第 9 章:函数类型(Function Types)
原文:Bartosz Milewski, Category Theory for Programmers, Scala Edition, Chapter 9. 原书 PDF、
.tex源文件及相关图像采用 CC BY-SA 4.0;本译文按同一许可发布。
到目前为止,我一直略过函数类型的含义。函数类型不同于其他类型。
以 Integer 为例:它只是整数的集合。Bool 是一个双元素集合。但函数类型 a -> b 不只是这样:它是对象 a 和 b 之间态射的集合。在任意范畴中,两个对象之间的态射集合称为 hom-set。碰巧在范畴 $Set$ 中,每个 hom-set 本身也是同一个范畴中的对象,因为归根结底,它也是一个集合。
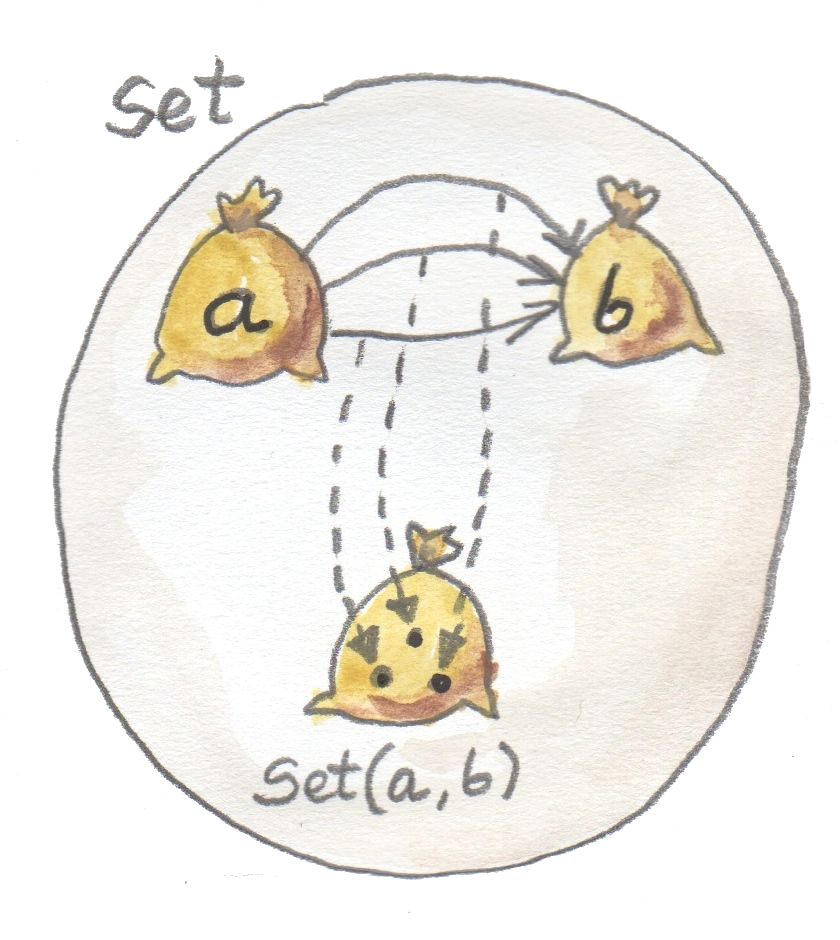
其他范畴并不一定如此,在那些范畴中,hom-set 位于范畴之外。它们甚至被称为外部 hom-set。
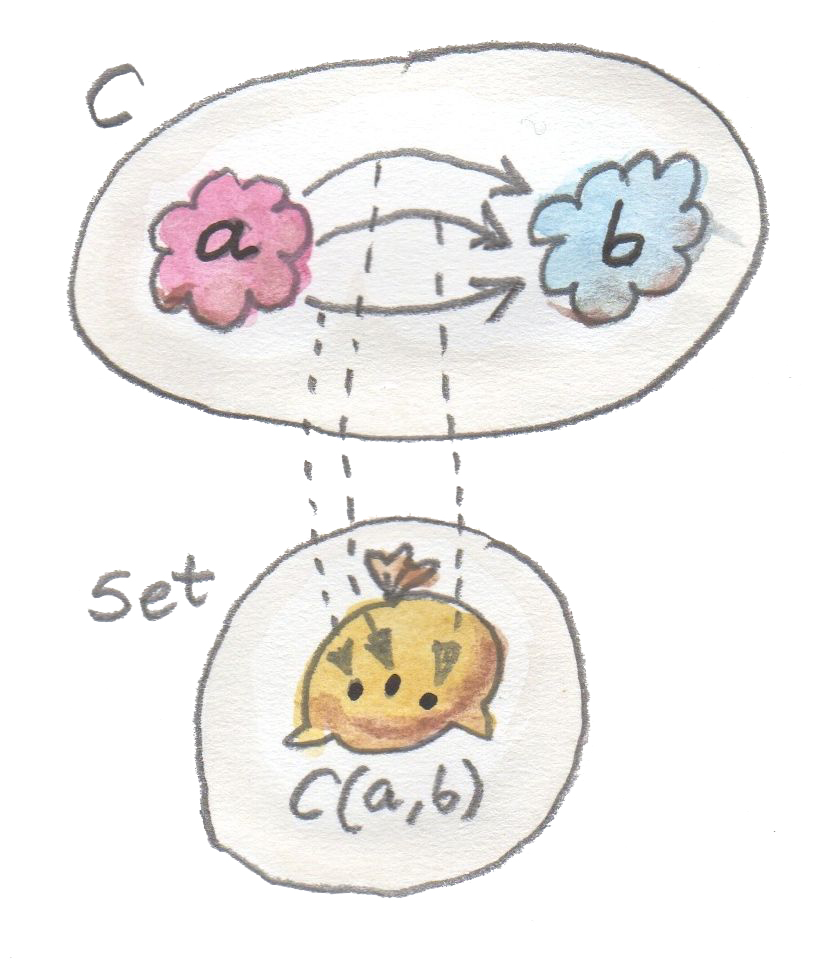
正是范畴 $Set$ 的这种自指性质,让函数类型变得特殊。不过,至少在某些范畴中,可以构造表示 hom-set 的对象。这样的对象称为内部 hom-set。
9.1 通用构造(Universal Construction)
暂时忘掉函数类型是集合这件事,试着从零开始构造函数类型,或者更一般地说,构造内部 hom-set。像往常一样,我们会从 $Set$ 范畴中获取线索,但会小心避免使用集合的任何特殊性质,这样这个构造就会自动适用于其他范畴。
函数类型可以被视为复合类型,因为它与参数类型和结果类型有关。我们已经见过复合类型的构造,也就是那些涉及对象之间关系的构造。我们用通用构造定义过积类型和余积类型。现在可以用同样技巧定义函数类型。我们需要一个涉及三个对象的模式:正在构造的函数类型、参数类型和结果类型。
连接这三个类型的显然模式称为函数应用,或者求值。给定一个函数类型的候选者,称为 z(注意,如果不在 $Set$ 范畴中,它就只是一个普通对象),以及参数类型 a(一个对象),应用会把这一对映射到结果类型 b(一个对象)。我们有三个对象,其中两个是固定的(表示参数类型和结果类型的对象)。
我们还有应用,它是一个映射。如何把这个映射纳入模式?如果允许观察对象内部,就可以把函数 f(z 的一个元素)与参数 x(a 的一个元素)配成一对,并把它映射到 f x(把 f 应用到 x 上,结果是 b 的一个元素)。
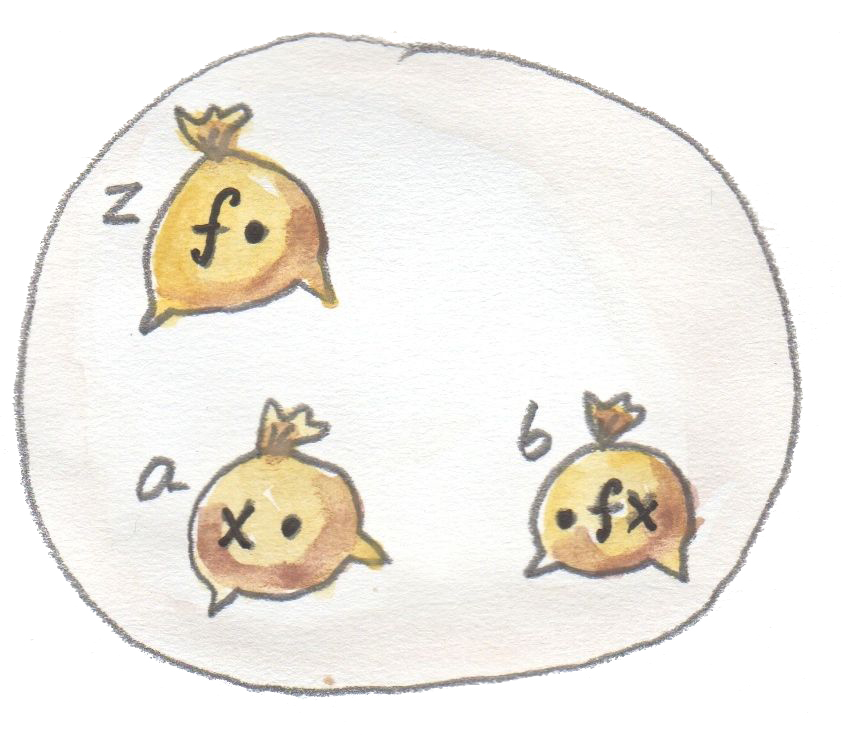
但除了处理单个对 (f, x),也可以谈论函数类型 z 与参数类型 a 的整个积。积 z x a 是一个对象,于是可以选择从该对象到 b 的箭头 g 作为我们的应用态射。在 $Set$ 中,g 会是那个把每一对 (f, x) 映射到 f x 的函数。
所以模式就是:两个对象 z 与 a 的积,通过态射 g 连接到另一个对象 b。
