第 12 章 - 解析像素数据(Parsing pixel data)
本章内容包括:
- 从零开始为文本编写解析器
- 组合带有效果的动作
- Functor、Applicative 和 Monad 背后的理论
- 使用 Attoparsec 库为二进制数据构建解析器
前几章中,我们已经处理过按特定方式读取数据的任务,无论是文件中的行,还是 CSV 这样更复杂的格式。为了达到目的,我们创建了针对当前任务量身定制的自定义读取函数。不过,在这类情形中,这通常不是我们会采用的方式。通常,无论使用哪门语言,都会构造某种解析器来完成这件事。在 Haskell 中,解析器开发几乎是一种独特体验:它们能够非常干净地组合起来,用简单构件搭建更大的解析器。
本章会编写自己的简化解析器库,用于读取 PNM 文件。PNM 是一组简单的图像文件格式。这个过程不仅会教我们如何组合带有效果的动作,也会教我们如何优雅处理途中可能遇到的错误和失败。我们会通过 applicative 和 monad 来做到这一点,并理解它们如何工作,以及为什么它们是 Haskell 中必不可少的构件。之后,我们会认识 Attoparsec,这是一个广泛使用的解析器组合子库,它能帮助我们为图像文件创建高性能解析器。
本章先定义要解决的问题。然后,我们会构建自己的解析器库,开始解决这个任务。最后,我们会使用现成的先进解析器库,把学到的知识应用起来。
12.1 编写解析器(Writing a parser)
自摄影诞生以来,人们不仅关心如何捕获真实世界,也关心如何在图像创建之后修改它们。这不仅适用于摄影,也适用于任何视觉艺术。在现代世界中,摄影师和艺术家都很幸运,因为他们的大部分工作已经转移到数字领域。在那里,图像不过是位和字节。巧合的是,计算机正是转换和揉捏这些位与字节的大师,可以用它们创造出全新的东西。
此外,作为程序员,我们有能力让计算机做任何我们告诉它们做的事。所以,是时候编写能够转换图像数据的软件了!为此,需要选择想支持哪些图像格式。如今,有大量高度压缩且复杂的格式,但我们希望让图像处理库保持老派:为 Netpbm 项目的格式编写它。
12.1.1 来自过去的可移植图像(Portable images from the past)
在 20 世纪 80 年代,共享图像并不像把它们上传到云端那样直接。如果想分享什么东西,就必须通过电子邮件,而当时的电子邮件并不适合发送二进制数据。如果想发送图像,它们必须是可靠的 7 位 ASCII。为了方便这件事,Jef Poskanzer 发明了一组文件格式,它们可以用 ASCII 或二进制形式分发,并且没有多余元数据,因此易于解析和理解。
这些格式有时被称为 portable anymap format(PNM),包括可移植像素图格式(PPM)、可移植灰度图格式(PGM)和可移植位图格式(PBM)。它们可用于存储彩色、灰度和黑白像素数据。还有一套名为 Netpbm 的工具可以处理这些格式,让你在更常用的格式和这些可移植格式之间互相转换。
快速看看这些格式如何工作。它们都包含一个头部,头部总是包含一个 magic number。这个数字指定正在使用哪种格式,以及其编码是 ASCII 还是二进制。文件扩展名通常不用于判断正在处理的格式类型。头部后面接着是图像的宽度和高度。对于 PPM 和 PGM 格式,第四个值表示单个数据点的最大值。看看下面代码清单中的例子。
代码清单 12.1 一个头部带注释的简单 PBM 文件
P1 # PBM in ASCII
2 2 # 2x2 pixel size
1 0
0 1
可以看到,头部可以包含由 # 表示的注释。无论 magic number 是什么,头部也总是 ASCII。这个例子指定了一个宽 2 像素、高 2 像素的位图图像。后续二进制数据表示这些像素的值。把得到的图像放大后,可以得到图 12.1 所示的结果。
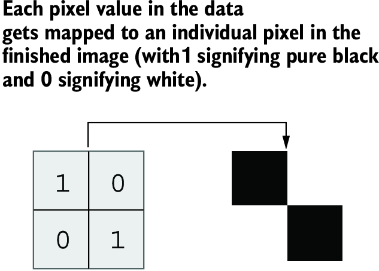
图 12.1 一个放大 150% 的可移植位图示例
表 12.1 概览了文件格式、它们的 magic number,以及它们分别包含的数据。可以看到,每种格式都有两个 magic number,分别对应 ASCII 版本和二进制版本。
注意 PNM 格式中的头部总是使用 ASCII 编码!
