第 9 章 构建我们自己的锁(Building Our Own Locks)
在本章中,我们将构建自己的互斥锁、条件变量和读写锁。对每一种原语,我们都会先从非常基础的版本开始,然后逐步扩展,使它更高效。
由于我们不会使用标准库中的锁类型(那样就有点作弊了),所以需要使用第 8 章中介绍的工具,让线程能够在不忙等的情况下等待。不过正如上一章所见,操作系统提供的工具在不同平台上差异很大,要构建一个跨平台可用的东西并不容易。
幸运的是,大多数现代操作系统都支持类似 futex 的功能,至少支持等待和唤醒操作。正如第 8 章所见,Linux 自 2003 年起通过 futex 系统调用支持这些操作,Windows 自 2012 年起通过 WaitOnAddress 系列函数支持,FreeBSD 自 2016 年起通过 _umtx_op 系统调用支持,等等。
最明显的例外是 macOS。虽然它的内核确实支持这些操作,但并没有通过稳定、公开可用的 C 函数暴露给我们。不过 macOS 附带了较新版本的 libc++,也就是 C++ 标准库的一种实现。该库包含对 C++20 的支持,而 C++20 内建了非常基础的原子等待和唤醒操作,例如 std::atomic<T>::wait()。虽然由于各种原因,从 Rust 中使用它有些棘手,但确实可行,因此我们也能在 macOS 上获得基础的类 futex 等待与唤醒功能。
我们不会深入这些脏活细节,而是使用 crates.io 上的 atomic-wait crate,为我们的锁原语提供基础构件。
这个 crate 只提供三个函数:wait()、wake_one() 和 wake_all()。它为所有主流平台实现了这些函数,底层使用前面讨论过的各种平台特定实现。这意味着只要我们坚持使用这三个函数,就不再需要考虑任何平台细节。
这些函数的行为类似于第 8 章 Linux futex 小节中实现的同名函数。快速回顾如下:
wait(&AtomicU32, u32)
该函数用于等待,直到原子变量不再包含给定值。如果原子变量中存储的值等于给定值,它就会阻塞。当另一个线程修改了该原子变量的值后,该线程需要在同一个原子变量上调用下面某个唤醒函数,把正在睡眠的线程唤醒。
这个函数可能会伪唤醒,也就是没有对应唤醒操作却返回。因此它返回之后,一定要重新检查原子变量的值,必要时重复调用 wait()。
wake_one(&AtomicU32)
唤醒一个当前正在同一个原子变量上通过 wait() 阻塞的线程。通常在修改原子变量之后立即使用它,通知一个等待线程发生了变化。
wake_all(&AtomicU32)
唤醒所有当前正在同一个原子变量上通过 wait() 阻塞的线程。通常在修改原子变量之后立即使用它,通知所有等待线程发生了变化。
这里只支持 32 位原子变量,因为这是所有主流平台都支持的唯一大小。
在第 8 章的 futex 小节中,我们讨论过一个非常小的示例,展示这些函数在实践中如何使用。如果忘记了,继续之前最好回去看看那个例子。
要使用 atomic-wait crate,可以在 Cargo.toml 的 [dependencies] 小节中加入 atomic-wait = "1",也可以运行 cargo add atomic-wait@1 自动完成。三个函数定义在 crate 根部,可以用如下方式导入:
use atomic_wait::{wait, wake_one, wake_all};
当你读到这里时,这个 crate 可能已经有更新版本。不过只有主版本 1 是为本章准备的。后续版本的接口不一定兼容。
现在基础构件已经准备好了,开始动手吧。
Mutex
构建 Mutex<T> 时,我们会把第 4 章中的 SpinLock<T> 类型作为参照。与阻塞无关的部分,例如守卫类型的设计,会保持不变。
先从类型定义开始。和自旋锁相比,我们需要做一个改动:不用值为 false 或 true 的 AtomicBool,而是使用值为零或一的 AtomicU32,这样才能配合原子等待与唤醒函数使用。
pub struct Mutex<T> {
/// 0: unlocked
/// 1: locked
state: AtomicU32,
value: UnsafeCell<T>,
}
和自旋锁一样,我们需要承诺 Mutex<T> 可以在线程之间共享,即使它内部包含一个看起来吓人的 UnsafeCell:
unsafe impl<T> Sync for Mutex<T> where T: Send {}
我们还会加入一个 MutexGuard 类型,它实现 Deref trait,提供完全安全的加锁接口,就像第 4 章“使用锁守卫的安全接口”中所做的那样:
pub struct MutexGuard<'a, T> {
mutex: &'a Mutex<T>,
}
impl<T> Deref for MutexGuard<'_, T> {
type Target = T;
fn deref(&self) -> &T {
unsafe { &*self.mutex.value.get() }
}
}
impl<T> DerefMut for MutexGuard<'_, T> {
fn deref_mut(&mut self) -> &mut T {
unsafe { &mut *self.mutex.value.get() }
}
}
关于锁守卫类型的设计和运行方式,可以回看第 4 章“使用锁守卫的安全接口”。
在进入有趣部分之前,先把 Mutex::new 函数写掉:
impl<T> Mutex<T> {
pub const fn new(value: T) -> Self {
Self {
state: AtomicU32::new(0), // unlocked state
value: UnsafeCell::new(value),
}
}
// ...
}
现在只剩下两块:加锁(Mutex::lock())和解锁(MutexGuard<T> 的 Drop 实现)。
我们为自旋锁实现的 lock 函数使用原子交换操作尝试获取锁:如果它成功把状态从“未锁定”改成“已锁定”,就返回;如果失败,就立即再次尝试。
为了给互斥锁加锁,我们会做几乎相同的事情,只是在重试之前使用 wait() 等待:
pub fn lock(&self) -> MutexGuard<T> {
// Set the state to 1: locked.
while self.state.swap(1, Acquire) == 1 {
// If it was already locked..
// .. wait, unless the state is no longer 1.
wait(&self.state, 1);
}
MutexGuard { mutex: self }
}
对于内存排序,推理方式与自旋锁相同。细节可回看第 4 章。
注意,wait() 函数只有在我们调用它时状态仍然是 1(已锁定)才会阻塞,因此不用担心在 swap 和 wait 调用之间错过一次唤醒。
守卫类型的 Drop 实现负责解锁互斥锁。解锁自旋锁很简单:把状态设回 false(未锁定)即可。但对互斥锁来说,这还不够。如果有线程正在等待锁定该互斥锁,除非我们通过唤醒操作通知它,否则它不会知道互斥锁已经解锁。如果不唤醒它,它很可能会永远睡下去。(也许它足够幸运,会在正确时刻被伪唤醒,但我们不应该指望这一点。)
所以,我们不仅要把状态设回 0(未锁定),还要紧接着调用 wake_one():
impl<T> Drop for MutexGuard<'_, T> {
fn drop(&mut self) {
// Set the state back to 0: unlocked.
self.mutex.state.store(0, Release);
// Wake up one of the waiting threads, if any.