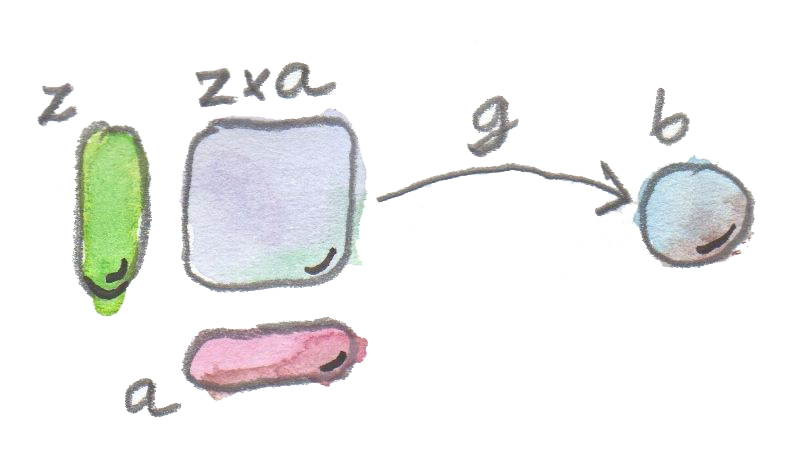
这个模式是否足够具体,能够用通用构造挑出函数类型?并不是在每个范畴中都可以。但在我们关心的范畴中可以。另一个问题是:是否能在不先定义积的情况下定义函数对象?有些范畴没有积,或者并非每对对象都有积。答案是否定的:如果没有积类型,就没有函数类型。稍后讨论指数对象时会回到这一点。
回顾一下通用构造。我们从一个对象与态射的模式开始。这是我们不精确的查询,通常会产生大量命中。特别是在 $Set$ 中,几乎所有东西都连接着所有东西。可以拿任意对象 z,把它与 a 形成积,然后通常都会有一个从它到 b 的函数(除非 b 是空集)。
这时就要使用秘密武器:排序。通常做法是要求候选对象之间存在唯一映射,这个映射以某种方式分解我们的构造。在这里,我们规定:带有从 z x a 到 b 的态射 g 的对象 z,优于另一个带有自身应用 g' 的对象 z',当且仅当存在唯一映射 h 从 z' 到 z,使得 g' 的应用能够通过 g 的应用分解。(提示:看着图读这句话。)
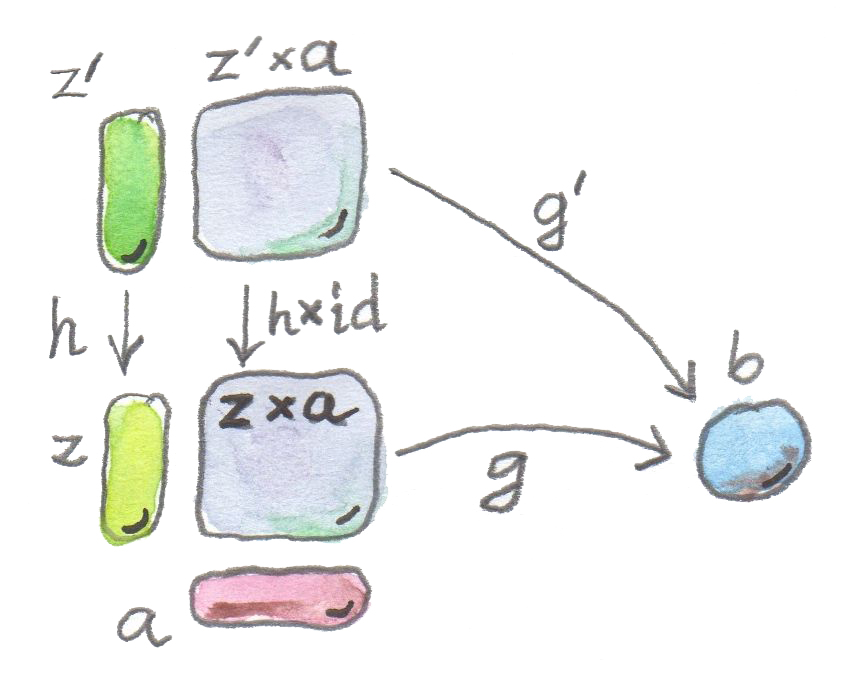
现在到了棘手的地方,这也是我把这个通用构造推迟到现在才讲的主要原因。给定态射 h :: z' -> z,我们想闭合那个同时包含 z' 与 z 分别和 a 做积的图。真正需要的是:给定从 z' 到 z 的映射 h,构造一个从 z' x a 到 z x a 的映射。现在,在讨论了积的函子性之后,我们知道该怎么做。因为积本身是一个函子(更准确地说,是一个自双函子),所以可以提升态射对。换句话说,我们不仅可以定义对象的积,也可以定义态射的积。
由于我们不会触碰积 z' x a 的第二个分量,所以会提升态射对 (h, id),其中 id 是 a 上的恒等态射。
因此,可以这样从另一个应用 g' 中分解出应用 g:
g' = g . (h x id)
这里的关键是积在态射上的作用。
通用构造的第三部分,是选择普遍最优的对象。把这个对象称为 a => b(把它看作一个对象的符号名,不要和 Haskell 类型类约束混淆;稍后会讨论它的不同命名方式)。这个对象带有自己的应用,也就是从 (a => b) x a 到 b 的态射,称为 eval。如果任意其他函数对象候选者都能以唯一方式映射到这个对象,使其应用态射 g 通过 eval 分解,那么对象 a => b 就是最优的。按照我们的排序,它优于所有其他对象。
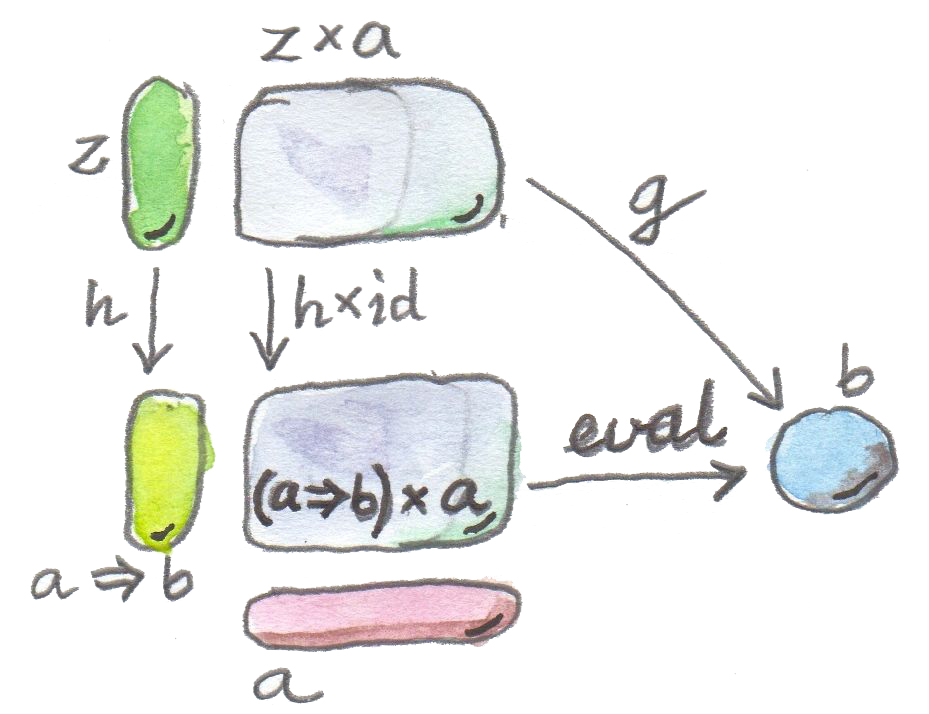
形式化地说:
从 a 到 b 的函数对象是一个对象 a => b,连同态射:
eval :: ((a => b) x a) -> b
并且对任意另一个对象 z 及其态射:
g :: z x a -> b
都存在唯一态射:
h :: z -> (a => b)
使得 g 通过 eval 分解:
g = eval . (h x id)
