caml_young_start 和 caml_young_end,为了简洁,下面会省略 caml_young 前缀)。base 是系统 malloc 返回的内存地址,start 会对齐到 base 之后最近的机器字边界,以便更容易存储 OCaml 值。
在一个全新的小堆中,limit 等于 start,当前 ptr 等于 end。随着块被分配,ptr 会递减,直到到达 limit;此时会触发一次小堆垃圾回收。
在小堆中分配块只需要让 ptr 减去块大小(包括头部),并检查它是否不小于 limit。如果剩余空间不足以容纳该块,也就是递减后会越过 limit,就会触发一次小堆垃圾回收。在多数 CPU 架构上,这是一个非常快速的检查,并且不需要分支。
理解分配(Understanding Allocation)
你可能会想,既然 limit 看起来总是等于 start,为什么还需要它?原因是,运行时调度一次小堆收集的最简单方式,是把 limit 设置为等于 end。这样做之后,下一次分配永远不会有足够空间,于是一定会触发垃圾回收。这样的提前收集有各种内部原因,例如处理挂起的 UNIX 信号;不过,它们通常与应用代码无关。
可以写出长时间都不分配,甚至完全不分配的循环或递归。为了确保 UNIX 信号和其他需要中断正在运行 OCaml 程序的内部记账仍然发生,编译器会向生成的原生代码中插入轮询点(poll point)。
这些轮询点会检查 ptr 与 limit。开发者应预期它们被放在每个函数的开头,以及循环的回边上。编译器包含一个数据流 pass,会移除除了最小必要集合之外的轮询点,以确保这些检查能在有界时间内发生。
注:设置小堆大小
OCaml 的默认小堆大小在 64 位平台上通常是 2 MB,但如果使用 Core,会增加到 8 MB。Core 通常偏好提升性能的默认设置,代价是更大的内存轮廓。可以通过
OCAMLRUNPARAM的s=<words>参数覆盖该设置。程序启动后,也可以调用Gc.set函数修改它:动态修改 GC 大小会立即触发一次小堆收集。注意,Core 会把默认小堆大小从标准 OCaml 安装值大幅调高。如果运行在内存非常受限的环境中,你会希望降低这个值。
25.4 长生命周期大堆(The Long-Lived Major Heap)
大堆保存程序中大部分生命周期较长和值较大的内容。它由任意数量的非连续虚拟内存块组成,每个内存块都包含活块,并夹杂着空闲内存区域。运行时系统维护一个空闲列表数据结构,索引所有已经分配的空闲内存,并用它满足 OCaml 块的分配请求。
大堆通常比小堆大得多,大小可以扩展到 GB 级。它通过标记-清扫垃圾回收算法清理,该算法分为几个阶段:
- 标记(mark)阶段扫描块图,并通过设置块头中 tag 的一位(称为 color tag)来标记所有活块。
- 清扫(sweep)阶段顺序扫描堆块,并识别之前未标记的死块。
- 压缩(compact)阶段把活块重新定位到一个新分配的堆中,以消除空闲列表中的缝隙。这可以防止长时间运行程序中的堆块碎片化,通常比标记和清扫阶段发生得少得多。
大堆垃圾回收也必须 stop the world,以确保块可以移动,而正在运行的应用不会观察到这种移动。标记和清扫阶段会按堆切片增量运行,避免让应用长时间暂停;每个切片之前还会先执行一次快速小堆收集。只有压缩阶段会一次性触碰所有内存,而且它是相对少见的操作。
25.4.1 在大堆上分配(Allocating on the Major Heap)
大堆由连续内存块组成的单向链表构成,按虚拟地址递增排序。每个块都是通过 malloc(3) 分配的单个内存区域,由头部和数据区组成,数据区中包含 OCaml 堆块。堆块头部包含:
- 包含该块的内存区域的 malloc 虚拟地址
- 数据区大小,以字节为单位
- 用于堆压缩期间合并小块以消除碎片的分配大小,以字节为单位
- 指向链表中下一个堆块的链接
- 指向块范围开始和结束的指针,该范围可能包含未检查字段,稍后需要扫描。只在标记栈溢出后使用。
每个块的数据区都从页边界开始,其大小是页大小(4 KB)的倍数。它包含一串连续堆块,可以小到一两个 4 KB 页,但通常会按 1 MB 块分配,在 32 位架构上则是 512 KB。
控制大堆增量(Controlling the Major Heap Increment)
Gc 模块使用 major_heap_increment 值控制大堆增长。它定义每次扩展向大堆添加的机器字数量,并且是初始启动后操作系统能从 OCaml 运行时观察到的唯一内存分配操作,因为小堆大小是固定的。
在大堆上分配 OCaml 值时,首先检查块空闲列表,寻找可以放置它的合适区域。如果空闲列表没有足够空间,运行时会通过分配一个足够大的新堆块来扩展大堆。该块随后加入空闲列表,再次检查空闲列表;这一次肯定会成功。
较旧版本的 OCaml 要求为大堆增量设置固定字节数。这个值很难正确设置:太小会导致许多较小堆块分散在不同虚拟内存区域中,需要 OCaml 运行时做更多记账来跟踪它们;太大又会让小堆程序浪费内存。