wake_one(&self.mutex.state);
}
}
唤醒一个线程就足够了,因为即使有多个线程在等待,也只有一个线程能成功拿到锁。下一个拿到锁的线程在使用完锁后,会再唤醒另一个线程,如此往复。一次唤醒多个线程只会让它们空欢喜,浪费宝贵的处理器时间:除一个线程外,其余线程会发现锁已经被别的幸运线程抢走,然后不得不再次睡眠。
需要注意的是,我们并不保证被唤醒的那个线程一定能拿到锁。另一个线程可能刚好在它有机会之前抢到锁。
这里有一个重要观察:即使没有 wait 和 wake 函数,这个互斥锁实现从技术上说仍然是正确的,也就是内存安全的。由于 wait() 操作可能伪唤醒,我们不能对它何时返回做任何假设。锁原语的状态仍然必须由我们自己管理。如果去掉 wait 和 wake 函数调用,这个互斥锁基本上就与自旋锁相同。
一般来说,从内存安全角度看,原子等待与唤醒函数从来不是正确性的决定因素。它们只是一个非常重要的优化,用于避免忙等。这并不意味着一个低效到不可用的锁会被任何实践标准视为“正确”,但这个洞见有助于我们推理 unsafe Rust 代码。
Lock API
如果你打算把实现 Rust 锁当作新爱好,很快可能会厌烦那些用于提供安全接口的样板代码:UnsafeCell、Sync 实现、守卫类型、Deref 实现,等等。
crates.io 上的 lock_api crate 可以自动处理所有这些事情。你只需要创建一个表示锁状态的类型,并通过 unsafe 的 lock_api::RawMutex trait 提供 unsafe 的锁定和解锁函数。作为回报,lock_api::Mutex 类型会基于你的锁实现,提供一个完全安全且符合人体工学的互斥锁类型,包括互斥锁守卫。
避免系统调用(Avoiding Syscalls)
我们的互斥锁中最慢的部分远远是 wait 和 wake,因为它们可能导致系统调用,也就是调用操作系统内核。与内核通信是一个相当复杂的过程,往往很慢,尤其是和原子操作相比。因此,要实现高性能互斥锁,应尽量避免 wait 和 wake 调用。
幸运的是,我们已经成功了一半。由于加锁函数中的 while 循环会在调用 wait() 之前检查状态,在不需要等待的场景,也就是互斥锁没有被锁定时,wait 操作会被完全跳过。不过,解锁时我们仍然无条件调用 wake_one()。
如果知道没有其他线程在等待,就可以跳过 wake_one()。要知道是否存在等待线程,就需要自己跟踪这项信息。
可以把“已锁定”状态拆成两个单独状态:“已锁定且没有等待者”和“已锁定且有等待者”。我们分别使用值 1 和 2,并更新结构体定义中 state 字段的文档注释:
pub struct Mutex<T> {
/// 0: unlocked
/// 1: locked, no other threads waiting
/// 2: locked, other threads waiting
state: AtomicU32,
value: UnsafeCell<T>,
}
现在,对于未锁定的互斥锁,加锁函数仍然需要把状态设为 1 来锁定它。不过如果它已经被锁住,加锁函数就需要在睡眠前把状态设为 2,这样解锁函数才能知道有线程在等待。
为此,我们首先使用 compare-and-exchange 函数,尝试把状态从 0 改为 1。如果成功,我们就拿到了锁,而且知道没有其他等待者,因为之前互斥锁并没有被锁住。如果失败,那必然是因为互斥锁当前处于已锁定状态(状态 1 或 2)。这种情况下,我们使用原子 swap 操作把它设为 2。如果该 swap 返回的旧值是 1 或 2,说明互斥锁确实仍然被锁住,只有这时才使用 wait() 阻塞,直到状态发生变化。如果 swap 操作返回 0,说明我们已经通过把状态从 0 改成 2 成功拿到了锁。
pub fn lock(&self) -> MutexGuard<T> {
if self.state.compare_exchange(0, 1, Acquire, Relaxed).is_err() {
while self.state.swap(2, Acquire) != 0 {
wait(&self.state, 2);
}
}
MutexGuard { mutex: self }
}
现在,解锁函数可以利用这项新信息,在不必要时跳过 wake_one() 调用。不再只是存储 0 来解锁互斥锁,而是使用 swap 操作检查它之前的值。只有当旧值为 2 时,才继续唤醒一个线程:
impl<T> Drop for MutexGuard<'_, T> {
fn drop(&mut self) {
if self.mutex.state.swap(0, Release) == 2 {
wake_one(&self.mutex.state);
}
}
}
注意,把状态设回零之后,它不再表示是否有任何线程正在等待。被唤醒的线程负责把状态重新设为 2,以确保不会忘记其他等待线程。这就是为什么 compare-and-exchange 操作没有放进加锁函数的 while 循环中。
这确实意味着,每当一个线程在加锁时不得不 wait(),它在解锁时也会调用 wake_one(),即使这不一定必要。不过最重要的是,在无竞争场景,也就是线程没有同时尝试获取锁的理想场景中,wait() 和 wake_one() 调用都会完全避免。
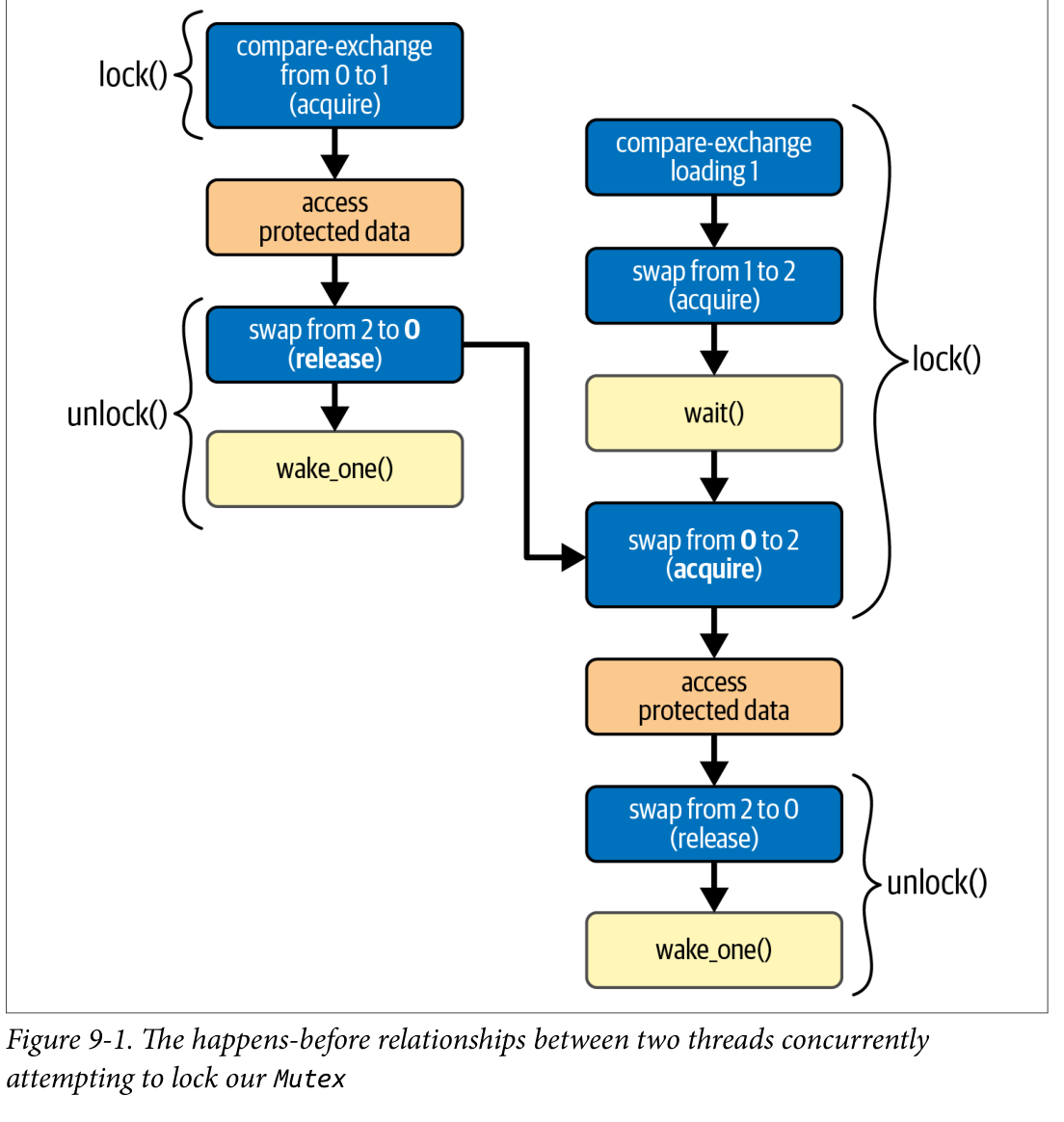
图 9-1 展示了两个线程并发尝试锁定 Mutex 时的操作和 happens-before 关系。第一个线程通过把状态从 0 改为 1 来锁定互斥锁。此时第二个线程无法获取锁,因此在把状态从 1 改为 2 后进入睡眠。当第一个线程解锁 Mutex 时,它把状态交换回 0。由于旧状态为 2,表示存在等待线程,它会调用 wake_one() 唤醒第二个线程。