当然,给定范畴中任意一对对象 a 和 b,并不保证一定存在这样的对象 a => b。但在 $Set$ 中总是存在。而且在 $Set$ 中,这个对象与 hom-set Set(a, b) 同构。因此,在 Haskell 中,我们把函数类型 a -> b 解释为范畴意义下的函数对象 a => b。
9.2 柯里化(Currying)
再看一遍函数对象的所有候选者。不过这一次,把态射 g 看作两个变量 z 和 a 的函数。
g :: z x a -> b
作为来自积的态射,它已经非常接近双变量函数了。特别是在 $Set$ 中,g 是一个从值对出发的函数,其中一个值来自集合 z,另一个来自集合 a。
另一方面,通用性质告诉我们,对每个这样的 g,都存在唯一态射 h,把 z 映射到函数对象 a => b。
h :: z -> (a => b)
在 $Set$ 中,这只是说 h 是一个函数:它接受一个 z 类型的变量,并返回一个从 a 到 b 的函数。这使 h 成为高阶函数。因此,通用构造建立了双变量函数与返回函数的单变量函数之间的一一对应。这个对应称为柯里化,h 称为 g 的柯里化版本。
这个对应是一一的,因为给定任意 g,都有唯一的 h;而给定任意 h,也总能用下面的公式重建双参数函数 g:
g = eval . (h x id)
函数 g 可以称为 h 的非柯里化版本。
柯里化本质上内建在 Haskell 语法中。一个返回函数的函数:
a -> (b -> c)
A => (B => C)
常常被视为双变量函数。我们正是这样阅读不加括号的签名:
a -> b -> c
A => B => C
这种解释明显体现在多参数函数的定义方式中。例如:
catstr :: String -> String -> String
catstr s s' = s ++ s'
val catstr: (String, String) => String =
(s, s1) => s ++ s1
同一个函数可以写成一个返回函数的单参数函数,也就是一个 lambda:
catstr' s = \s' -> s ++ s'
val catstr1: String => String => String =
s => s1 => s ++ s1
这两个定义等价,并且二者都可以只应用一个参数,从而生成单参数函数,例如:
greet :: String -> String
greet = catstr "Hello "
val greet: String => String =
catstr("Hello ", _)
严格来说,双变量函数是接受 pair(积类型)的函数:
(a, b) -> c
(A, B) => C
在这两种表示之间转换非常简单,负责转换的两个高阶函数毫不意外地称为 curry 和 uncurry:
curry :: ((a, b) -> c) -> (a -> b -> c)
curry f a b = f (a, b)
