第 26 章:编译器前端:解析与类型检查(The Compiler Frontend: Parsing and Type Checking)
原文:Anil Madhavapeddy and Yaron Minsky, Real World OCaml: Functional Programming for the Masses, Second Edition, Chapter 26。维护者已确认本书为开源书籍,可翻译并发布用于学习研究。
把源代码编译成可执行程序,会涉及一组相当复杂的库、链接器和汇编器。虽然 Dune 基本会把这种复杂性隐藏起来,但理解这些部件如何工作仍然有用:它能帮助你调试性能问题,或者在现有工具处理不好某些特殊情形时想出解决方案。
OCaml 非常强调静态类型安全,并会尽可能早地拒绝不满足要求的源代码。编译器通过让源代码经过一系列检查和转换来完成这件事。每个阶段都会完成自己的职责,例如类型检查、优化或代码生成,并丢弃前一阶段的一部分信息。最终的原生代码输出是低层汇编代码,它已经不知道编译器最初看到的 OCaml 模块或对象是什么。
本章会讨论以下主题:
- 编译器代码库与编译流水线概览,以及每个阶段表示什么。
- 解析,也就是从原始文本到抽象语法树。
- PPX,它会进一步转换 AST。
- 类型检查,包括模块解析。
编译流程余下部分的细节,也就是最终抵达可执行代码的过程,会在下一章第 27 章“编译器后端:字节码与原生代码”中介绍。
26.1 工具链概览(An Overview of the Toolchain)
OCaml 工具接收文本源代码作为输入,模块和签名分别使用 .ml 与 .mli 文件扩展名。我们已经在第 5 章“文件、模块与程序”中解释过构建过程的基础,因此这里会假定你已经构建过几个 OCaml 程序。
每个源文件都表示一个单独构建的编译单元(compilation unit)。随着编译器推进各个编译阶段,它会生成带有不同扩展名的中间文件。链接器接收一组已编译单元,并产生一个独立可执行文件或库归档,供其他应用复用。
整体编译流水线如下:
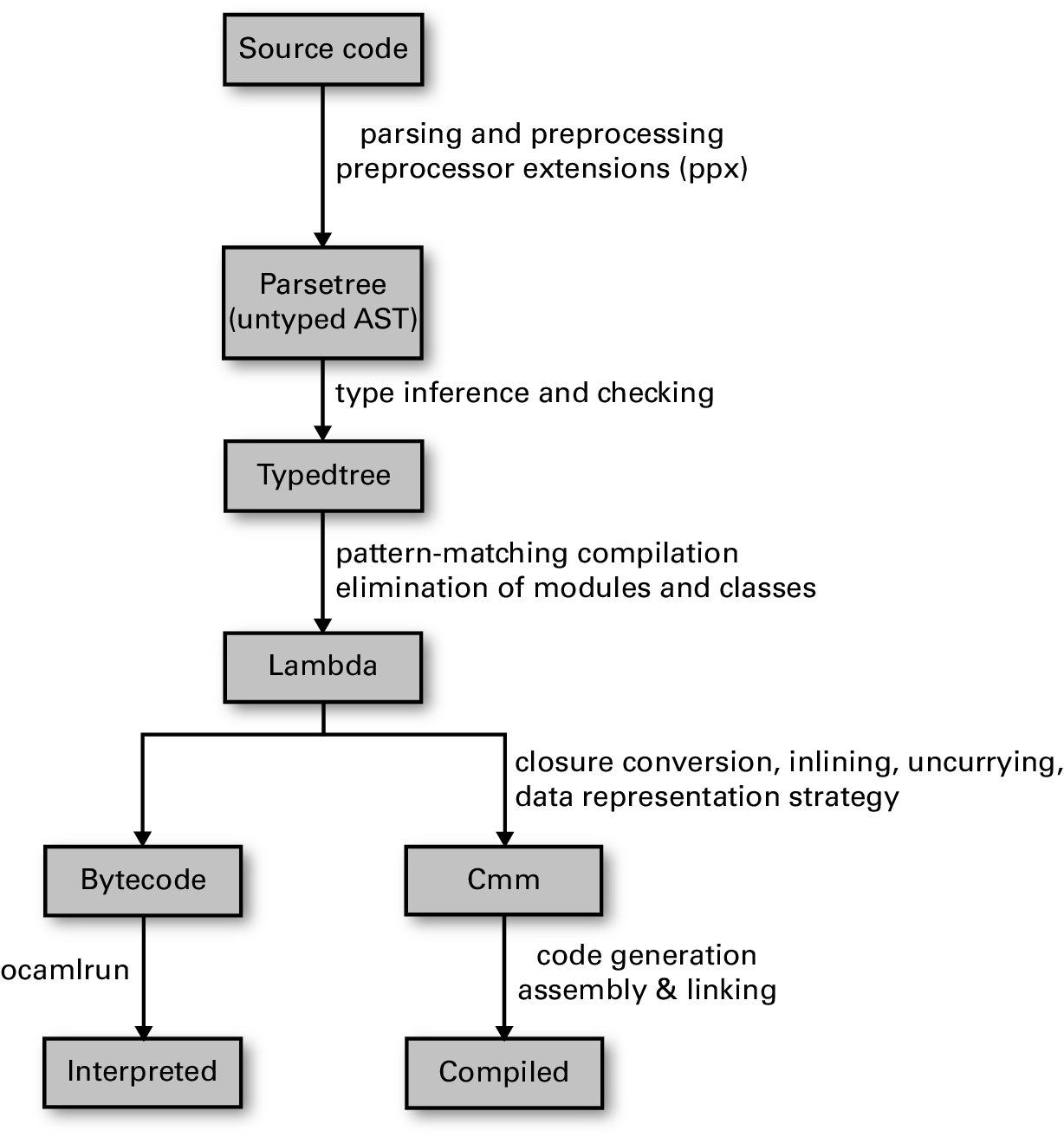
注意,流水线接近末尾时会分叉。OCaml 有多个编译器后端,它们复用编译早期阶段,但生成非常不同的最终输出。字节码(bytecode)可以由可移植解释器运行,甚至可以被转换成 JavaScript(通过 js_of_ocaml)或 C 源代码(通过 OCamlCC)。原生代码(native code)编译器则生成专门的可执行二进制文件,适合高性能应用。
26.1.1 获取编译器源代码(Obtaining the Compiler Source Code)
理解本章示例并不要求你拥有 OCaml 源码树,但阅读本章时,把源码检出到本地可能很有帮助。源代码可以从多个地方获得:
- 稳定发布版,可以从 OCaml 下载站点获取
zip和tar归档。 - 包含完整历史和开发分支的 Git 仓库,可以在 GitHub 在线浏览。
源码树被拆分为多个子目录。核心编译器包含:
asmcomp/:原生代码编译器,把 OCaml 转换为高性能原生代码可执行文件。bytecomp/:字节码编译器,把 OCaml 转换为解释执行格式。driver/:编译器工具的命令行接口。file_formats/:编译器驱动使用的磁盘文件序列化器与反序列化器。lambda/:lambda 转换 pass。middle_end/:clambda、closure 和 flambda pass。parsing/:OCaml 词法分析器、解析器,以及用于操作它们的库。runtime/:带垃圾回收器的运行时库。typing/:静态类型检查实现与类型定义。
还有一些工具与脚本会和核心编译器一起构建:
debugger/:交互式字节码调试器。toplevel/:交互式顶层控制台。stdlib/:编译器标准库,包括Pervasives模块。otherlibs/:可选库,例如 Unix 与 graphics 模块。tools/:随编译器安装的命令行工具,例如ocamldep。testsuite/:核心编译器的回归测试。
接下来我们会逐一走过各个编译阶段,并解释它们在日常 OCaml 开发中为什么有用。
26.2 解析源代码(Parsing Source Code)
当源文件传给 OCaml 编译器时,编译器的第一项任务是把文本解析成结构化程度更高的抽象语法树(AST)。解析逻辑本身用 OCaml 实现,并使用了第 20 章“使用 OCamllex 与 Menhir 解析”中介绍过的技术。词法分析器和解析器规则可以在源码发行版的 parsing 目录中找到。
26.2.1 语法错误(Syntax Errors)
OCaml 解析器的目标,是向下一阶段编译输出一个格式良好的 AST 数据结构。因此,任何不满足基本语法要求的源代码都会导致它失败。这种情况下,编译器会发出语法错误(syntax error),并尽可能接近错误位置地指出文件名、行号和字符编号。
下面是一个语法错误示例:我们把模块赋值写成了语句,而不是 let 绑定。
let () =
module MyString = String;
()
编译时,这段代码会导致语法错误:
$ ocamlc -c broken_module.ml
File "broken_module.ml", line 2, characters 2-8:
2 | module MyString = String;
^^^^^^
Error: Syntax error
[2]
这个源代码的正确版本会通过局部模块绑定创建 MyString 模块,并能成功编译:
let () =
let module MyString = String in
()
语法错误会指向第一个无法被解析的 token 所在的行号和字符编号。在这个错误示例中,module 关键字在解析当前位置不是合法 token,因此错误位置信息是准确的。
26.2.2 从接口生成文档(Generating Documentation from Interfaces)
空白和源代码注释会在解析期间被移除,并且不会影响程序语义。不过,OCaml 发行版中的其他工具可以为了自己的目的解释注释。
OCaml 使用源代码中特殊格式的注释来生成文档包。这些注释会与函数定义和签名结合,并以各种格式输出为结构化文档。odoc 和 ocamldoc 这类工具可以生成 HTML 页面、LaTeX 和 PDF 文档、UNIX 手册页,甚至还能生成可用 Graphviz 查看器查看的模块依赖图。
下面是一段用 docstring 注释做过标注的源代码示例:
(** The first special comment of the file is the comment associated
with the whole module. *)
(** Comment for exception My_exception. *)
exception My_exception of (int -> int) * int
(** Comment for type [weather] *)
type weather =
| Rain of int (** The comment for constructor Rain *)
| Sun (** The comment for constructor Sun *)
(** Find the current weather for a country
@author Anil Madhavapeddy
@param location The country to get the weather for.