注意,我们并不依赖 wake 和 wait 操作之间的任何 happens-before 关系。虽然很可能正是 wake 操作唤醒了等待线程,但真正的 happens-before 关系是通过 acquire 的 swap 操作观察到 release 的 swap 操作存储的值而建立的。
进一步优化(Optimizing Further)
到这里,似乎已经没有太多可优化空间了。在无竞争场景中,我们执行零次系统调用,剩下的只是两个非常简单的原子操作。
避免 wait 和 wake 操作的唯一方式,是回到自旋锁实现。虽然自旋通常非常低效,但至少避免了系统调用的潜在开销。只有在等待时间非常短的情况下,自旋才可能更高效。
对于互斥锁加锁来说,这只会发生在当前持有锁的线程正在另一个处理器核心上并行运行,并且只会非常短暂地持有锁的情形中。不过这也是一种非常常见的情况。
我们可以尝试结合两种方法的优点:在调用 wait() 之前先短暂自旋一小会儿。这样,如果锁很快释放,就根本不需要调用 wait();与此同时,我们仍然避免消耗过多处理器时间,让其他线程无法更好地利用这些资源。
实现这一点只需要修改 lock 函数。
为了让无竞争场景尽可能高效,我们会保留 lock 函数开头原本的 compare-and-exchange 操作。自旋等待会交给一个单独函数。
impl<T> Mutex<T> {
// ...
pub fn lock(&self) -> MutexGuard<T> {
if self.state.compare_exchange(0, 1, Acquire, Relaxed).is_err() {
// The lock was already locked. :(
lock_contended(&self.state);
}
MutexGuard { mutex: self }
}
}
fn lock_contended(state: &AtomicU32) {
// ...
}
在 lock_contended 中,我们可以在进入等待循环之前简单重复同一个 compare-and-exchange 操作几百次。不过 compare-and-exchange 操作通常会尝试获得相关缓存行的独占访问权(见第 7 章 MESI 协议部分),当重复执行时,它可能比简单的加载操作更昂贵。
考虑到这一点,我们得到如下 lock_contended 实现:
fn lock_contended(state: &AtomicU32) {
let mut spin_count = 0;
while state.load(Relaxed) == 1 && spin_count < 100 {
spin_count += 1;
std::hint::spin_loop();
}
if state.compare_exchange(0, 1, Acquire, Relaxed).is_ok() {
return;
}
while state.swap(2, Acquire) != 0 {
wait(state, 2);
}
}
首先,我们最多自旋 100 次,并像第 4 章那样使用自旋循环提示。只有当互斥锁已锁定且没有等待者时,我们才自旋。如果另一个线程已经在等待,就说明它因为等待太久而放弃了自旋,这可能暗示对当前线程来说自旋也不太有用。
100 次循环这个自旋时长主要是任意选择的。一次迭代所需时间,以及我们试图避免的系统调用耗时,都高度依赖平台。大量基准测试有助于选择合适数字,但遗憾的是并不存在一个唯一正确答案。
Rust 标准库中 Linux 版本的
std::sync::Mutex实现,至少 Rust 1.66.0 中的实现,使用的自旋计数是 100。
锁状态变化后,我们在放弃并开始等待之前,会再尝试一次通过把状态设为 1 来锁定它。如前所述,一旦调用过 wait(),就不能再通过把状态设为 1 来锁定互斥锁,因为那可能导致忘记其他等待者。
cold 和 inline 属性
你可以给 lock_contended 函数定义添加 #[cold] 属性,帮助编译器理解这个函数在常见的无竞争场景中不会被调用,从而有助于优化 lock 方法。
此外,也可以给 Mutex 和 MutexGuard 的方法添加 #[inline] 属性,告诉编译器把这些方法内联也许是个好主意:也就是把生成的指令直接放到方法调用的位置。一般来说,这是否提升性能很难断言,但对于这些非常小的函数,通常会有帮助。
基准测试(Benchmarking)
测试一个互斥锁实现的性能很难。写一个基准测试并得到一些数字很容易,但得到有意义的数字非常难。
针对某个特定基准测试优化互斥锁实现,让它表现很好相对容易,但这并不太有用。毕竟目标是让它在真实世界程序中表现良好,而不是只在测试程序中好看。
我们会尝试写两个简单基准测试,展示优化至少在某些用例中有积极效果,但请记住,任何结论都不一定能推广到其他场景。
第一个测试会创建一个 Mutex,并在同一线程上对它加锁和解锁几百万次,测量总耗时。这是一个简单的无竞争场景测试,从来没有需要被唤醒的线程。希望它能显示出二状态版本和三状态版本之间的显著差异。
fn main() {
let m = Mutex::new(0);
std::hint::black_box(&m);
let start = Instant::now();
for _ in 0..5_000_000 {
*m.lock() += 1;
}
let duration = start.elapsed();
println!("locked {} times in {:?}", *m.lock(), duration);
}
我们使用 std::hint::black_box(类似第 7 章性能影响小节中所做的),强迫编译器假定可能还有更多代码会访问该互斥锁,防止它优化掉循环或加锁操作。