对于位图和灰度图文件,头部后的单个值对应图像中的单个像素。不过,在像素图格式中,一个像素由三个值组成,分别表示红、绿、蓝通道。
表 12.1 PNM 格式 magic number 概览
| 格式 | ASCII magic number | 二进制 magic number | 扩展名 | 图像数据(单个像素) |
|---|---|---|---|---|
| 可移植位图格式(PBM) | P1 | P4 | .pbm | 0(白)或 1(黑) |
| 可移植灰度图格式(PGM) | P2 | P5 | .pgm | 从 0 到 maximum value(灰度),其中 maximum value 在头部给出 |
| 可移植像素图格式(PPM) | P3 | P6 | .ppm | 每个 RGB 通道从 0 到 maximum value,其中 maximum value 在头部给出 |
可以在代码清单 12.2 中看到头部中最大值的用法。头部元素也没有严格规则。它们可以放在单行中,但常见做法是把 magic number、图像尺寸和最大值分开放在不同行中。图像数据也可以分隔到多行,但不是必须。为了可读性,推荐文件中最大行长度为 76;但再次强调,如果我们只关心存储给计算机读取的数据,就不一定要遵守这个建议。
代码清单 12.2 一个头部带注释的简单 PGM 文件
P2 10 14 # PGM in ASCII with 10x14 pixels
9 # Values from 0 (black) to 9 (white)
9 6 3 4 9 9 9 9 9 9
8 4 2 2 6 9 9 9 9 9
8 6 9 5 4 9 9 9 9 9
8 9 9 9 4 9 9 9 9 9
9 9 9 9 4 7 9 9 9 9
9 9 9 9 3 6 9 9 9 9
9 9 9 6 1 3 9 9 9 9
9 9 9 4 0 3 8 9 9 9
9 9 7 0 4 4 8 9 9 9
9 9 4 1 7 5 6 9 9 9
9 7 1 3 9 6 5 9 9 8
9 5 0 7 9 8 3 8 9 6
8 1 2 8 9 8 3 3 4 4
5 2 5 9 9 9 7 2 1 7
上述清单中的 PGM 文件得到的图像结果如图 12.2 所示。使用 Netpbm 和 ImageMagick 工具,可以轻松在这些文件和 jpeg、png 等更常见文件格式之间相互转换。
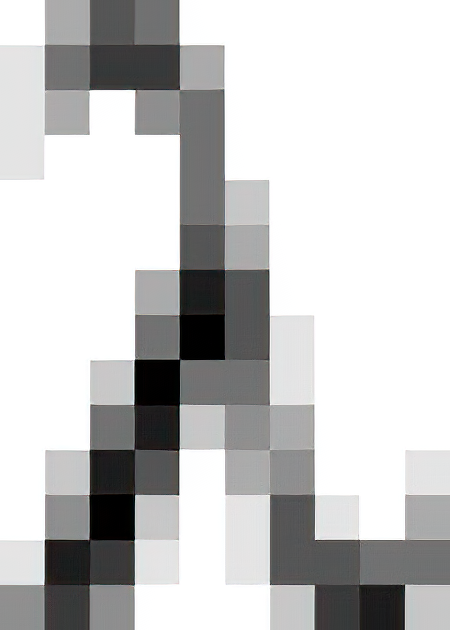
图 12.2 放大 150% 的可移植灰度图示例
现在已经大致了解这些文件格式如何工作,可以思考如何在程序中读取这些文件了。
12.1.2 如何解析文件(How to parse a file)
读取信息,无论是文件、网络包还是串口数据,都要求我们描述一种预期结构。无论读取 CSV 文件、编程语言源代码,还是本章中的图像文件,都是如此。描述这种结构通常通过解析器完成。解析器是程序或程序的一部分,用于把字符或字节串翻译成该程序可以解释的数据。解析器有两个核心职责:
理论上,可以通过编写简单函数来实现这些目标,就像第 8 章解析 CSV 文件时那样。缺点是,仅从函数定义很难理解解析器的期望。我们不想重复这一点,而且正在用 Haskell 处理解析,所以还有几个额外目标:
因此,让我们在 Haskell 中编写一个通用解析器。使用 stack new 新建项目,并添加以下默认语言扩展:
default-extensions:
- OverloadedStrings
- RecordWildCards
- NamedFieldPuns
要开始编写解析器,必须先为它想出一个类型。随着需求出现,这个类型会逐步变化。