*)
let what_is_the_weather_in location =
match location with
| `Cambridge -> Rain 100
| `New_york -> Rain 20
| `California -> Sun
docstring 以双星号开头,借此与普通注释区分。注释内容也有一些格式约定,用于标记元数据。例如,@tag 字段会标记特定属性,比如这一段代码的作者。
操作 docstring 注释主要有两个工具:编译器附带的 ocamldoc,以及在编译器外部开发、但目标是长期替代它的 odoc。可以尝试对上面的源文件运行 ocamldoc,来编译 HTML 文档和 UNIX 手册页:
$ mkdir -p html man/man3
$ ocamldoc -html -d html doc.ml
$ ocamldoc -man -d man/man3 doc.ml
$ man -M man Doc
现在,html/ 目录中应该已经有了 HTML 文件,也可以查看 man/man3 中保存的 UNIX 手册页。注释格式有很多种,也有许多用于控制不同后端输出的选项。完整列表可以参考 OCaml 手册。
你也可以通过与 dune 集成来使用 odoc 生成项目的完整快照,这一点已经在第 22 章“OCaml 平台”中介绍过。
26.3 使用 ppx 预处理(Preprocessing with ppx)
OCaml 的一个强大特性,是可以通过扩展点(extension point)来扩展标准语言。扩展点表示 OCaml 语法树中的占位符;除分隔并存储在抽象语法树中之外,标准编译器工具会忽略它们。它们本意是交给外部工具展开,由这些工具选择自己能够解释的扩展节点。外部工具可以通过转换输入语法树来生成更多 OCaml 代码,从而形成语言的可扩展预处理器基础。
OCaml 中的扩展点主要有两种形式:属性(attribute)和扩展节点(extension node)。先看一些例子了解它们长什么样,然后再看如何在自己的代码中使用它们。
26.3.1 扩展属性(Extension Attributes)
属性会为 OCaml 语法树中的某个节点附加额外信息,随后由外部工具解释并展开。
属性的基本形式是 [@ ... ] 语法。@ 符号的数量定义了属性绑定到语法树的哪个部分:
- 单个
[@使用后缀记法绑定到表达式、类型定义中的单个构造器等代数类别。 - 两个
[@@绑定到代码块,例如模块定义、类型声明或类字段。 - 三个
[@@@作为模块实现或签名中的独立条目出现,不绑定到任何特定源代码节点。
OCaml 编译器内置了一些有用属性,可以在不依赖任何外部工具的情况下说明属性的用法。先看独立属性 @@@warning 的用法,它可以切换 OCaml 编译器警告。
# module Abc = struct
[@@@warning "+non-unit-statement"]
let a = Sys.get_argv (); ()
[@@@warning "-non-unit-statement"]
let b = Sys.get_argv (); ()
end;;
Line 4, characters 11-26:
Warning 10 [non-unit-statement]: this expression should have type unit.
module Abc : sig val a : unit val b : unit end
示例中的警告来自编译器手册页。如果序列表达式中的某个表达式类型不是 unit,这个警告就会发出消息。模块实现中的 @@@warning 节点会让编译器只在这个结构的作用域内改变行为。
注解也可以更窄地附加到一块代码上。例如,可以用 @@deprecated 注解模块实现,表示新代码不应再使用它:
# module Planets = struct
let earth = true
let pluto = true
end [@@deprecated "Sorry, Pluto is no longer a planet. Use the Planets2016 module instead."];;
module Planets : sig val earth : bool val pluto : bool end
# module Planets2016 = struct
let earth = true
let pluto = false
end;;
module Planets2016 : sig val earth : bool val pluto : bool end
在这个例子中,@@deprecated 注解只附加到 Planets 模块上,而人类可读的参数字符串会把开发者引导到更新的代码。现在,如果尝试使用已经标记为 deprecated 的值,编译器就会发出警告。
# let is_pluto_a_planet = Planets.pluto;;
Line 1, characters 25-38:
Alert deprecated: module Planets
Sorry, Pluto is no longer a planet. Use the Planets2016 module instead.