结果会随着硬件和操作系统强烈变化。在一台使用较新 AMD 处理器的 Linux 电脑上运行,未优化的二状态互斥锁总耗时约 400 毫秒,更优化的三状态互斥锁约 40 毫秒,提升十倍!在另一台使用较旧 Intel 处理器的 Linux 电脑上,差异更大:约 1800 毫秒对 60 毫秒。这证明增加第三个状态确实可以是非常显著的优化。
然而,在运行 macOS 的电脑上运行这个测试,会产生完全不同的结果:两个版本都大约 50 毫秒,说明这高度依赖平台。
事实证明,我们在 macOS 上使用的 libc++ 的 std::atomic<T>::wake() 实现已经有自己的簿记机制,独立于内核,用于避免不必要的系统调用。Windows 上的 WakeByAddressSingle() 也是如此。
避免调用这些函数仍然可能带来略微更好的性能,因为它们的实现远非平凡,尤其是因为它们不能在原子变量本身中存储任何信息。不过,如果只面向这些操作系统,就需要质疑给互斥锁增加第三个状态是否真的值得。
为了观察自旋优化是否带来正面效果,需要另一个基准测试:存在大量竞争,多个线程反复尝试锁定已经被锁住的互斥锁。
我们尝试一个场景:四个线程都并发尝试对同一个互斥锁加锁和解锁几百万次:
fn main() {
let m = Mutex::new(0);
std::hint::black_box(&m);
let start = Instant::now();
thread::scope(|s| {
for _ in 0..4 {
s.spawn(|| {
for _ in 0..5_000_000 {
*m.lock() += 1;
}
});
}
});
let duration = start.elapsed();
println!("locked {} times in {:?}", *m.lock(), duration);
}
注意,这是一个极端且不现实的场景。互斥锁只被持有极短时间(只是递增一个整数),而线程在解锁后会立即再次尝试锁定互斥锁。不同场景很可能得到非常不同的结果。
在前面两台 Linux 电脑上运行这个基准测试。较旧 Intel 处理器那台机器上,不自旋版本大约 900 毫秒,使用自旋版本约 750 毫秒,有提升!然而在较新 AMD 处理器那台机器上,结果相反:不自旋约 650 毫秒,自旋约 800 毫秒。
结论是,自旋是否真正提升性能,答案遗憾地是“看情况”,即便只观察一个场景也是如此。
条件变量(Condition Variable)
继续看更有趣的东西:实现一个条件变量。
正如第 1 章“条件变量”小节所见,条件变量会与互斥锁配合使用,用于等待受互斥锁保护的数据满足某个条件。它有一个 wait 方法,会解锁互斥锁,等待信号,然后再次锁定同一个互斥锁。信号由其他线程发送,通常是在修改受互斥锁保护的数据之后发送,用于唤醒一个等待线程(常称为“notify one”或“signal”)或所有等待线程(常称为“notify all”或“broadcast”)。
虽然条件变量试图让等待线程一直睡眠到收到信号,但等待线程也可能伪唤醒,也就是没有对应信号却被唤醒。不过条件变量的等待操作在返回之前仍然会重新锁定互斥锁。
注意,这个接口几乎与我们的类 futex wait()、wake_one() 和 wake_all() 函数相同。主要区别在于防止丢失信号的机制。条件变量会在解锁互斥锁之前开始“监听”信号,以避免错过刚解锁后出现的信号;而 futex 风格的 wait() 函数依赖检查原子变量状态,确认等待仍然是合理的。
这引出了一个最小条件变量实现思路:如果确保每次通知都会改变某个原子变量(例如计数器),那么 Condvar::wait() 方法只需要在解锁互斥锁之前检查该变量的值,并在解锁后把这个值传给 futex 风格的 wait() 函数。这样,如果在解锁互斥锁之后有任何通知信号到达,它就不会进入睡眠。
来试试看!
先从一个只包含单个 AtomicU32 的 Condvar 结构体开始,并把它初始化为零:
pub struct Condvar {
counter: AtomicU32,
}
impl Condvar {
pub const fn new() -> Self {
Self { counter: AtomicU32::new(0) }
}
// ...
}
通知方法很简单。它们只需要修改计数器,并使用对应的唤醒操作通知等待线程:
pub fn notify_one(&self) {
self.counter.fetch_add(1, Relaxed);
wake_one(&self.counter);
}
pub fn notify_all(&self) {
self.counter.fetch_add(1, Relaxed);
wake_all(&self.counter);
}
内存排序稍后讨论。
wait 方法会接收一个 MutexGuard,因为它代表互斥锁已被锁定的证明。它也会返回一个 MutexGuard,因为它会确保返回前互斥锁再次被锁定。
按照上面的草图,该方法会先在解锁互斥锁之前检查当前计数器值。解锁互斥锁后,只有当计数器没有变化时才等待,以确保没有错过任何信号。代码如下:
pub fn wait<'a, T>(&self, guard: MutexGuard<'a, T>) -> MutexGuard<'a, T> {
let counter_value = self.counter.load(Relaxed);
// Unlock the mutex by dropping the guard,
// but remember the mutex so we can lock it again later.
let mutex = guard.mutex;
drop(guard);
// Wait, but only if the counter hasn't changed since unlocking.
wait(&self.counter, counter_value);
mutex.lock()
}