可以使用 Gc.tune 设置这个值,但出于向后兼容原因,这些值有点反直觉。小于 1000 的值会被解释为百分比,默认是 15%。1000 及以上的值会被视为原始字节数。但多数时候,你根本不需要设置这个值。
25.4.2 内存分配策略(Memory Allocation Strategies)
大堆会尽力高效管理内存分配,并依赖堆压缩来确保内存保持连续、没有碎片。默认分配策略通常适用于大多数应用,但也值得记住还有其他选项。
在大堆中分配新块时,总是先检查块空闲列表。默认空闲列表搜索称为最佳适配分配(best-fit allocation),也可以使用下一适配(next-fit)和首次适配(first-fit)算法作为替代。
最佳适配分配(Best-Fit Allocation)
最佳适配分配器结合了两种策略。第一种是按大小分离的空闲列表,它基于一个观察:OCaml 中几乎所有大堆分配都很小,例如列表元素和元组通常只有几个机器字。best fit 会为不超过 16 个机器字的大小维护独立空闲列表,从而为多数分配提供快速路径。对于这些大小的分配,可以从对应分离空闲列表中服务;如果为空,则从下一个有空间的大小服务。
第二种策略用于更大分配,它使用一种专门的数据结构,称为 splay tree,来表示空闲列表。这是一种会适应近期访问模式的搜索树。对这里的用途来说,最常请求的分配大小会最快访问。
如果分离空闲列表中没有更大大小可用,小分配以及大于 16 个机器字的大分配都会由主空闲列表服务。空闲列表会被查询,找到至少与请求分配一样大且最小的块。
最佳适配分配是默认分配机制。它在分配成本(CPU 工作量)和堆碎片之间提供了良好折中。
下一适配分配(Next-Fit Allocation)
下一适配分配会保留一个指针,指向空闲列表中最近一次用于满足请求的块。当新请求到来时,分配器从下一个块搜索到空闲列表末尾,然后再从空闲列表开头搜索到该块。
下一适配是一种成本相当低的分配机制,因为同一个堆块可以在多次分配请求中复用,直到耗尽。这也意味着它具有良好内存局部性,可以更好地使用 CPU 缓存。下一适配的主要缺点是,由于大多数分配都很小,空闲列表开头的大块会变得高度碎片化。
首次适配分配(First-Fit Allocation)
如果程序分配很多不同大小的值,有时会发现空闲列表变得碎片化。在这种情况下,即便存在空闲块,GC 也被迫执行昂贵的压缩,因为没有任何单个块大到足以满足请求。
首次适配分配侧重减少内存碎片,从而减少压缩次数,但代价是内存分配较慢。每次分配都会从头扫描空闲列表,寻找合适空闲块,而不是像下一适配分配器那样复用最近的堆块。
对于一些在负载下需要更接近实时行为的工作负载,降低堆压缩频率带来的收益会超过额外分配成本。
控制堆分配策略(Controlling the Heap Allocation Policy)
可以通过调用 Gc.tune 设置堆分配策略:
# Gc.tune ~allocation_policy:First_fit ();;
- : unit = ()
同样的行为也可以通过环境变量控制:把 OCAMLRUNPARAM 设置为 a=0 表示下一适配,a=1 表示首次适配,a=2 表示最佳适配。
25.4.3 标记和扫描堆(Marking and Scanning the Heap)
标记过程可能需要很长时间才能扫完整个大堆,而且运行时必须暂停主应用。因此,它会以切片(slice)方式增量运行。堆中的每个值在头部都有一个 2 位 color 字段,用于存储该值是否已经标记的信息,以便 GC 在切片之间轻松恢复。
- 蓝色:在空闲列表上,当前未使用
- 白色(标记期间):尚未到达,但可能可达
- 白色(清扫期间):不可达,可以释放
- 黑色:可达,并且其字段已经扫描
值头中的 color tag 保存了标记过程的大部分状态,允许它暂停并稍后恢复。分配时,所有堆值最初都会被赋予白色,表示它们可能可达但还没有扫描。GC 和应用会在标记大堆的一个切片与实际执行程序逻辑之间交替。OCaml 运行时会根据分配速率和可用内存,为每个大堆切片大小计算一个合理值。
标记过程从一组总是活的根值开始,例如应用栈和全局变量。这些根值会被染成黑色,并压入一种称为 mark stack 的专用数据结构。标记过程会从栈中弹出一个值并检查其字段。任何包含白色块的字段都会变成黑色,并压入标记栈。
这个过程会重复,直到标记栈为空,且没有更多值需要标记。不过,这个过程中有一个重要边界情况。标记栈只能增长到一定大小;超过该大小后,GC 就无法继续递归进入中间值,因为它没有地方在跟随字段时保存它们。这称为标记栈溢出,随后会开始一个称为 pruning 的过程。pruning 会完全清空标记栈,并把每个块的地址概括为每个堆块头中的开始和结束范围。
稍后在标记过程中,当标记栈为空时,它会通过重新变黑(redarkening)堆来重新填充。这会从第一个按地址排序、存在需要 redarkening 的块的堆块开始(也就是在 prune 时从标记栈中移除的块),并把 redarkening 范围中的条目加入标记栈,直到它有四分之一满。清空和补充循环会继续,直到没有堆块留下需要 redarkening 的范围。