val is_pluto_a_planet : bool = true
# let is_pluto_a_planet = Planets2016.pluto;;
val is_pluto_a_planet : bool = false
最后,属性还可以附加到单个表达式上。下一个例子中,@warn_on_literal_pattern 属性表示,不应该用常量字面量对该类型构造器的参数做模式匹配。
# type program_result =
| Error of string [@warn_on_literal_pattern]
| Exit_code of int;;
type program_result = Error of string | Exit_code of int
# let exit_with = function
| Error "It blew up" -> 1
| Exit_code code -> code
| Error _ -> 100;;
Line 2, characters 11-23:
Warning 52 [fragile-literal-pattern]: Code should not depend on the actual values of
this constructor's arguments. They are only for information
and may change in future versions. (See manual section 11.5)
val exit_with : program_result -> int = <fun>
26.3.2 常用扩展属性(Commonly Used Extension Attributes)
我们已经在第 21 章“使用 S 表达式进行数据序列化”中使用过扩展点,用它生成处理 S 表达式的样板代码。这些扩展点由第三方库引入,并通过 dune 文件中的 (preprocess) 指令启用,例如:
(library
(name hello_world)
(libraries core)
(preprocess (pps ppx_jane))
这样就能利用社区提供的语法增强能力。核心 OCaml 编译器中也有一些内置属性。有些面向性能,会向编译器提供指令;有些则会激活用法警告。完整列表可以在 OCaml 手册的属性章节中找到。
26.3.3 扩展节点(Extension Nodes)
扩展点很适合为既有源代码添加注解,但我们还需要一种机制,在 OCaml AST 中保存用于代码生成的通用占位符。OCaml 通过扩展节点语法提供了这种能力。
扩展节点的一般语法是 [%id expr],其中 id 是某个扩展节点重写器的标识符,expr 是供重写器解析的载荷。如果载荷属于同一种语法,也可以使用中缀形式。例如,let%foo bar = 1 等价于 [%foo let bar = 1]。
本书前面已经通过 Core 语法扩展见过扩展节点,它们充当错误处理(let%bind)、命令行解析(let%map)或内联测试(let%expect_test)的语法糖。扩展节点与扩展属性一样,通过 dune 规则中的 (preprocess) 属性引入。
26.4 静态类型检查(Static Type Checking)
得到有效的抽象语法树之后,编译器必须验证代码是否遵守 OCaml 类型系统规则。语法正确但错误使用值的代码会被拒绝,并附带对问题的解释。
虽然 OCaml 的类型检查以单趟完成,但它实际上由三个同时发生的不同步骤组成:
- 自动类型推断(automatic type inference):在不要求手写类型注解的情况下,为模块计算类型的算法。
- 模块系统(module system):用对类型签名的显式知识组合软件组件。
- 显式子类型化(explicit subtyping):检查对象与多态变体。
自动类型推断让你可以为某个任务编写简洁代码,并让编译器保证你对变量的使用在局部一致。
类型推断无法很好扩展到依赖文件分离编译的大型代码库。某个模块中的小改动可能向数千个其他文件和库传播,并要求它们全部重新编译。模块系统通过提供在大型项目中组合和操作显式模块类型签名的能力解决了这个问题,也让这些模块可以通过函子和一等模块复用。
OCaml 对象中的子类型化始终是显式操作(通过 :> 运算符)。这意味着它不会让核心类型推断引擎变得复杂,并且可以作为单独关注点来测试。
26.4.1 显示编译器推断出的类型(Displaying Inferred Types from the Compiler)
我们已经看到,可以直接通过顶层环境探索类型推断。也可以要求编译器为整个文件生成类型签名。创建一个只包含单个类型定义和值的文件:
type t = Foo | Bar
let v = Foo
现在使用 -i 标志运行编译器,为该文件推断类型签名。这会运行类型检查器,但在把接口显示到标准输出之后,不再继续编译代码:
$ ocamlc -i typedef.ml
type t = Foo | Bar
val v : t
这个输出就是表示输入文件的模块的默认签名。把该输出重定向到 mli 文件通常很有用,它能给你一个起始签名,随后你可以编辑外部接口,而无需手工完整输入。
编译器会把接口的已编译版本存储为 cmi 文件。这个接口要么来自模块的 mli 签名文件编译结果,要么来自只有 ml 实现文件时推断出的类型。
编译器会确保 ml 和 mli 文件拥有兼容签名。如果不是这样,类型检查器会立刻抛出错误。例如,如果你的 ml 文件如下:
type t = Foo
而 mli 文件如下:
type t = Bar
那么,尝试构建时会得到这个错误:
$ ocamlc -c conflicting_interface.mli conflicting_interface.ml
File "conflicting_interface.ml", line 1:
Error: The implementation conflicting_interface.ml
does not match the interface conflicting_interface.cmi:
Type declarations do not match:
type t = Foo
is not included in
type t = Bar
Constructors have different names, Foo and Bar.
File "conflicting_interface.mli", line 1, characters 0-12:
Expected declaration
File "conflicting_interface.ml", line 1, characters 0-12:
Actual declaration
[2]
先写 ml 还是 mli?(Which Comes First: The ml or the mli?)
关于 OCaml 代码应该按什么顺序编写,有两种思路。先从 ml 文件开始写代码,并在构建函数时用类型推断来引导自己,是非常容易上手的方式。随后可以像前面描述的那样生成 mli 文件,并为导出的函数补充文档。
如果代码跨越多个文件,有时先写好所有 mli 签名,并检查它们彼此之间能通过类型检查,会更容易。签名就位后,就可以带着这些模块最终能正确粘合起来、且模块之间不存在循环依赖的信心去编写实现。
和所有这类风格争论一样,你应该自己试验哪种方式最适合。只有一点大家都同意:无论按什么顺序编写,生产代码都应该为项目中的每个 ml 文件显式定义一个 mli 文件。如果只是声明签名(例如模块类型),有 mli 文件而没有对应的 ml 文件也完全可以。