这会使用 MutexGuard 的私有 mutex 字段。Rust 的隐私基于模块,因此如果这段代码定义在与 MutexGuard 不同的模块中,就需要把 MutexGuard 的 mutex 字段标记为例如 pub(crate),让 crate 内其他模块可用。
在庆祝条件变量完成之前,先花一点时间思考内存排序。
只要互斥锁处于锁定状态,其他线程就不能修改受互斥锁保护的数据。因此,我们不用担心解锁互斥锁之前发生的通知,因为只要我们持有互斥锁,数据就不会发生任何让我们改变睡眠等待意愿的事情。
唯一需要关注的情况是:在我们释放互斥锁之后,另一个线程出现并锁定该互斥锁,修改受保护数据,然后通知我们(希望是在解锁互斥锁之后通知)。
在这种情况下,Condvar::wait() 中的解锁互斥锁操作,与通知线程中的锁定互斥锁操作之间存在 happens-before 关系。正是这个 happens-before 关系保证,我们的 relaxed 加载(发生在解锁之前)会观察到通知的 relaxed 递增操作(发生在加锁之后)之前的值。
我们不知道 wait() 操作会看到递增之前还是之后的值,因为此时没有任何东西保证排序。不过这没关系,因为 wait() 相对于对应的唤醒操作是原子的。它要么看到新值,此时根本不会睡眠;要么看到旧值,此时会进入睡眠,并被通知中的 wake_one() 或 wake_all() 调用唤醒。
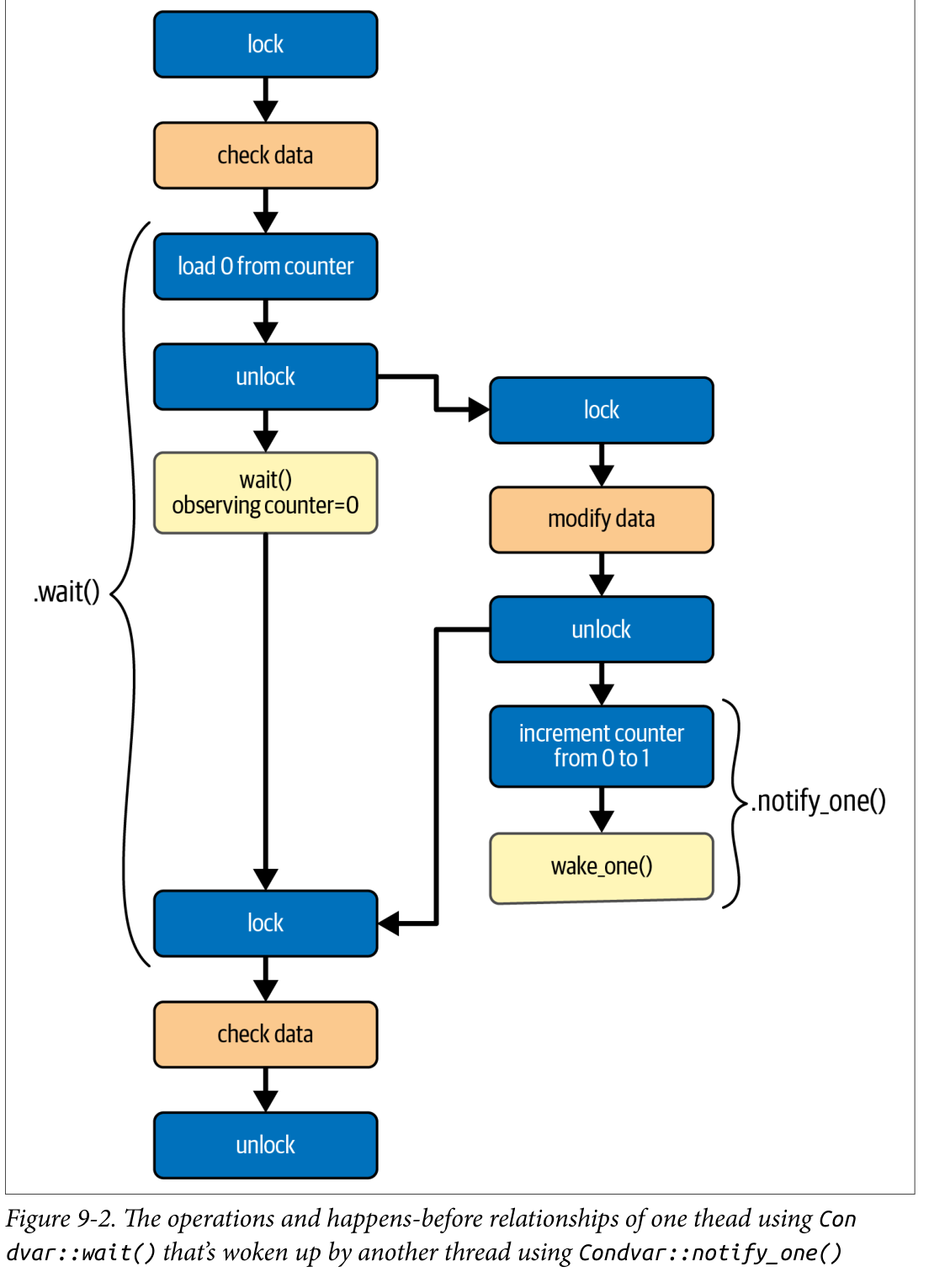
图 9-2 展示了一个线程使用 Condvar::wait() 等待某些受互斥锁保护的数据发生变化,并由另一个修改数据并调用 Condvar::wake_one() 的线程唤醒时的操作和 happens-before 关系。注意,由于解锁和加锁操作,第一个加载操作被保证观察到计数器递增之前的值。
还应该考虑计数器溢出时会发生什么。
计数器的实际值并不重要,只要每次通知之后它都不同即可。遗憾的是,在略多于 40 亿次通知之后,计数器会溢出并从零重新开始,回到之前使用过的值。
从技术上说,我们的 Condvar::wait() 实现可能在不该睡眠时睡眠:如果它恰好错过了 4,294,967,296 次通知(或该数的任意倍),计数器就会完整绕回到之前的值。
认为这种情况发生概率可以忽略不计是完全合理的。与互斥锁加锁方法不同,我们不会在唤醒后重新检查状态并重复 wait() 调用,因此只需要担心 relaxed 加载计数器和 wait() 调用之间那一瞬间发生一次完整溢出回绕。如果一个线程能被中断足够久,允许正好那么多次通知发生,程序很可能已经严重出错并失去响应了。到那时,一个线程错误地继续睡眠的微小额外风险,也许已经不重要了。
在支持带时间限制的 futex 风格等待的平台上,可以通过给等待操作设置几秒钟超时来缓解溢出风险。发送 40 亿次通知会花费明显更久,这时额外几秒钟的风险影响很小。这可以完全消除程序因为等待线程错误地永远睡眠而卡死的风险。
看看它是否能工作:
#[test]
fn test_condvar() {
let mutex = Mutex::new(0);
let condvar = Condvar::new();
let mut wakeups = 0;
thread::scope(|s| {
s.spawn(|| {
thread::sleep(Duration::from_secs(1));
*mutex.lock() = 123;
condvar.notify_one();
});
let mut m = mutex.lock();
while *m < 100 {
m = condvar.wait(m);
wakeups += 1;
}
assert_eq!(*m, 123);
});
// Check that the main thread actually did wait (not busy-loop),
// while still allowing for a few spurious wake ups.
assert!(wakeups < 10);
}
我们统计条件变量的 wait 方法返回了多少次,以确保它确实进入睡眠。如果这个数字非常高,就说明我们意外地在自旋循环。测试这一点很重要,因为一个永不睡眠的条件变量仍然会产生“正确”行为,但实际上会把等待循环变成自旋循环。
如果运行这个测试,会看到它能正常编译并通过,确认条件变量确实让主线程进入了睡眠。当然,这并不能证明实现是正确的。如有必要,可以在弱内存排序处理器架构的机器上运行涉及许多线程的长时间压力测试,以获得更多信心。
避免系统调用(Avoiding Syscalls)
正如在互斥锁的“避免系统调用”中意识到的,优化锁原语主要就是避免不必要的 wait 和 wake 操作。
对于条件变量来说,尝试避免 Condvar::wait() 实现中的 wait() 调用意义不大。当一个线程决定等待条件变量时,它已经检查过自己等待的事情尚未发生,并且需要睡眠。如果不需要等待,它一开始就不会调用 Condvar::wait()。
不过,类似我们对 Mutex 所做的,如果没有等待线程,就可以避免 wake_one() 和 wake_all() 调用。
一种简单方式是跟踪等待线程数量。wait 方法需要在等待前递增它,并在完成时递减它。然后通知方法就可以在该数量为零时跳过发送信号。
因此,给 Condvar 结构体增加一个新字段,跟踪活跃等待者数量:
pub struct Condvar {
counter: AtomicU32,
num_waiters: AtomicUsize, // New!
}
impl Condvar {
pub const fn new() -> Self {
Self {
counter: AtomicU32::new(0),
num_waiters: AtomicUsize::new(0), // New!
}
}
// ...