def curry[A, B, C](f: (A, B) => C): A => B => C =
a => b => f(a, b)
以及:
uncurry :: (a -> b -> c) -> ((a, b) -> c)
uncurry f (a, b) = f a b
def uncurry[A, B, C](f: A => B => C): (A, B) => C =
(a, b) => f(a)(b)
注意,curry 正是函数对象通用构造中的分解器。如果把它改写成下面的形式,这一点尤其明显:
factorizer :: ((a, b) -> c) -> (a -> (b -> c))
factorizer g = \a -> (\b -> g (a, b))
def factorizer[A, B, C](g: (A, B) => C): A => (B => C) =
a => (b => g(a, b))
(提醒一下:分解器会从候选者生成分解函数。)
在 C++ 这样的非函数式语言中,柯里化是可能的,但并不简单。可以把 C++ 中的多参数函数看作对应 Haskell 中接受 tuple 的函数(不过为了让事情更混乱,C++ 既可以定义接受显式 std::tuple 的函数,也可以定义可变参数函数和接受初始化列表的函数)。
可以使用模板 std::bind 对 C++ 函数做部分应用。例如,给定一个双字符串函数:
std::string catstr(std::string s1, std::string s2) {
return s1 + s2;
}
可以定义一个单字符串函数:
using namespace std::placeholders;
auto greet = std::bind(catstr, "Hello ", _1);
std::cout << greet("Haskell Curry");
Scala 比 C++ 或 Java 更偏函数式,介于二者之间。如果你预见到正在定义的函数会被部分应用,就会用多个参数列表定义它:
def catstr(s1: String)(s2: String) = s1 + s2
当然,这要求库作者具备一定的预见能力。
9.3 指数对象(Exponentials)
在数学文献中,函数对象,或者两个对象 a 和 b 之间的内部 hom-object,常称为指数对象(exponential),记作 b^a。注意,参数类型在指数位置上。这个记法起初可能看起来奇怪,但如果想想函数与积之间的关系,它就非常合理。我们已经看到,在内部 hom-object 的通用构造中必须使用积,但二者的联系比这更深。
考虑有限类型之间的函数时,这一点最清楚。有限类型是拥有有限个值的类型,例如 Bool、Char,甚至 Int 或 Double。这样的函数原则上可以被完全记忆化,或者被转换成可查找的数据结构。这正是函数(态射)与函数类型(对象)之间等价关系的本质。