控制大堆收集(Controlling Major Heap Collections)
可以通过 major_slice 调用触发大堆 GC 的单个切片。它会先执行一次小堆收集,然后执行单个切片。切片大小通常由 GC 自动计算为合适值,并返回该值,以便必要时在后续调用中修改:
# Gc.major_slice 0;;
- : int = 0
# Gc.full_major ();;
- : unit = ()
space_overhead 设置控制 GC 在把切片大小设得更大时的激进程度。它表示因为 GC 没有立即收集不可达块而会“浪费”的、相对于活数据的内存比例。Core 默认值是 100,反映一个通常并不过度受内存约束的系统。如果内存很多,可以把它设得更高;如果想让 GC 更努力工作、更快收集块,并愿意付出更多 CPU 时间,可以把它设得更低。
25.4.4 堆压缩(Heap Compaction)
经过一定次数的大堆 GC 周期后,堆可能开始碎片化,因为值释放顺序与分配顺序不同。这会让 GC 更难为新分配找到连续内存块,从而可能导致堆不必要地增长。
堆压缩周期会把大堆中的所有值重新定位到一个新堆中,让它们再次连续地放在内存中,从而避免这种情况。该算法的朴素实现需要额外内存来存储新堆,但 OCaml 会在现有堆中就地执行压缩。
注:控制压缩频率
Gc模块中的max_overhead设置定义了空闲内存与已分配内存之间的关系,超过该关系后会启动压缩。值为
0会在每个大堆垃圾回收周期后触发压缩;最大值1000000则会完全禁用堆压缩。除非你有异常分配模式,导致压缩频率高于通常水平,否则默认设置应该没问题:
25.4.5 跨代指针(Intergenerational Pointers)
分代收集的一个复杂之处来自这样一个事实:小堆清扫比大堆收集频繁得多。为了知道小堆中的哪些块是活的,收集器必须跟踪哪些小堆块被大堆块直接指向。没有这些信息,每次小堆收集也都需要扫描大得多的大堆。
OCaml 维护一组这样的跨代指针,以避免大堆和小堆收集之间的这种依赖。每当大堆块被修改为指向小堆块时,编译器都会引入一个写屏障来更新这个所谓的记忆集(remembered set)。
可变写屏障(The Mutable Write Barrier)
写屏障会对代码结构产生深远影响。这也是使用不可变数据结构并为变更分配一份新副本,有时会比原地修改记录更快的原因之一。
OCaml 编译器会跟踪所有可变类型,并在修改前添加一次对运行时 caml_modify 函数的调用。该调用会检查目标写入位置以及要改成的值,并确保记忆集保持一致。虽然写屏障相当高效,但有时仍可能比直接在快速小堆上分配一个新值并执行一些额外小堆收集更慢。
用一个简单测试程序亲自看看。编译下面代码前,需要通过 opam install core_bench 安装 Core 基准测试套件:
open Core
open Core_bench
module Mutable = struct
type t =
{ mutable iters : int
; mutable count : float
}
let rec test t =
if t.iters = 0
then ()
else (
t.iters <- t.iters - 1;
t.count <- t.count +. 1.0;
test t)
end
module Immutable = struct
type t =
{ iters : int
; count : float
}
let rec test t =
if t.iters = 0
then ()
else test { iters = t.iters - 1; count = t.count +. 1.0 }
end
let () =
let iters = 1_000_000 in
let count = 0.0 in
let tests =
[ Bench.Test.create ~name:"mutable" (fun () ->
Mutable.test { iters; count })
; Bench.Test.create ~name:"immutable" (fun () ->
Immutable.test { iters; count })
]
in
Bench.make_command tests |> Command_unix.run
这个程序定义了一个可变类型 t1 和一个不可变类型 t2。基准循环会遍历两个字段并递增一个计数器。编译并执行它时,可以加一些额外选项来显示发生的垃圾回收量:
$ dune exec -- ./barrier_bench.exe -ascii alloc -quota 1
Estimated testing time 2s (2 benchmarks x 1s). Change using '-quota'.
