第 24 章:F-代数(F-Algebras)
原文:Bartosz Milewski, Category Theory for Programmers, Scala Edition, Chapter 24. 原书 PDF、
.tex源文件及相关图像采用 CC BY-SA 4.0;本译文按同一许可发布。
我们已经见过幺半群的几种表述:作为集合、作为单对象范畴、作为幺半范畴中的对象。这个简单概念还能榨出多少东西?
让我们试试看。取幺半群作为集合 m 的定义,它配有一对函数:
mu :: m x m -> m
eta :: 1 -> m
这里的 1 是 Set 中的终对象,也就是单元素集合。第一个函数定义乘法(它接收一对元素并返回它们的积),第二个函数从 m 中选出单位元。并非任意选择两个具有这些签名的函数都会得到一个幺半群。为此,还需要施加额外条件:结合律和单位律。不过,我们先暂时忘掉这些,只考虑“潜在的幺半群”。一对函数是两个函数集合的笛卡尔积中的一个元素。我们知道,这些集合可以表示为指数对象:
mu in m^(m x m)
eta in m^1
这两个集合的笛卡尔积是:
m^(m x m) x m^1
使用一点中学代数(它在每个笛卡尔闭范畴中都成立),可以把它改写为:
m^(m x m + 1)
加号表示 Set 中的余积。我们刚刚把一对函数替换成了一个函数,也就是下面这个集合的元素:
m x m + 1 -> m
这个函数集合中的任意元素都是一个潜在的幺半群。
这种表述的美妙之处在于,它会导向有趣的推广。比如,如何用这种语言描述群?群是一个幺半群,再加上一个为每个元素指定逆元的函数。后者是类型为 m -> m 的函数。例如,整数以加法作为二元运算、以零作为单位元、以取负作为逆元,构成一个群。为了定义群,我们会从三个函数开始:
m x m -> m
m -> m
1 -> m
和之前一样,可以把这些三元组全部合并进一个函数集合:
m x m + m + 1 -> m
我们从一个二元运算符(加法)、一个一元运算符(取负)和一个零元运算符(恒等元,这里是零)出发,把它们合并成了一个函数。所有具有这个签名的函数都定义潜在的群。
还可以继续这样做。例如,要定义环,我们会再加入一个二元运算符和一个零元运算符,依此类推。每次最终都会得到一个函数类型,其左侧是若干幂的和(也可能包括零次幂,也就是终对象),右侧则是集合本身。
现在可以开始疯狂推广了。首先,可以用对象替换集合,用态射替换函数。我们可以把 n 元运算符定义为来自 n 元积的态射。这意味着我们需要一个支持有限积的范畴。对于零元运算符,需要终对象存在。因此我们需要一个笛卡尔范畴。为了组合这些运算符,需要指数对象,也就是笛卡尔闭范畴。最后,为了完成这些代数把戏,还需要余积。
或者,我们也可以忘掉公式推导过程,只关注最终产物。态射左侧的“积之和”定义了一个自函子。如果改为选择任意自函子 F 会怎样?在这种情况下,我们不必给范畴施加任何约束。得到的东西称为 F-代数。
F-代数是由一个自函子 F、一个对象 a 和一个态射组成的三元组:
F a -> a
这个对象通常称为载体、底层对象,或者在编程语境中称为载体类型。这个态射通常称为求值函数或结构映射。可以把函子 F 理解为形成表达式,把态射理解为求值这些表达式。
下面是 F-代数的 Haskell 定义:
type Algebra f a = f a -> a
type Algebra[F[_], A] = F[A] => A
它把代数等同于它的求值函数。
在幺半群例子中,相关函子是:
data MonF a = MEmpty | MAppend a a
sealed trait MonF[+A]
case object MEmpty extends MonF[Nothing]
case class MAppend[A](m: A, n: A) extends MonF[A]
这是 Haskell 对 1 + a x a 的表示(记住代数数据结构)。环可以用下面的函子定义:
data RingF a = RZero
| ROne
| RAdd a a
| RMul a a
| RNeg a
sealed trait RingF[+A]
case object RZero extends RingF[Nothing]
case object ROne extends RingF[Nothing]
case class RAdd[A](m: A, n: A) extends RingF[A]
case class RMul[A](m: A, n: A) extends RingF[A]