}
使用 AtomicUsize 表示 num_waiters,我们就不用担心它溢出。usize 大到足以计数内存中的每一个字节,因此如果假设每个活跃线程至少占用一个字节内存,它肯定足以计数任意数量的同时存在的线程。
接着,更新通知函数,让它们在没有等待者时什么都不做:
pub fn notify_one(&self) {
if self.num_waiters.load(Relaxed) > 0 { // New!
self.counter.fetch_add(1, Relaxed);
wake_one(&self.counter);
}
}
pub fn notify_all(&self) {
if self.num_waiters.load(Relaxed) > 0 { // New!
self.counter.fetch_add(1, Relaxed);
wake_all(&self.counter);
}
}
同样,内存排序稍后讨论。
最后,也是最重要的,在 wait 方法开头递增它,并在醒来后立即递减:
pub fn wait<'a, T>(&self, guard: MutexGuard<'a, T>) -> MutexGuard<'a, T> {
self.num_waiters.fetch_add(1, Relaxed); // New!
let counter_value = self.counter.load(Relaxed);
let mutex = guard.mutex;
drop(guard);
wait(&self.counter, counter_value);
self.num_waiters.fetch_sub(1, Relaxed); // New!
mutex.lock()
}
我们应该再次仔细问自己:这些原子操作都使用 relaxed 内存排序是否足够?
我们引入的一个新潜在风险是,某个通知方法在 num_waiters 中观察到零,于是跳过唤醒操作,而实际上有一个线程需要被唤醒。当通知方法观察到递增操作之前的值,或递减操作之后的值时,就可能发生这种情况。
就像对计数器的 relaxed 加载一样,等待者在递增 num_waiters 时仍然持有互斥锁这一事实,确保任何在解锁互斥锁之后发生的 num_waiters 加载,都不会看到递增之前的值。
我们也不用担心通知线程“过早”观察到递减后的值,因为一旦递减操作已经执行,也许是在一次伪唤醒之后,等待线程就不再需要被唤醒了。
换句话说,互斥锁建立的 happens-before 关系仍然提供了我们需要的全部保证。
避免伪唤醒(Avoiding Spurious Wake-ups)
优化条件变量的另一种方式,是避免伪唤醒。每当一个线程被唤醒,它都会尝试锁定互斥锁,可能与其他线程竞争,这会显著影响性能。
底层 wait() 操作发生伪唤醒并不常见,但我们的条件变量实现很容易让 notify_one() 导致不止一个线程停止等待。如果某个线程正在进入睡眠的过程中,刚加载了计数器值但尚未睡眠,调用 notify_one() 会由于计数器已经更新而阻止该线程睡眠,但随后的 wake_one() 操作还会唤醒第二个线程。然后这两个线程都会竞争锁定互斥锁,浪费宝贵的处理器时间。
这听起来像是罕见情况,但实际上很容易发生,因为互斥锁会同步这些线程。一个调用条件变量 notify_one() 的线程,很可能刚刚锁定并解锁了互斥锁,以修改等待线程正在等待的数据。这意味着一旦 Condvar::wait() 方法解锁互斥锁,就可能立即解除某个正在等待该互斥锁的通知线程的阻塞。此时两个线程进入竞态:等待线程试图进入睡眠,通知线程试图锁定并解锁互斥锁并通知条件变量。如果通知线程赢得竞态,等待线程由于递增后的计数器不会进入睡眠,但通知线程仍然会调用 wake_one()。这正是前面描述的问题场景:它可能不必要地额外唤醒另一个等待线程。
一个相对直接的解决方案,是跟踪允许被唤醒的线程数量,也就是允许从 Condvar::wait() 返回的线程数量。notify_one 方法会把它加一,而 wait 方法会在该值不为零时尝试把它减一。如果计数器为零,它可以进入(或重新进入)睡眠,而不是尝试重新锁定互斥锁并返回。(通知所有线程可以通过另一个专门用于 notify_all 且永不递减的计数器完成。)
这个方法可行,但会带来一个新的、更微妙的问题:一次通知可能唤醒一个甚至还没调用 Condvar::wait() 的线程,包括通知线程自身。一次 Condvar::notify_one() 调用会递增应该被唤醒的线程数,并使用 wake_one() 唤醒一个等待线程。然后,如果另一个(甚至同一个)线程随后调用 Condvar::wait(),并且发生在原本已经等待的线程有机会醒来之前,新等待的线程可能看到还有一个待处理通知,并通过把计数器减为零把它拿走,然后立即返回。第一个已经在等待的线程会再次睡眠,因为通知已经被另一个线程拿走。
根据用例,这可能完全没问题,也可能是大问题,会导致某些线程永远无法取得进展。
GNU libc 的
pthread_cond_t实现曾经存在这个问题。经过大量关于 POSIX 规范是否允许这种行为的讨论后,该问题最终在 2017 年 GNU libc 2.25 发布时解决,后者包含了一个全新的条件变量实现。
在很多使用条件变量的场景中,一个等待者拿走更早的通知是完全可以接受的。不过,当实现一个通用条件变量,而不是面向某类特定用例时,这种行为可能无法接受。
于是我们又必须得出一个并不意外的结论:是否应该使用优化方法,答案仍然是“看情况”。
有一些方式可以在避免这个问题的同时仍然避免伪唤醒,但它们比其他方法复杂得多。
GNU libc 新条件变量所用的解决方案,会把等待者分成两个组,只允许第一组消耗通知,并在第一组没有等待者后交换两组。
这种方法的缺点不仅在于算法复杂,还在于它显著增加了条件变量类型的大小,因为现在需要跟踪更多信息。
惊群问题(Thundering Herd Problem)
使用条件变量时可能遇到的另一个性能问题,出现在使用 notify_all() 唤醒许多等待同一件事的线程时。
问题在于,醒来之后所有这些线程都会立即尝试锁定同一个互斥锁。最有可能的是,只有一个线程能成功,所有其他线程都必须重新睡眠。这种许多线程全部冲向同一个资源的资源浪费问题,被称为惊群问题。
可以说 Condvar::notify_all() 从根本上就是一个不值得优化的反模式,这并非没有道理。条件变量的目的就是解锁互斥锁,并在被通知时重新锁定它,因此一次通知多个线程也许从来不会带来什么好事。
即便如此,如果我们想优化这种情况,在支持类 futex 重新排队操作的操作系统上可以做到,例如 Linux 的 FUTEX_REQUEUE。
与其唤醒许多线程,让除了一个以外的所有线程在发现锁已经被拿走后立即再次睡眠,不如重新排队除一个以外的所有线程,让它们的 futex 等待操作不再等待条件变量计数器,而是开始等待互斥锁状态。
重新排队等待线程并不会唤醒它。事实上,该线程甚至不会知道自己被重新排队了。遗憾的是,这会带来一些非常微妙的陷阱。
例如,还记得三状态互斥锁在醒来之后总是必须以正确状态(“已锁定且有等待者”)被锁定,以确保不会忘记其他等待者吗?这意味着我们在 Condvar::wait() 实现中不应再使用常规互斥锁加锁方法,因为它可能把互斥锁设为错误状态。
一个支持重新排队的条件变量实现,需要存储等待线程所用互斥锁的指针。否则,通知方法就不知道该把等待线程重新排队到哪个原子变量(互斥锁状态)上。这就是为什么条件变量通常不允许两个线程等待不同的互斥锁。即使许多条件变量实现并不使用重新排队,保留未来版本这样做的可能性仍然有用。
读写锁(Reader-Writer Lock)
是时候实现一个读写锁了!