例如,从 Bool 出发的纯函数完全由一对值指定:一个对应 False,另一个对应 True。从 Bool 到比如 Int 的所有可能函数构成的集合,就是所有 Int 对的集合。这等同于积 Int x Int,如果在记法上稍微发挥一下,就是 Int^2。
再看 C++ 类型 char,它包含 256 个值(Haskell 的 Char 更大,因为 Haskell 使用 Unicode)。C++ 标准库中有一部分函数通常通过查表实现,例如 isupper 或 isspace。这些函数使用的表等价于 256 个 Boolean 值的 tuple。tuple 是积类型,所以我们处理的是 256 个 Boolean 的积:bool x bool x bool x ... x bool。从算术中知道,重复的积定义了幂。如果把 bool 自身“相乘”256 次(或者说 char 次),就得到 bool 的 char 次幂,也就是 bool^char。
定义为 256 元 bool tuple 的类型中有多少个值?恰好是 2^256。这也是从 char 到 bool 的不同函数的数量,每个函数对应唯一的 256 元 tuple。类似地,可以计算从 bool 到 char 的函数数量是 256^2,等等。函数类型的指数记法在这些情况下完全合理。
我们大概不会想完全记忆化一个从 int 或 double 出发的函数。但函数与数据类型之间的等价关系确实存在,只是不总是实用而已。也存在无限类型,例如列表、字符串或树。对这些类型出发的函数做急切记忆化需要无限存储。但 Haskell 是惰性语言,所以惰性求值的无限数据结构与函数之间的边界是模糊的。这种函数与数据的二重性,解释了为什么 Haskell 的函数类型可以与范畴论中的指数对象等同,而指数对象更接近我们对数据的想法。
9.4 笛卡尔闭范畴(Cartesian Closed Categories)
虽然我会继续使用集合范畴作为类型与函数的模型,但值得一提的是,还有一个更大的范畴族也可用于这个目的。这些范畴称为笛卡尔闭范畴,$Set$ 只是其中一个例子。
笛卡尔闭范畴必须包含:
- 终对象;
- 任意一对对象的积;
- 任意一对对象的指数对象。
如果把指数对象看作重复的积(可能重复无限多次),那么可以把笛卡尔闭范畴看作支持任意元数积的范畴。特别是,终对象可以看作零个对象的积,也就是某个对象的零次幂。
从计算机科学视角看,笛卡尔闭范畴有趣之处在于,它们为简单类型 lambda 演算提供模型,而简单类型 lambda 演算构成所有类型化编程语言的基础。
终对象和积都有对偶:始对象和余积。一个同时支持这两者,并且积可以分配到余积上的笛卡尔闭范畴:
a x (b + c) = a x b + a x c
(b + c) x a = b x a + c x a
称为双笛卡尔闭范畴(bicartesian closed category)。下一节会看到,双笛卡尔闭范畴有一些有趣性质,而 $Set$ 正是一个典型例子。