case class RNeg[A](n: A) extends RingF[A]
这对应 1 + 1 + a x a + a x a + a。
整数集合是一个环的例子。可以选择 Integer 作为载体类型,并把求值函数定义为:
evalZ :: Algebra RingF Integer
evalZ RZero = 0
evalZ ROne = 1
evalZ (RAdd m n) = m + n
evalZ (RMul m n) = m * n
evalZ (RNeg n) = -n
def evalZ: Algebra[RingF, Int] = {
case RZero => 0
case ROne => 1
case RAdd(m, n) => m + n
case RMul(m, n) => m * n
case RNeg(n) => -n
}
基于同一个函子 RingF,还可以有更多 F-代数。例如,多项式构成环,方阵也构成环。
如你所见,函子的角色是生成表达式,而这些表达式可以用代数的求值器求值。到目前为止,我们只见过非常简单的表达式。我们经常对更复杂的表达式感兴趣,而它们可以用递归定义。
24.1 递归(Recursion)
生成任意表达式树的一种方式,是把函子定义中的变量 a 替换为递归。例如,环中的任意表达式由下面这种树状数据结构生成:
data Expr = RZero
| ROne
| RAdd Expr Expr
| RMul Expr Expr
| RNeg Expr
sealed trait Expr
case object RZero extends Expr
case object ROne extends Expr
case class RAdd(e1: Expr, e2: Expr) extends Expr
case class RMul(e1: Expr, e2: Expr) extends Expr
case class RNeg(e: Expr) extends Expr
可以把原来的环求值器替换为递归版本:
evalZ :: Expr -> Integer
evalZ RZero = 0
evalZ ROne = 1
evalZ (RAdd e1 e2) = evalZ e1 + evalZ e2
evalZ (RMul e1 e2) = evalZ e1 * evalZ e2
evalZ (RNeg e) = -(evalZ e)
def evalZ: Expr => Int = {
case RZero => 0
case ROne => 1
case RAdd(e1, e2) => evalZ(e1) + evalZ(e2)
case RMul(e1, e2) => evalZ(e1) * evalZ(e2)
case RNeg(e) => -evalZ(e)
}
这仍然不太实用,因为我们不得不把所有整数都表示为若干个一的和,但必要时也能凑合。
可是,怎样用 F-代数的语言描述表达式树?我们必须以某种方式形式化这个过程:把函子定义中的自由类型变量,递归地替换为替换结果。想象一步步完成它。首先,把深度为 1 的树定义为:
type RingF1 a = RingF (RingF a)
type RingF1[A] = RingF[RingF[A]]
我们正在用 RingF a 生成的深度为 0 的树,填入 RingF 定义中的孔。深度为 2 的树类似地得到:
type RingF2 a = RingF (RingF (RingF a))
type RingF2[A] = RingF[RingF[RingF[A]]]
也可以写成:
type RingF2 a = RingF (RingF1 a)
type RingF2[A] = RingF[RingF1[A]]
继续这个过程,可以写出一个符号方程:
type RingFn+1 a = RingF (RingFn a)
从概念上说,把这个过程重复无穷多次后,就会得到我们的 Expr。注意,Expr 不依赖 a。旅程的起点并不重要,最后总会抵达同一个地方。对于任意范畴中的任意自函子来说,这并不总成立,但在范畴 Set 中情况很好。
当然,这只是一个手挥式论证,稍后我会让它更严格。
把自函子应用无穷多次会产生一个不动点,也就是定义为下面形式的对象:
Fix f = f (Fix f)
这个定义背后的直觉是:既然我们已经把 f 应用无穷多次才得到 Fix f,那么再多应用一次也不会改变任何东西。在 Haskell 中,不动点的定义是:
newtype Fix f = Fix (f (Fix f))
case class Fix[F[_]](x: F[Fix[F]])
如果构造器的名字不同于被定义类型的名字,也许会更易读,例如:
newtype Fix f = In (f (Fix f))
sealed trait Fix[F[_]]
case class In[F[_]](f: F[Fix[F]])
不过我会沿用公认记法。构造器 Fix(或者你喜欢的话,In)可以看成一个函数:
Fix :: f (Fix f) -> Fix f
object Fix {
def apply[F[_]](f: F[Fix[F]]): Fix[F] = new Fix(f)
}
还有一个函数可以剥掉一层函子应用:
unFix :: Fix f -> f (Fix f)
unFix (Fix x) = x
def unFix[F[_]]: Fix[F] => F[Fix[F]] = {
case Fix(x) => x
}
这两个函数互为逆函数。后面还会用到它们。
24.2 F-代数的范畴(Category of F-Algebras)
这是书中最古老的技巧:每当你想出一种构造新对象的方式,就看看它们是否形成一个范畴。不出所料,给定自函子 F 上的代数会形成一个范畴。这个范畴中的对象是代数,也就是由载体对象 a 和态射 F a -> a 构成的 pair,二者都来自原范畴 C。
为了补全图景,还必须定义 F-代数范畴中的态射。态射必须把一个代数 (a, f) 映射到另一个代数 (b, g)。我们把它定义为一个映射载体的态射 m,也就是原范畴中从 a 到 b 的态射。并不是任意态射都可以:我们希望它与两个求值器兼容。(我们把这种保持结构的态射称为同态。)下面是 F-代数同态的定义方式。首先注意,可以把 m 提升为映射:
F m :: F a -> F b
然后接上 g 到达 b。等价地,也可以用 f 从 F a 到 a,再接上 m。我们希望这两条路径相等:
g . F m = m . f
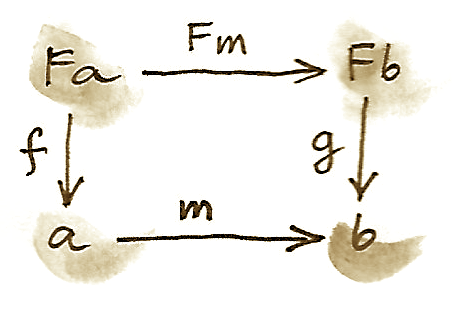
很容易说服自己,这确实是一个范畴(提示:来自 C 的恒等态射照样可用,同态的组合仍然是同态)。
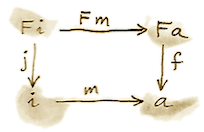
F-代数范畴中的初始对象,如果存在的话,称为初始代数。把这个初始代数的载体称为 i,把它的求值器称为 j :: F i -> i。事实证明,初始代数的求值器 j 是同构。这个结果称为 Lambek 定理。
证明依赖初始对象的定义:从初始对象到任意其他 F-代数都存在唯一同态 m。由于 m 是同态,下面的图必须交换:
现在构造一个载体为 F i 的代数。这样一个代数的求值器必须是从 F (F i) 到 F i 的态射。只要提升 j,就很容易构造这样的求值器:
F j :: F (F i) -> F i
因为 (i, j) 是初始代数,必定存在唯一同态 m 从它到 (F i, F j)。下面的图必须交换:
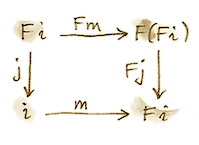
但我们还有这个平凡交换的图(两条路径相同):
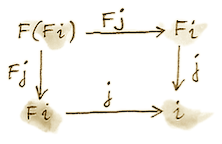
它可以解释为说明 j 是一个代数同态,把 (F i, F j) 映射到 (i, j)。可以把这两个图粘在一起得到:
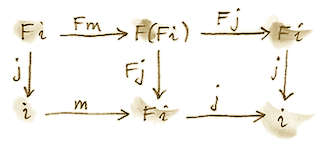
这个图又可以解释为说明 j . m 是一个代数同态。只不过在这里,两个代数是同一个。而且,因为 (i, j) 是初始的,从它到自身只能有一个同态,那就是恒等态射 id_i,而我们知道它确实是一个代数同态。因此 j . m = id_i。利用这一事实以及左侧图的交换性质,可以证明 m . j = id_(F i)。这说明 m 是 j 的逆,因此 j 是 F i 与 i 之间的同构:
F i ~= i
这只是在说 i 是 F 的不动点。这就是原先那个手挥式论证背后的正式证明。
回到 Haskell:我们把 i 识别为 Fix f,把 j 识别为构造器 Fix,把它的逆识别为 unFix。Lambek 定理中的同构告诉我们,为了得到初始代数,需要取函子 f,并把它的参数 a 替换为 Fix f。我们也看到了为什么这个不动点不依赖于 a。
24.3 自然数(Natural Numbers)
自然数也可以定义为 F-代数。起点是一对态射:
zero :: 1 -> N
succ :: N -> N