Name Time/Run mWd/Run mjWd/Run Prom/Run Percentage
----------- ---------- --------- ---------- ---------- ------------
mutable 5.06ms 2.00Mw 20.61w 20.61w 100.00%
immutable 3.95ms 5.00Mw 95.64w 95.64w 77.98%
这里存在空间/时间权衡。可变版本比不可变版本花费更久,但分配的小堆机器字少得多。OCaml 中的小堆分配非常快,所以使用不可变数据结构通常比使用更传统的可变版本更好。另一方面,如果只是很少修改一个值,那么承受写屏障成本而完全不分配可能更快。
唯一确定方法是在真实场景下用 Core_bench 对程序做基准测试,并实验这些权衡。命令行基准二进制文件有许多有用选项,会影响垃圾回收行为和输出格式:
$ dune exec -- ./barrier_bench.exe -help
Benchmark for mutable, immutable
barrier_bench.exe [COLUMN ...]
Columns that can be specified are:
time - Number of nano secs taken.
cycles - Number of CPU cycles (RDTSC) taken.
alloc - Allocation of major, minor and promoted words.
gc - Show major and minor collections per 1000 runs.
percentage - Relative execution time as a percentage.
speedup - Relative execution cost as a speedup.
samples - Number of samples collected for profiling.
...
25.5 给值附加 Finalizer 函数(Attaching Finalizer Functions to Values)
OCaml 的自动内存管理保证,当一个值不再使用时,它最终会被释放,要么通过 GC 清扫,要么因为程序终止。有时,在一个值即将被 GC 释放之前运行额外代码会很有用,例如检查文件描述符是否已经关闭,或者记录一条日志消息。
注:哪些值可以附加 finalizer?
各种值不能附加 finalizer,因为它们并不是堆分配的。未堆分配的值包括整数、常量构造器、布尔值、空数组、空列表和 unit 值。到底哪些内容堆分配、哪些不是,具体列表依赖实现;这也是 Core 提供
Heap_block模块,以便在附加 finalizer 前显式检查的原因。有些常量值可以堆分配,但在程序生命周期内永远不会释放,例如由整数字面量组成的列表。
Heap_block会显式检查该值是否位于大堆或小堆中,并拒绝大多数常量值。编译器优化也可能复制某些不可变值,例如数组中的浮点值。这些值可能在程序仍使用另一个重复副本时被 finalizer 处理。
Core 提供 Heap_block 模块,用于动态检查给定值是否适合 finalizing。Core 把注册 finalizer 的函数放在 Core.Gc.Expert 模块中。finalizer 可以在任意线程的任意时间运行,因此在多线程上下文中很难推理。第 17 章讨论过的 Async 会用自己的模块遮蔽 Gc 模块,其中包含一个并发安全的 Gc.add_finalizer 函数。特别是,finalizer 会被调度到自己的 Async job 中,Async 还会小心捕获异常,并把它们抛给适当的 monitor 进行错误处理。
用一个小例子探索这一点。它会为几种不同类型的值附加 finalizer,这些值都是堆分配的。
open Core
open Async
let attach_finalizer n v =
match Heap_block.create v with
| None -> printf "%20s: FAIL\n%!" n
| Some hb ->
let final _ = printf "%20s: OK\n%!" n in
Gc.add_finalizer hb final
type t = { foo : bool }
let main () =
attach_finalizer "allocated variant" (`Foo (Random.bool ()));
attach_finalizer "allocated string" (Bytes.create 4);
attach_finalizer "allocated record" { foo = Random.bool () };
Gc.compact ();
return ()
let () =
Command.async
~summary:"Testing finalizers"
(Command.Param.return main)
|> Command_unix.run
构建并运行后,应该会看到下面输出:
$ dune exec -- ./finalizer.exe
allocated record: OK
allocated string: OK
allocated variant: OK
GC 会按释放顺序调用 finalization 函数。如果多个值在同一个 GC 周期中变得不可达,finalization 函数会按照相应 add_finalizer 调用的反序执行。每次调用 add_finalizer 都会向函数集合添加一个函数,这些函数会在该值变得不可达时运行。只要愿意,可以让许多 finalizer 都指向同一个堆块。
垃圾回收确定某个堆块 b 不可达之后,会从 finalizer 集合中移除与 b 关联的所有函数,并按顺序把每个函数应用到 b。因此,附加到 b 的每个 finalizer 函数最多运行一次。不过,程序终止并不会导致所有 finalizer 都在运行时退出前运行。
finalizer 可以使用 OCaml 的所有特性,包括通过赋值让值重新可达,从而防止它被垃圾回收。它也可以永远循环,这会导致其他 finalizer 与它交错执行。