签名文件提供了一个书写简洁文档、并抽象掉不应导出的内部细节的位置。维护独立签名文件也能加快大型代码库中的增量编译,因为重新编译 mli 签名比把实现完整编译为原生代码快得多。
26.4.2 类型推断(Type Inference)
类型推断是根据表达式的用法确定合适类型的过程。许多其他语言,例如 Haskell 和 Scala,也部分具备这一特性,但 OCaml 把它作为核心语言中的基础特性贯穿使用。
OCaml 类型推断基于 Hindley-Milner 算法。该算法值得注意的地方在于,它能够在不要求任何显式类型注解的情况下,为表达式推断出最一般的类型。算法可以为表达式推导出多个类型,并拥有主类型(principal type)的概念,也就是所有可能推断结果中最一般的选择。手动类型注解可以显式地把类型特化,但自动推断会在没有额外要求时选择最一般的类型。
OCaml 的确有一些语言扩展会挑战主类型推断的边界,但总体而言,你编写的大多数程序永远都不会要求注解(尽管注解有时会帮助编译器产生更好的错误消息)。
添加类型注解来定位错误(Adding Type Annotations to Find Errors)
人们常说,写 OCaml 代码最困难的部分是通过类型检查器,但一旦代码确实编译通过,它第一次运行就会正确。当然,这种说法有些夸张,但如果从动态类型语言转来,它确实可能让人感觉真实。OCaml 静态类型系统会在编译期拒绝程序,而不是在运行时产生错误,从而保护你免受某些类别 bug 的影响,例如内存错误和抽象违规。学会解读类型检查器的编译期反馈,是构建健壮库和应用的关键,能让你充分利用这些静态检查。
有几个技巧可以让你更容易快速定位代码中的类型错误。第一个技巧是引入手动类型注解,以便更准确地缩小错误来源范围。这些注解不应该实际改变类型,而且在代码正确后可以移除。不过,在仍在编写代码时,它们可以作为锚点帮助定位错误。
如果大量使用多态变体或对象,手动类型注解尤其有用。带行多态(row polymorphism)的类型推断可能生成非常大的签名,而且相比使用更显式类型化的变体或类,错误往往会传播得更远。
例如,考虑下面这个有问题的例子,它在整数上表达一些简单代数运算:
let rec algebra =
function
| `Add (x,y) -> (algebra x) + (algebra y)
| `Sub (x,y) -> (algebra x) - (algebra y)
| `Mul (x,y) -> (algebra x) * (algebra y)
| `Num x -> x
let _ =
algebra (
`Add (
(`Num 0),
(`Sub (
(`Num 1),
(`Mul (
(`Nu 3),(`Num 2)
))
))
))
代码里有一个单字符拼写错误,使用了 Nu 而不是 Num。由此产生的类型错误相当壮观:
$ ocamlc -c broken_poly.ml
File "broken_poly.ml", lines 9-18, characters 10-6:
9 | ..........(
10 | `Add (
11 | (`Num 0),
12 | (`Sub (
13 | (`Num 1),
14 | (`Mul (
15 | (`Nu 3),(`Num 2)
16 | ))
17 | ))
18 | ))
Error: This expression has type
[> `Add of
([< `Add of 'a * 'a
| `Mul of 'a * 'a
| `Num of int
| `Sub of 'a * 'a
> `Num ]
as 'a) *
[> `Sub of 'a * [> `Mul of [> `Nu of int ] * [> `Num of int ] ]
] ]
but an expression was expected of type
[< `Add of 'a * 'a | `Mul of 'a * 'a | `Num of int | `Sub of 'a * 'a
> `Num ]
as 'a
The second variant type does not allow tag(s) `Nu
[2]
这个类型错误完全准确,但相当冗长,而且行号并没有指向错误变体名的确切位置。编译器能做的最好事情,是大致指向 algebra 函数应用所在区域。
原因是,类型检查器没有足够信息,把 algebra 定义的推断类型和几行之后的应用匹配起来。它会分别为两个表达式计算类型;当两者不匹配时,再尽力输出差异。
用显式类型注解帮助编译器之后,看看会发生什么:
type t = [
| `Add of t * t
| `Sub of t * t
| `Mul of t * t
| `Num of int
]
let rec algebra (x:t) =
match x with
| `Add (x,y) -> (algebra x) + (algebra y)
| `Sub (x,y) -> (algebra x) - (algebra y)
| `Mul (x,y) -> (algebra x) * (algebra y)
| `Num x -> x
let _ =
algebra (
`Add (
(`Num 0),
(`Sub (
(`Num 1),
(`Mul (
(`Nu 3),(`Num 2)
))
))
))
这段代码包含和之前完全一样的错误,但我们添加了一个多态变体的封闭类型定义,并给 algebra 定义添加了类型注解。现在得到的编译器错误有用得多:
$ ocamlc -i broken_poly_with_annot.ml
File "broken_poly_with_annot.ml", line 22, characters 14-21:
22 | (`Nu 3),(`Num 2)
^^^^^^^
Error: This expression has type [> `Nu of int ]
but an expression was expected of type t
The second variant type does not allow tag(s) `Nu
[2]
这个错误会直接指向包含拼写错误的正确行号。修复问题之后,如果更喜欢简洁代码,可以移除手动注解。当然,也可以把注解留在那里,以便未来重构和调试。
强制主类型检查(Enforcing Principal Typing)
编译器还有一种更严格的主类型检查(principal type checking)模式,可以通过 -principal 标志激活。它会针对有风险的类型信息使用方式发出警告,以确保类型推断只有一个主结果。如果类型推断的成功或失败取决于对子表达式进行类型化的顺序,那么这个类型就被认为是有风险的。
主类型检查只影响少数语言特性:
- 对象的多态方法。
- 按不同于函数类型定义的顺序排列带标签参数。
- 丢弃可选带标签参数。
- OCaml 4.0 以来提供的广义代数数据类型(GADT)。
- 记录字段和构造器名称的自动消歧(自 OCaml 4.1 起)。
下面是主类型检查与记录消歧一起使用时出现警告的例子。
type s = { foo: int; bar: unit }
type t = { foo: int }
let f x =
x.bar;
x.foo
用 -principal 推断签名,会显示一个新警告:
$ ocamlc -i -principal non_principal.ml
File "non_principal.ml", line 6, characters 4-7:
6 | x.foo
^^^
Warning 18 [not-principal]: this type-based field disambiguation is not principal.