第一个选出零,第二个把所有数映射到它们的后继。和之前一样,可以把二者合并成一个:
1 + N -> N
左侧定义了一个函子,在 Haskell 中可以写成:
data NatF a = ZeroF | SuccF a
sealed trait NatF[+A]
case object ZeroF extends NatF[Nothing]
case class SuccF[A](a: A) extends NatF[A]
这个函子的不动点(它生成的初始代数)可以在 Haskell 中编码为:
data Nat = Zero | Succ Nat
sealed trait Nat
case object Zero extends Nat
case class Succ(n: Nat) extends Nat
自然数要么是零,要么是另一个数的后继。这称为自然数的 Peano 表示。
24.4 Catamorphism
让我们用 Haskell 记法重写初始性条件。我们把初始代数称为 Fix f,它的求值器是构造器 Fix。从初始代数到同一函子上的任意其他代数,都存在唯一态射 m。选择一个载体为 a、求值器为 alg 的代数。
顺便注意一下 m 是什么:它是不动点的求值器,也就是整棵递归表达式树的求值器。让我们寻找一种通用方式来实现它。
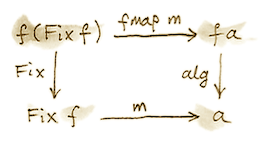
Lambek 定理告诉我们,构造器 Fix 是一个同构。我们把它的逆称为 unFix。因此可以把这个图中的一条箭头翻转过来:
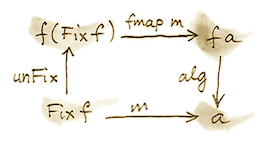
写出这个图的交换条件:
m = alg . fmap m . unFix
可以把这个方程解释为 m 的递归定义。对于使用函子 f 创建的任意有限树,这个递归一定会终止。注意 fmap m 作用在函子 f 的顶层下面,换句话说,它作用在原始树的子节点上。子节点总是比原始树浅一层。
当我们把 m 应用于用 Fix f 构造的树时,会发生下面这些事。unFix 会剥掉构造器,暴露树的顶层。然后我们把 m 应用于顶层节点的所有子节点。这会产生类型为 a 的结果。最后,我们应用非递归求值器 alg 来组合这些结果。关键点是,我们的求值器 alg 是一个简单的非递归函数。
既然可以对任意代数 alg 这样做,那么定义一个高阶函数就很有意义:它接收代数作为参数,并给出我们称为 m 的函数。这个高阶函数称为 catamorphism:
cata :: Functor f => (f a -> a) -> Fix f -> a
cata alg = alg . fmap (cata alg) . unFix
def cata[F[_], A](alg: F[A] => A)
(implicit F: Functor[F]): Fix[F] => A =
alg.compose(F.fmap(cata(alg)) _ compose unFix)
看一个例子。取定义自然数的函子:
data NatF a = ZeroF | SuccF a
sealed trait NatF[+A]
case object ZeroF extends NatF[Nothing]
case class SuccF[A](a: A) extends NatF[A]
选择 (Int, Int) 作为载体类型,并把代数定义为:
fib :: NatF (Int, Int) -> (Int, Int)
fib ZeroF = (1, 1)
fib (SuccF (m, n)) = (n, m + n)
def fib: NatF[(Int, Int)] => (Int, Int) = {
case ZeroF => (1, 1)
case SuccF((m, n)) => (n, m + n)
}
很容易说服自己,这个代数的 catamorphism,也就是 cata fib,会计算 Fibonacci 数。
一般来说,NatF 的代数定义一个递推关系:当前元素的值由前一个元素给出。catamorphism 随后求出这个序列的第 n 个元素。
24.5 折叠(Folds)
e 的列表是下面这个函子的初始代数:
data ListF e a = NilF | ConsF e a
sealed trait ListF[+E, +A]
case object NilF extends ListF[Nothing, Nothing]