9.5 指数对象与代数数据类型(Exponentials and Algebraic Data Types)
把函数类型解释为指数对象,与代数数据类型的方案非常契合。事实证明,高中代数中所有关于零、一、和、积、指数的基本恒等式,在任意双笛卡尔闭范畴论中几乎都原样成立;它们分别对应始对象、终对象、余积、积和指数对象。我们还没有证明它们所需的工具(例如伴随或 Yoneda 引理),但我仍会在这里列出它们,把它们作为有价值的直觉来源。
9.5.1 零次幂(Zeroth Power)
a^0 = 1
在范畴解释中,用始对象替换 0,用终对象替换 1,用同构替换相等。指数对象就是内部 hom-object。这个特定的指数对象表示从始对象到任意对象 a 的态射集合。根据始对象的定义,这样的态射恰好有一个,所以 hom-set C(0, a) 是单元素集合。在 $Set$ 中,单元素集合是终对象,所以这个恒等式在 $Set$ 中平凡成立。我们要说的是,它在任意双笛卡尔闭范畴中都成立。
在 Haskell 中,用 Void 替换 0,用 unit 类型 () 替换 1,用函数类型替换指数。命题是:从 Void 到任意类型 a 的函数集合等价于 unit 类型,也就是单元素集合。换句话说,只有一个函数 Void -> a。我们以前见过这个函数,它叫作 absurd。
这有点棘手,原因有两个。其一,在 Haskell 中并没有真正无人居住的类型,每个类型都包含“永不结束的计算结果”,也就是 bottom。其二,absurd 的所有实现都是等价的,因为无论它们做什么,都没人能真正执行它们。没有值可以传给 absurd。(如果你设法传入一个永不结束的计算,它也永远不会返回!)
9.5.2 一的幂(Powers of One)
1^a = 1
这个恒等式在 $Set$ 中解释时,重述了终对象的定义:从任意对象到终对象都有唯一态射。一般来说,从 a 到终对象的内部 hom-object 与终对象自身同构。
在 Haskell 中,从任意类型 a 到 unit 只有一个函数。我们以前见过这个函数,它叫作 unit。也可以把它看成把 const 部分应用到 () 上。
9.5.3 一次幂(First Power)
a^1 = a
这是对前面观察的重述:从终对象出发的态射可以用来选择对象 a 的“元素”。这类态射的集合与对象本身同构。在 $Set$ 和 Haskell 中,同构发生在集合 a 的元素与选取这些元素的函数 () -> a 之间。
9.5.4 和的指数(Exponentials of Sums)
a^(b + c) = a^b x a^c
从范畴角度说,这表示来自两个对象余积的指数对象,同构于两个指数对象的积。在 Haskell 中,这个代数恒等式有非常实用的解释:来自两个类型之和的函数,等价于一对分别来自各个类型的函数。这正是我们定义和类型上的函数时使用的 case 分析。我们通常不会写一个带 case 语句的函数定义,而是把它拆成两个(或更多)函数,分别处理每个类型构造器。例如,取一个来自和类型 Either Int Double 的函数:
f :: Either Int Double -> String
val f: Either[Int, Double] => String
它可以定义为分别来自 Int 和 Double 的一对函数:
f (Left n) = if n < 0 then "Negative int" else "Positive int"
f (Right x) = if x < 0.0 then "Negative double" else "Positive double"
val f: Either[Int, Double] => String = {
case Left(n) => if (n < 0) "Negative int" else "Positive int"
case Right(x) => if (x < 0.0) "Negative double" else "Positive double"
}
这里,n 是 Int,x 是 Double。
9.5.5 指数的指数(Exponentials of Exponentials)
(a^b)^c = a^(b x c)
这只是用指数对象纯粹表达柯里化的一种方式。返回函数的函数,等价于来自积的函数(双参数函数)。
9.5.6 积上的指数(Exponentials over Products)
(a x b)^c = a^c x b^c
在 Haskell 中:返回 pair 的函数,等价于一对函数,每个函数产生 pair 的一个元素。
这些简单的高中代数恒等式能够提升到范畴论,并且在函数式编程中具有实际应用,这真是相当不可思议。
9.6 Curry-Howard 同构(Curry-Howard Isomorphism)
我已经提到过逻辑与代数数据类型之间的对应。Void 类型和 unit 类型 () 分别对应 false 和 true。积类型和和类型分别对应逻辑合取 AND 与析取 OR。在这个方案中,我们刚刚定义的函数类型对应逻辑蕴含。换句话说,类型 a -> b 可以读作“如果 a,则 b”。
根据 Curry-Howard 同构,每个类型都可以解释为一个命题,也就是一个可能为真或假的陈述或判断。如果类型有人居住,这个命题就被视为真;如果无人居住,就被视为假。特别是,如果某个逻辑蕴含对应的函数类型有人居住,也就是存在该类型的函数,那么这个蕴含就为真。因此,一个函数实现就是一个定理证明。写程序等价于证明定理。来看几个例子。
取我们在函数对象定义中引入的函数 eval。它的签名是:
eval :: ((a -> b), a) -> b
def eval[A, B]: ((A => B), A) => B
它接受一个由函数及其参数构成的 pair,并生成相应类型的结果。它是如下态射的 Haskell 实现:
eval :: (a => b) x a -> b