type s = { foo : int; bar : unit; }
type t = { foo : int; }
val f : s -> int
这个例子不是 principal 的,因为 x.foo 的推断类型受 x.bar 的推断类型引导;而主类型化要求每个子表达式的类型都能独立计算。如果从 f 的定义中移除 x.bar 的使用,那么它的参数会是 t 类型,而不是 s 类型。
可以通过调换类型声明顺序,或者添加显式类型注解来修复这个问题:
type s = { foo: int; bar: unit }
type t = { foo: int }
let f (x:s) =
x.bar;
x.foo
现在,推断出的类型不存在歧义,因为我们已经显式给出了参数类型,而且子表达式的推断顺序不再重要。
$ ocamlc -i -principal principal.ml
type s = { foo : int; bar : unit; }
type t = { foo : int; }
val f : s -> int
dune 中的等价做法,是在构建描述中添加 -principal 标志。
(executable
(name principal)
(flags :standard -principal)
(modules principal))
(executable
(name non_principal)
(flags :standard -principal)
(modules non_principal))
:standard 指令会包含所有默认标志,然后把 -principal 追加到编译器构建标志之后。
$ dune build principal.exe
$ dune build non_principal.exe
File "non_principal.ml", line 6, characters 4-7:
6 | x.foo
^^^
Error (warning 18 [not-principal]): this type-based field disambiguation is not principal.
[1]
理想情况下,所有代码都应该系统性使用 -principal。它能降低类型推断中的变化性,并强制只有一个已知类型的概念。不过,这种模式也有缺点:类型推断会变慢,cmi 文件会变大。只有在大量使用对象时,这通常才会成为问题,因为对象通常有更大的类型签名来覆盖所有方法。
如果程序能在 principal 模式下编译,那么它也保证能在非 principal 模式下通过类型检查。不过要记住,在 principal 模式下生成的 cmi 文件与默认模式不同。尽量确保整个项目都在激活该模式的情况下编译。混用这些文件不会让你违反类型安全,但非常偶尔地会导致类型检查器意外失败。遇到这种情况时,只需从干净的源码树重新编译即可。
26.4.3 模块与分离编译(Modules and Separate Compilation)
OCaml 模块系统让较小组件可以在大型项目中有效复用,同时仍然保留静态类型安全的全部好处。我们已经在第 5 章“文件、模块与程序”中介绍过模块使用基础。操作这些签名的模块语言也扩展到了函子和一等模块,它们分别在第 11 章“函子”和第 12 章“一等模块”中介绍过。
本节会更详细地讨论编译器如何实现它们。模块对于包含许多源文件的大型项目至关重要,这些源文件也称为编译单元。只改动一两个文件时,重新编译每个源文件并不实际;模块系统会最小化这类重新编译,同时仍然鼓励代码复用。
文件与模块之间的映射(The Mapping Between Files and Modules)
单个编译单元提供了一种方便方式,可以把大型模块层次拆分为一组文件。文件与模块之间的关系可以直接用模块系统来解释。
创建一个名为 alice.ml 的文件,内容如下:
let friends = [ Bob.name ]
以及对应的签名文件:
val friends : Bob.t list
这两个文件产生的结果,本质上等同于下面的代码。
module Alice : sig
val friends : Bob.t list
end = struct
let friends = [ Bob.name ]
end
定义模块搜索路径(Defining a Module Search Path)
在前面的例子中,Alice 还引用了另一个模块 Bob。为了让 Alice 的整体类型有效,编译器还需要检查 Bob 模块至少包含一个 Bob.name 值,并定义一个 Bob.t 类型。
类型检查器会把这类模块引用解析为具体结构和签名,以便跨模块边界统一类型。它通过搜索一组目录来完成这件事,寻找匹配模块名的已编译接口文件。例如,它会在搜索路径中查找 alice.cmi 和 bob.cmi,并使用遇到的第一个文件作为 Alice 和 Bob 的接口。
模块搜索路径通过在编译器命令行上添加 -I 标志来设置,其参数是包含 cmi 文件的目录。当有许多库时,手动指定这些标志会变得复杂,这正是 dune 和 ocamlfind 这类工具存在的原因。它们都会自动把第三方包名和构建描述转换为传给编译器命令行的标志。
默认情况下,编译器只会在当前目录和 OCaml 标准库中搜索 cmi 文件。标准库中的 Stdlib 模块也会在每个编译单元中默认打开。标准库位置可以通过运行 ocamlc -where 获得,并且可以通过设置 CAMLLIB 环境变量覆盖。不用说,除非有充分理由,例如设置交叉编译环境,否则不应覆盖默认路径。
使用 ocamlobjinfo 检查编译单元(Inspecting Compilation Units with ocamlobjinfo)
为了让分离编译保持可靠,需要确保用于对模块进行类型检查的所有 cmi 文件在不同编译运行中都是相同的。如果它们发生变化,就有可能让两个模块针对同名公共模块检查出不同类型签名。这又会让程序完全违反静态类型系统,并可能导致内存损坏和崩溃。
OCaml 会通过在每个 cmi 中记录一个 MD5 校验和来防止这种情况。更仔细地检查前面的 typedef.ml:
$ ocamlc -c typedef.ml
$ ocamlobjinfo typedef.cmi
File typedef.cmi
Unit name: Typedef
Interfaces imported:
cdd43318ee9dd1b187513a4341737717 Typedef
9b04ecdc97e5102c1d342892ef7ad9a2 Pervasives
79ae8c0eb753af6b441fe05456c7970b CamlinternalFormatBasics
ocamlobjinfo 会检查已编译接口,并显示它依赖的其他编译单元。在这里,除了 Pervasives 之外,我们没有使用任何外部模块。默认情况下,每个模块都依赖 Pervasives,除非使用 -nopervasives 标志(这是高级用法,通常不需要)。
每个模块名旁边的长字母数字标识符,是根据该编译单元导出的所有类型和值计算出的哈希。它在类型检查和链接期间用于确保所有编译单元都以彼此一致的方式编译。哈希不同意味着,同名编译单元在不同模块中可能拥有冲突的类型签名。编译器会用类似下面的错误拒绝这类程序:
$ ocamlc -c foo.ml
File "foo.ml", line 1, characters 0-1:
Error: The files /home/build/bar.cmi
and /usr/lib/ocaml/map.cmi make inconsistent assumptions
over interface Map
这个哈希检查非常保守,但能确保分离编译直到最终链接阶段都保持类型安全。你的构建系统应该确保你永远不会看到前面的错误消息;如果真的遇到,只需清理中间文件并从头重新编译即可。
26.4.4 用模块别名包装库(Wrapping Libraries with Module Aliases)
目前描述的模块到文件映射,会严格强制顶层模块和文件之间的 1:1 映射。把较大的模块拆成独立文件通常很方便,因为这样更容易编辑;但仍然把它们全部编译进一个 OCaml 模块也很方便。
Dune 为库提供了一种非常方便的方式:自动生成一个顶层模块别名(module alias)文件,把某个库中的所有文件作为该库顶层模块的子模块。这称为包装(wrapping)库,工作方式如下。
先定义一个简单库,它包含两个文件 a.ml 和 b.ml,每个文件都定义一个值。
let v = "hello"
let w = 42
dune 文件定义一个名为 hello 的库,其中包含这两个模块。
(library
(name hello)
(modules a b))
(executable
(name test)
(libraries hello)
(modules test))
现在构建这个库后,可以看看 dune 如何把模块组装成 Hello 库。
$ dune build
$ cat _build/default/hello.ml-gen
(** @canonical Hello.A *)
module A = Hello__A
(** @canonical Hello.B *)
module B = Hello__B
Dune 生成了一个 hello.ml 文件,它构成库暴露出的顶层模块。它还把单个模块重命名为内部混淆名称,例如 Hello__A,并在生成的 hello.ml 文件中把这些内部模块赋值为别名。这样,库的用户就可以通过 Hello.A 访问值。例如,测试可执行文件包含:
let v = Hello.A.v
let w = Hello.B.w
这种模块别名方案的一个好处是,单个顶层模块提供了一个集中位置,可以书写关于如何使用库暴露的所有子模块的文档。可以手动向库中添加 hello.ml 和 hello.mli 来完成这件事。先把 hello 模块添加到 dune 文件中:
(library
(name hello)
(modules a b hello))
(executable
(name test)
(libraries hello)
(modules test))
然后,hello.ml 文件包含模块别名(以及你可能想放入顶层模块的任何其他代码)。
module A = A
module B = B
最后,hello.mli 接口文件可以引用所有子模块,并包含文档字符串:
(** Documentation for module A *)
module A : sig
(** [v] is Hello *)
val v : string
end
(** Documentation for module B *)
module B : sig
(** [w] is 42 *)
val w : int
end
如果想禁用 dune 的这种行为,并有意包含多个顶层模块,可以在库 stanza 中添加 (wrapped false)。不过,通常不鼓励这样做,因为当库依赖很多时,链接冲突的可能性会增加:在 OCaml 中,链接到可执行文件中的每个模块都必须拥有唯一名称。
26.4.5 类型错误中的更短模块路径(Shorter Module Paths in Type Errors)
Core 大量使用 OCaml 模块系统来提供完整的替代标准库。它把这些模块收集到单个 Std 模块中,而导入替代模块和函数时只需打开这一个模块。
这种做法有一个缺点:类型错误会突然变得冗长得多。运行普通 OCaml 顶层环境(不是 utop)就能看到这一点。
$ ocaml
# List.map print_endline "";;
Error: This expression has type string but an expression was expected of type
string list
不使用 Core 时,这个类型错误很直接。但切换到 Core 之后,它会变得更冗长:
$ ocaml
# open Core;;
# List.map ~f:print_endline "";;
Error: This expression has type string but an expression was expected of type
'a Core.List.t = 'a list
OCaml 默认的 List 模块被 Core.List 覆盖了。编译器会尽力显示类型等价关系,但代价是错误消息更啰嗦。
编译器可以通过所谓的 short paths 启发式来改善这一点。它会让编译器搜索所有类型别名,找到最短模块路径,并把它用作首选输出类型。把 -short-paths 传给编译器即可激活这个选项,它也能用于顶层环境。
$ ocaml -short-paths