case class ConsF[E, A](h: E, t: A) extends ListF[E, A]
确实,把变量 a 替换为递归结果(我们称为 List e)后,得到:
data List e = Nil | Cons e (List e)
sealed trait List[+E]
case object Nil extends List[Nothing]
case class Cons[E](h: E, t: List[E]) extends List[E]
列表函子的代数会选择某个特定载体类型,并定义一个对两个构造器进行模式匹配的函数。它对 NilF 的取值告诉我们如何求值空列表,它对 ConsF 的取值告诉我们如何把当前元素与之前累积的值组合起来。
例如,下面这个代数可以用来计算列表长度(载体类型是 Int):
lenAlg :: ListF e Int -> Int
lenAlg (ConsF e n) = n + 1
lenAlg NilF = 0
def lenAlg[E]: ListF[E, Int] => Int = {
case ConsF(e, n) => n + 1
case NilF => 0
}
确实,得到的 catamorphism cata lenAlg 会计算列表长度。注意,这个求值器是两部分的组合:(1)一个接收列表元素和累加器并返回新累加器的函数;(2)一个初始值,这里是零。值的类型和累加器的类型由载体类型给出。
把它与传统 Haskell 定义比较:
length = foldr (\e n -> n + 1) 0
def length[E](l: List[E]): Int =
l.foldRight(0)((e, n) => n + 1)
foldr 的两个参数正好就是这个代数的两个分量。
再试一个例子:
sumAlg :: ListF Double Double -> Double
sumAlg (ConsF e s) = e + s
sumAlg NilF = 0.0
def sumAlg: ListF[Double, Double] => Double = {
case ConsF(e, s) => e + s
case NilF => 0.0
}
再次与下面定义比较:
sum = foldr (\e s -> e + s) 0.0
def sum(l: List[Double]): Double =
l.foldRight(0.0)((e, s) => e + s)
如你所见,foldr 只是 catamorphism 针对列表的一种方便特化。
24.6 余代数(Coalgebras)
照例,我们有 F-余代数的对偶构造,其中态射方向被反转:
a -> F a
给定函子上的余代数也会形成一个范畴,同态会保持余代数结构。这个范畴中的终对象 (t, u) 称为终余代数(terminal coalgebra,或 final coalgebra)。对于任意其他代数 (a, f),都存在唯一同态 m 使下面的图交换:
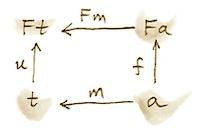
终余代数是函子的不动点,其含义是态射 u :: t -> F t 是同构(余代数版本的 Lambek 定理):
F t ~= t
在编程中,终余代数通常被解释为生成(可能无限的)数据结构或转换系统的配方。
正如 catamorphism 可以用来求值初始代数,anamorphism 可以用来对终余代数做余求值:
ana :: Functor f => (a -> f a) -> a -> Fix f
ana coalg = Fix . fmap (ana coalg) . coalg
def ana[F[_], A](coalg: A => F[A])
(implicit F: Functor[F]): A => Fix[F] =
(Fix.apply[F] _).compose(F.fmap(ana(coalg)) _ compose coalg)
余代数的一个典型例子基于这样一个函子:它的不动点是由类型 e 的元素组成的无限流。这个函子是:
data StreamF e a = StreamF e a
deriving Functor
case class StreamF[E, A](h: E, t: A)
implicit def streamFFunctor[E] = new Functor[StreamF[E, ?]] {
def fmap[A, B](f: A => B)(fa: StreamF[E, A]): StreamF[E, B] =
...