回想一下,与互斥锁不同,读写锁支持两种锁定方式:读锁和写锁,有时也称为共享锁和独占锁。写锁与互斥锁加锁行为相同,一次只允许一个锁;而读锁允许多个读者同时持有锁。换句话说,它非常接近 Rust 中独占引用(&mut T)和共享引用(&T)的工作方式:同一时间只允许一个独占引用,或者允许任意数量的共享引用。
对于互斥锁,我们只需要跟踪它是否已锁定。不过对于读写锁,我们还需要知道当前持有多少个读者锁,以确保写锁只能在所有读者释放锁之后发生。
先从一个使用单个 AtomicU32 作为状态的 RwLock 结构体开始。我们会用它表示当前已获取的读锁数量,因此值为零意味着未锁定。为了表示写锁状态,使用特殊值 u32::MAX。
pub struct RwLock<T> {
/// The number of readers, or u32::MAX if write-locked.
state: AtomicU32,
value: UnsafeCell<T>,
}
对于 Mutex<T>,我们必须把它的 Sync 实现限制在实现了 Send 的 T 上,以确保它不能用来把例如 Rc 发送到另一个线程。对于新的 RwLock<T>,我们还需要额外要求 T 实现 Sync,因为多个读者可以同时访问数据:
unsafe impl<T> Sync for RwLock<T> where T: Send + Sync {}
因为 RwLock 可以用两种不同方式锁定,所以会有两个独立的锁定函数,各自对应自己的守卫类型:
impl<T> RwLock<T> {
pub const fn new(value: T) -> Self {
Self {
state: AtomicU32::new(0), // Unlocked.
value: UnsafeCell::new(value),
}
}
pub fn read(&self) -> ReadGuard<T> {
// ...
}
pub fn write(&self) -> WriteGuard<T> {
// ...
}
}
pub struct ReadGuard<'a, T> {
rwlock: &'a RwLock<T>,
}
pub struct WriteGuard<'a, T> {
rwlock: &'a RwLock<T>,
}
写守卫应该表现得像一个独占引用(&mut T),我们通过同时为它实现 Deref 和 DerefMut 来做到这一点:
impl<T> Deref for WriteGuard<'_, T> {
type Target = T;
fn deref(&self) -> &T {
unsafe { &*self.rwlock.value.get() }
}
}
impl<T> DerefMut for WriteGuard<'_, T> {
fn deref_mut(&mut self) -> &mut T {
unsafe { &mut *self.rwlock.value.get() }
}
}
不过读守卫应该只实现 Deref,不能实现 DerefMut,因为它没有对数据的独占访问权,因此表现得像共享引用(&T):
impl<T> Deref for ReadGuard<'_, T> {
type Target = T;
fn deref(&self) -> &T {
unsafe { &*self.rwlock.value.get() }
}
}
这些样板代码处理完后,进入有趣部分:加锁和解锁。
为了读锁定 RwLock,我们必须把状态加一,但前提是它尚未被写锁定。我们会使用 compare-and-exchange 循环来做到这一点。如果状态为 u32::MAX,意味着 RwLock 已被写锁定,就使用 wait() 操作睡眠,稍后重试。
pub fn read(&self) -> ReadGuard<T> {
let mut s = self.state.load(Relaxed);
loop {
if s < u32::MAX {
assert!(s != u32::MAX - 1, "too many readers");
match self.state.compare_exchange_weak(
s, s + 1, Acquire, Relaxed
) {
Ok(_) => return ReadGuard { rwlock: self },
Err(e) => s = e,
}
}
if s == u32::MAX {
wait(&self.state, u32::MAX);
s = self.state.load(Relaxed);
}
}
}
写锁定更简单;我们只需要把状态从零改为 u32::MAX,如果已经被锁定就 wait():
pub fn write(&self) -> WriteGuard<T> {
while let Err(s) = self.state.compare_exchange(
0, u32::MAX, Acquire, Relaxed
) {
// Wait while already locked.
wait(&self.state, s);
}
WriteGuard { rwlock: self }
}
注意,已锁定 RwLock 的具体状态值是变化的,但 wait() 操作要求我们给它一个精确值,用来与状态比较。这就是为什么我们把 compare-and-exchange 操作的返回值用于 wait() 操作。
解锁读者需要把状态减一。最后一个解锁 RwLock 的读者,也就是把状态从一改为零的读者,负责唤醒一个正在等待的写者,如果有的话。
唤醒一个线程就足够了,因为此时我们知道不可能有等待中的读者。读者根本没有理由在一个已被读锁定的 RwLock 上等待。
impl<T> Drop for ReadGuard<'_, T> {
fn drop(&mut self) {
if self.rwlock.state.fetch_sub(1, Release) == 1 {
// Wake up a waiting writer, if any.
wake_one(&self.rwlock.state);
}
}
}
写者必须把状态重置为零来解锁,随后应该唤醒一个等待写者,或者唤醒所有等待读者。
我们不知道是读者还是写者在等待,也没有方式只唤醒一个写者或只唤醒读者。因此只能唤醒所有线程:
impl<T> Drop for WriteGuard<'_, T> {
fn drop(&mut self) {
self.rwlock.state.store(0, Release);
// Wake up all waiting readers and writers.
wake_all(&self.rwlock.state);
}
}
这样就完成了!我们构建了一个非常简单但完全可用的读写锁。
接下来修复一些问题。
避免写者忙循环(Avoiding Busy-Looping Writers)
我们的实现有一个问题:写锁定可能意外导致忙循环。
如果有一个 RwLock,大量读者反复对它加锁和解锁,锁状态可能一直快速变化,上上下下。对于 write 方法来说,这会让锁状态在 compare-and-exchange 操作和随后的 wait() 操作之间变化的概率很高,尤其是当 wait() 操作直接实现为一个相对较慢的系统调用时。这意味着 wait() 操作经常会立即返回,尽管锁从未真正解锁;它只是拥有与预期不同数量的读者。
一个解决方案是使用另一个 AtomicU32 供写者等待,并且只在真正想唤醒写者时改变该原子的值。
来试一下,给 RwLock 增加一个新的 writer_wake_counter 字段:
pub struct RwLock<T> {
/// The number of readers, or u32::MAX if write-locked.
state: AtomicU32,
/// Incremented to wake up writers.
writer_wake_counter: AtomicU32, // New!
value: UnsafeCell<T>,
}
impl<T> RwLock<T> {
pub const fn new(value: T) -> Self {
Self {
state: AtomicU32::new(0),
writer_wake_counter: AtomicU32::new(0), // New!
value: UnsafeCell::new(value),
}
}
// ...
}
read 方法保持不变,但 write 方法现在需要等待新的原子变量。为了确保我们不会在看到 RwLock 被读锁定和真正进入睡眠之间错过任何通知,会使用类似条件变量实现中的模式:先检查 writer_wake_counter,再检查是否仍然想睡眠。
pub fn write(&self) -> WriteGuard<T> {
while self.state.compare_exchange(
0, u32::MAX, Acquire, Relaxed
).is_err() {
let w = self.writer_wake_counter.load(Acquire);
if self.state.load(Relaxed) != 0 {
// Wait if the RwLock is still locked, but only if
// there have been no wake signals since we checked.
wait(&self.writer_wake_counter, w);
}
}
WriteGuard { rwlock: self }
}
writer_wake_counter 的 acquire 加载操作会与解锁状态之后、唤醒等待写者之前执行的 release 递增操作形成 happens-before 关系:
impl<T> Drop for ReadGuard<'_, T> {
fn drop(&mut self) {
if self.rwlock.state.fetch_sub(1, Release) == 1 {
self.rwlock.writer_wake_counter.fetch_add(1, Release); // New!
wake_one(&self.rwlock.writer_wake_counter); // Changed!