这个态射定义了函数类型 a => b(或者说指数对象 b^a)。用 Curry-Howard 同构把这个签名翻译为逻辑谓词:
((a => b) AND a) => b
这个陈述可以这样读:如果 b 从 a 推出为真,并且 a 为真,那么 b 必然为真。这在直觉上完全合理,并且自古以来就被称为肯定前件式(modus ponens)。可以通过实现函数来证明这个定理:
eval :: ((a -> b), a) -> b
eval (f, x) = f x
def eval[A, B]: ((A => B), A) => B =
(f, x) => f(x)
如果你给我一个 pair,里面包含函数 f(接受 a 并返回 b)和一个 a 类型的具体值 x,我就可以简单地把函数 f 应用到 x 上,产生一个 b 类型的具体值。通过实现这个函数,我刚刚展示了类型 ((a -> b), a) -> b 有居民。因此,肯定前件式在我们的逻辑中为真。
那一个明显为假的谓词呢?例如:如果 a 或 b 为真,那么 a 必然为真。
a OR b => a
这显然是错的,因为可以选择一个为假的 a 和一个为真的 b,这就是反例。
用 Curry-Howard 同构把这个谓词映射到函数签名,会得到:
Either a b -> a
Either[A, B] => A
无论如何尝试,都无法实现这个函数。如果调用时传入的是 Right 值,你就无法产生 a 类型的值。(记住,我们讨论的是纯函数。)
最后来看 absurd 函数的含义:
absurd :: Void -> a
def absurd[A]: Nothing => A
考虑到 Void 翻译为 false,可以得到:
false => a
从假命题可以推出任何命题(ex falso quodlibet)。下面是这个陈述(函数)在 Haskell 中一种可能的证明(实现):
absurd (Void a) = absurd a
其中 Void 定义为:
newtype Void = Void Void
和往常一样,Void 类型很微妙。这个定义使得构造一个值不可能,因为为了构造一个值,你需要先提供一个值。因此,函数 absurd 永远不可能被调用。
这些例子都很有趣,但 Curry-Howard 同构有实际用途吗?在日常编程中大概没有。但 Agda 或 Coq 这样的编程语言,会利用 Curry-Howard 同构来证明定理。
计算机不仅在帮助数学家完成他们的工作,也正在革新数学的基础。这个领域最新的热门研究主题称为同伦类型论(Homotopy Type Theory),它是类型论的发展成果。它充满了布尔值、整数、积与余积、函数类型等等。仿佛为了消除任何疑虑,这套理论正在 Coq 和 Agda 中形式化。计算机正在以不止一种方式革新世界。
9.7 参考资料(Bibliography)
- Ralph Hinze, Daniel W. H. James, Reason Isomorphically!。这篇论文包含本章提到的那些高中代数恒等式在范畴论中的证明。