}
它的不动点是:
data Stream e = Stream e (Stream e)
case class Stream[E](h: E, t: Stream[E])
StreamF e 的余代数是一个函数:它接收类型为 a 的种子,并产生一个 pair(StreamF 只是 pair 的花哨名字),这个 pair 由一个元素和下一个种子组成。
你很容易生成一些产生无限序列的简单余代数,比如平方数列表或倒数列表。
更有趣的例子是一个产生素数列表的余代数。技巧是用无限列表作为载体。我们的起始种子是列表 [2..]。下一个种子会是这个列表的尾部,并移除所有 2 的倍数。它是从 3 开始的奇数列表。下一步,我们取这个列表的尾部并移除所有 3 的倍数,依此类推。你也许已经认出了 Eratosthenes 筛法的雏形。
这个余代数由下面的函数实现:
era :: [Int] -> StreamF Int [Int]
era (p : ns) = StreamF p (filter (notdiv p) ns)
where notdiv p n = n `mod` p /= 0
def era: List[Int] => StreamF[Int, List[Int]] = {
case p :: ns =>
def notdiv(p: Int)(n: Int): Boolean =
n % p != 0
StreamF(p, ns.filter(notdiv(p)))
}
这个余代数的 anamorphism 会生成素数列表:
primes = ana era [2..]
// just imagine that the list is infinite
def primes =
ana(era)(streamFFunctor)((1 to 10).toList)
流是一个无限列表,所以应该可以把它转换成 Haskell 列表。为此,可以使用同一个函子 StreamF 形成一个代数,并在它上面运行 catamorphism。例如,下面这个 catamorphism 会把流转换为列表:
toListC :: Fix (StreamF e) -> [e]
toListC = cata al
where al :: StreamF e [e] -> [e]
al (StreamF e a) = e : a
def toListC[E]: Fix[StreamF[E, ?]] => List[E] = {
def al: StreamF[E, List[E]] => List[E] = {
case StreamF(e, a) => e :: a
}
cata[StreamF[E, ?], List[E]](al)
}
这里,同一个不动点同时是同一自函子的初始代数和终余代数。在任意范畴中并不总是这样。一般来说,一个自函子可能有许多不动点,也可能没有不动点。初始代数是所谓最小不动点,终余代数是最大不动点。不过在 Haskell 中,二者由同一个公式定义,因此它们重合。
列表的 anamorphism 称为 unfold。为了创建有限列表,会修改函子,让它产生一个 Maybe pair:
unfoldr :: (b -> Maybe (a, b)) -> b -> [a]
def unfoldr[A, B]: (B => Option[(A, B)]) => B => List[A]
Nothing 值会终止列表生成。
余代数的一个有趣例子与 lens 有关。lens 可以表示为 getter 和 setter 的 pair:
set :: a -> s -> a
get :: a -> s
def set[A, S]: A => S => A
def get[A, S]: A => S
这里,a 通常是某个 product 数据类型,其中有一个类型为 s 的字段。getter 取回这个字段的值,setter 用新值替换这个字段。这两个函数可以合并成一个:
a -> (s, s -> a)
A => ((S, S => A))
还可以进一步把这个函数改写为:
a -> Store s a
A => Store[S, A]
其中我们已经定义了一个函子:
data Store s a = Store (s -> a) s
case class Store[S, A](run: S => A, s: S)
注意,这不是一个由和与积构成的简单代数函子。它涉及一个指数 a^s。
lens 是这个函子的余代数,其载体类型为 a。我们之前看到过,Store s 也是一个余单子。事实证明,行为良好的 lens 对应于与余单子结构兼容的余代数。下一节会继续讨论这一点。
24.7 挑战(Challenges)
- 为单变量多项式环实现求值函数。可以把多项式表示为按
x幂次排列的系数列表。例如,4x^2 - 1会表示为(从零次幂开始)[-1, 0, 4]。 - 把前面的构造推广到多个独立变量的多项式,例如
x^2 y - 3y^3 z。 - 为
2 x 2矩阵环实现代数。 - 定义一个余代数,其 anamorphism 会产生自然数平方数列表。
- 使用
unfoldr生成前n个素数的列表。