# open Core;;
# List.map ~f:print_endline "foo";;
Error: This expression has type string but an expression was expected of type
'a list
增强版顶层环境 utop 默认激活 short paths,这就是我们之前在交互示例中不需要这么做的原因。不过,编译器默认不会启用 short paths 启发式,因为在某些情况下,类型别名信息本身很有用;如果总是选择最短模块路径,错误消息中就会丢失这些信息。
在自己的项目中,需要自行选择更偏好 short paths 还是默认行为。如果需要这个行为,就把 -short-paths 标志传给编译器。
26.5 类型化语法树(The Typed Syntax Tree)
类型检查过程成功完成后,它会与 AST 结合,形成类型化抽象语法树(typed abstract syntax tree)。它包含输入文件中每个 token 的精确位置信息,并用具体类型信息装饰每个 token。
编译器可以把它输出为已编译的 cmt 和 cmti 文件,其中分别包含某个编译单元实现和签名的类型化 AST。把 -bin-annot 标志传给编译器即可激活这一点。
cmt 文件对 IDE 工具尤其有用,可以把 OCaml 源代码中的特定位置匹配到推断类型或外部类型。例如,merlin 和 ocaml-lsp-server opam 包都会使用这些信息,在编辑器中为你提供工具提示和 docstring,这一点已经在第 22 章“OCaml 平台”中介绍过。
26.5.1 直接检查类型化语法树(Examining the Typed Syntax Tree Directly)
编译器有几个高级标志,可以倾倒内部 AST 表示的原始输出。不能依赖这些标志在不同编译器版本之间给出相同输出,但它们是有用的学习工具。
我们再次使用玩具示例 typedef.ml:
type t = Foo | Bar
let v = Foo
先看看解析阶段生成的未类型化语法树:
$ ocamlc -dparsetree typedef.ml 2>&1
[
structure_item (typedef.ml[1,0+0]..[1,0+18])
Pstr_type Rec
[
type_declaration "t" (typedef.ml[1,0+5]..[1,0+6]) (typedef.ml[1,0+0]..[1,0+18])
ptype_params =
[]
ptype_cstrs =
[]
ptype_kind =
Ptype_variant
[
(typedef.ml[1,0+9]..[1,0+12])
"Foo" (typedef.ml[1,0+9]..[1,0+12])
[]
None
(typedef.ml[1,0+13]..[1,0+18])
"Bar" (typedef.ml[1,0+15]..[1,0+18])
[]
None
]
ptype_private = Public
ptype_manifest =
None
]
structure_item (typedef.ml[2,19+0]..[2,19+11])
Pstr_value Nonrec
[
<def>
pattern (typedef.ml[2,19+4]..[2,19+5])
Ppat_var "v" (typedef.ml[2,19+4]..[2,19+5])
expression (typedef.ml[2,19+8]..[2,19+11])
Pexp_construct "Foo" (typedef.ml[2,19+8]..[2,19+11])
None
]
]
对一个只有两行的简单程序来说,这已经是相当多的输出,但它也展示了即使从很小的源文件中,OCaml 解析器也会生成多少结构。
AST 的每一部分都带有精确位置信息,包括文件名和 token 的字符位置。这段代码还没有进行类型检查,因此原始 token 都包含在其中。
通常作为已编译 cmt 文件输出的类型化 AST,可以通过 -dtypedtree 选项以更适合开发者阅读的形式显示:
$ ocamlc -dtypedtree typedef.ml 2>&1
[
structure_item (typedef.ml[1,0+0]..typedef.ml[1,0+18])
Tstr_type Rec
[
type_declaration t/267 (typedef.ml[1,0+0]..typedef.ml[1,0+18])
ptype_params =
[]
ptype_cstrs =
[]
ptype_kind =
Ttype_variant
[
(typedef.ml[1,0+9]..typedef.ml[1,0+12])
Foo/268
[]
None
(typedef.ml[1,0+13]..typedef.ml[1,0+18])
Bar/269
[]
None
]
ptype_private = Public
ptype_manifest =
None
]
structure_item (typedef.ml[2,19+0]..typedef.ml[2,19+11])
Tstr_value Nonrec
[
<def>
pattern (typedef.ml[2,19+4]..typedef.ml[2,19+5])
Tpat_var "v/270"
expression (typedef.ml[2,19+8]..typedef.ml[2,19+11])
Texp_construct "Foo"
[]
]
]
类型化 AST 比未类型化语法树更加显式。例如,类型声明已经获得一个唯一名称(t/1008),v 值也一样(v/1011)。
除非正在构建 IDE 工具,或者正在修改核心编译器自身的扩展,否则通常很少需要查看来自编译器的这类原始输出。不过,在我们下一章继续深入代码生成过程之前,知道这种中间形式存在仍然很有用。
现在有几种新的集成工具正在出现,它们会把这些类型化 AST 文件与 Emacs 或 Vim 这类常见编辑器结合起来。其中最好的工具是 Merlin,它会添加值和模块自动补全,显示推断类型,并能直接在编辑器内部构建和显示错误。它的主页上提供了为常用编辑器配置 Merlin 的说明;它的更大兄弟 ocaml-lsp-server 已经在第 22 章“OCaml 平台”中介绍过。