}
}
}
happens-before 关系确保 write 方法不可能在观察到递增后的 writer_wake_counter 值之后,又仍然看到尚未递减的 state 值。否则,写锁定线程可能会在错过唤醒调用的同时,得出 RwLock 仍然被锁定的结论。
和之前一样,写解锁应该唤醒一个等待写者,或者唤醒所有等待读者。由于我们仍然不知道是写者还是读者在等待,所以必须同时唤醒一个等待写者(通过 wake_one)和所有等待读者(使用 wake_all):
impl<T> Drop for WriteGuard<'_, T> {
fn drop(&mut self) {
self.rwlock.state.store(0, Release);
self.rwlock.writer_wake_counter.fetch_add(1, Release); // New!
wake_one(&self.rwlock.writer_wake_counter); // New!
wake_all(&self.rwlock.state);
}
}
在某些操作系统上,唤醒操作背后的底层操作会返回它唤醒的线程数量。由于伪唤醒,它可能低估实际被唤醒的线程数,但返回值仍然可以作为优化依据。
例如,在上面的 drop 实现中,如果
wake_one()操作表明它确实唤醒了一个线程,我们就可以跳过wake_all()调用。
避免写者饥饿(Avoiding Writer Starvation)
RwLock 的一个常见使用场景是:有许多频繁读者,但写者很少,通常只有一个,而且写入并不频繁。例如,一个线程可能负责读取某些传感器输入,或周期性下载许多其他线程需要使用的新数据。
在这种场景下,很快就可能遇到一个称为写者饥饿的问题:写者永远没有机会锁定 RwLock,因为总有读者存在,让 RwLock 一直保持读锁定。
一个解决方案是,当有写者等待时,阻止任何新读者获取锁,即使 RwLock 仍然处于读锁定状态。这样,所有新读者都必须等到写者轮到自己为止,从而确保读者能访问到写者想分享的最新数据。
来实现它。
为此,需要跟踪是否存在等待写者。为了在状态变量中腾出空间表示这项信息,可以把读者计数乘以 2,并在有写者等待时加 1。这意味着状态 6 和 7 都表示存在三个活跃读锁:6 表示没有等待写者,7 表示有等待写者。
如果继续使用奇数 u32::MAX 作为写锁定状态,那么当状态为奇数时,读者必须等待;当状态为偶数时,读者可以通过把状态加二来获取读锁。
pub struct RwLock<T> {
/// The number of read locks times two, plus one if there's a writer waiting.
/// u32::MAX if write locked.
///
/// This means that readers may acquire the lock when
/// the state is even, but need to block when odd.
state: AtomicU32,
/// Incremented to wake up writers.
writer_wake_counter: AtomicU32,
value: UnsafeCell<T>,
}
我们需要修改 read 方法中的两个 if 语句,不再把状态与 u32::MAX 比较,而是检查状态为偶数还是奇数。还需要修改 assert 语句中的上界,并确保通过加二而不是加一来锁定。
pub fn read(&self) -> ReadGuard<T> {
let mut s = self.state.load(Relaxed);
loop {
if s % 2 == 0 { // Even.
assert!(s != u32::MAX - 2, "too many readers");
match self.state.compare_exchange_weak(
s, s + 2, Acquire, Relaxed
) {
Ok(_) => return ReadGuard { rwlock: self },
Err(e) => s = e,
}
}
if s % 2 == 1 { // Odd.
wait(&self.state, s);
s = self.state.load(Relaxed);
}
}
}
write 方法需要经历更大的改动。我们会使用 compare-and-exchange 循环,就像上面的 read 方法一样。如果状态是 0 或 1,意味着 RwLock 未锁定,我们会尝试把状态改成 u32::MAX 来写锁定它。否则,就必须等待。不过在等待之前,需要确保状态为奇数,以阻止新读者获取锁。确保状态为奇数之后,我们等待 writer_wake_counter 变量,同时确保锁没有在此期间被解锁。
代码如下:
pub fn write(&self) -> WriteGuard<T> {
let mut s = self.state.load(Relaxed);
loop {
// Try to lock if unlocked.
if s <= 1 {
match self.state.compare_exchange(
s, u32::MAX, Acquire, Relaxed
) {
Ok(_) => return WriteGuard { rwlock: self },
Err(e) => { s = e; continue; }
}
}
// Block new readers, by making sure the state is odd.
if s % 2 == 0 {
match self.state.compare_exchange(
s, s + 1, Relaxed, Relaxed
) {
Ok(_) => {}
Err(e) => { s = e; continue; }
}
}
// Wait, if it's still locked
let w = self.writer_wake_counter.load(Acquire);
s = self.state.load(Relaxed);
if s >= 2 {
wait(&self.writer_wake_counter, w);
s = self.state.load(Relaxed);
}
}
}
由于现在会跟踪是否存在等待写者,读解锁现在可以在不必要时跳过 wake_one() 调用:
impl<T> Drop for ReadGuard<'_, T> {
fn drop(&mut self) {
// Decrement the state by 2 to remove one read-lock.
if self.rwlock.state.fetch_sub(2, Release) == 3 {
// If we decremented from 3 to 1, that means
// the RwLock is now unlocked _and_ there is
// a waiting writer, which we wake up.
self.rwlock.writer_wake_counter.fetch_add(1, Release);
wake_one(&self.rwlock.writer_wake_counter);
}
}
}
当处于写锁定状态(状态为 u32::MAX)时,我们不会跟踪是否有任何线程在等待。因此,写解锁没有新信息可用,仍然保持相同:
impl<T> Drop for WriteGuard<'_, T> {
fn drop(&mut self) {
self.rwlock.state.store(0, Release);
self.rwlock.writer_wake_counter.fetch_add(1, Release);
wake_one(&self.rwlock.writer_wake_counter);
wake_all(&self.rwlock.state);
}
}
对于针对“频繁读取、偶尔写入”用例优化的读写锁来说,这已经相当可以接受,因为写锁定(以及因此写解锁)并不频繁。
不过,对于更通用的读写锁,继续优化绝对值得,以便让写锁定和写解锁性能接近高效三状态互斥锁的性能。这个有趣练习留给读者完成。
总结(Summary)
atomic-waitcrate 提供基础的类 futex 功能,可在所有主流操作系统的较新版本上工作。- 一个最小互斥锁实现只需要两个状态,类似第 4 章中的
SpinLock。 - 更高效的互斥锁会跟踪是否存在等待线程,从而避免不必要的唤醒操作。
- 睡眠前先自旋在某些情况下可能有益,但它高度依赖具体情况、操作系统和硬件。
- 一个最小条件变量只需要一个通知计数器,
Condvar::wait需要在解锁互斥锁前后都检查它。 - 条件变量可以跟踪等待线程数量,以避免不必要的唤醒操作。
- 避免从
Condvar::wait中伪唤醒可能很棘手,需要额外簿记。 - 一个最小读写锁只需要一个原子计数器作为状态。
- 一个额外的原子变量可以用于独立于读者唤醒写者。
- 为避免写者饥饿,需要额外状态,以便让等待写者优先于新读者。