由于解析器会把输入转换成某种本地数据类型,解析器可以只是一个简单函数:
type Parser a = Text -> a
在简化解析器中,我们会处理 Data.Text 中的 Text 数据类型。如果想为 PNM 格式的 magic number 编写解析器,可以这样做:
module Graphics.PNM.Types where
import Parser.Core
data MagicNumber = P1 | P2 | P3 | P4 | P5 | P6 deriving (Eq, Show)
magicNumberP :: Parser MagicNumber
magicNumberP "P1" = P1
magicNumberP "P2" = P2
magicNumberP "P3" = P3
magicNumberP "P4" = P4
magicNumberP "P5" = P5
magicNumberP "P6" = P6
名为 magicNumberP 的解析器可以从 Text 读取 magic number。本章后续都假设整个项目启用了 OverloadedStrings 语言扩展。不过,很明显,这个解析器使用了非穷尽模式匹配,解析失败时会让程序崩溃。因此,类型应该编码失败的可能性。
注意 就像通常会在变量名中给
Maybe和Either值加m前缀一样,给解析器加P后缀也很常见。
正如前几章所学,可以用 Either 类型做到这一点。这也让解析器可以返回错误消息。可以这样更新类型:
type ErrorMessage = String
type Parser a = Text -> Either ErrorMessage a
使用这个新解析器解析 magic number 看起来如下:
magicNumberP :: Parser MagicNumber
magicNumberP "P1" = Right P1
magicNumberP "P2" = Right P2
magicNumberP "P3" = Right P3
magicNumberP "P4" = Right P4
magicNumberP "P5" = Right P5
magicNumberP "P6" = Right P6
magicNumberP t =
Left $
"Could not parse \""
++ T.unpack t
++ "\" as magic number"
这个函数在解析失败时不再崩溃,而是返回错误消息:
ghci> magicNumberP "P3"
Right P3
ghci> magicNumberP "Not a magic number"
Left "Could not parse \"Not a magic number\" as magic number"
这似乎能工作,但会遇到一个问题:如何把这个解析器与其他解析器组合起来,以完整读取 PNM 文件头部?我们需要能够把头部的不同部分解析成不同类型,同时忽略空白、换行和注释。图 12.3 展示了这一点。
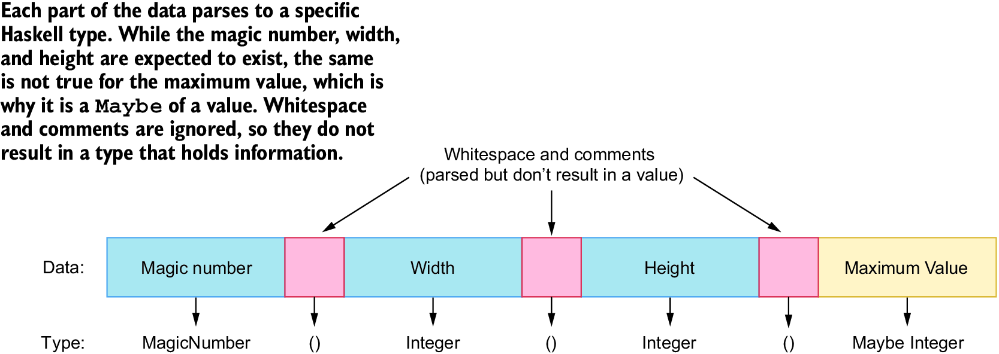
图 12.3 展示从文件中解析出的信息、哪些部分会得到值以及哪些部分会被忽略的映射
magicNumberP 解析器能够解析头部的第一部分,但之后无法继续解析文件中的后续部分。原因是解析器没有返回剩余输入,无法让我们继续解析。可以通过让解析器不仅返回结果,还返回解析之后剩余的输入来解决这个问题。这样就能把剩余输入传给另一个解析器。最终解析器类型如下所示。ParseResult 包含剩余输入和运行解析器得到的解析结果。另外,我们把解析器包装在一个 newtype 中,并提供一个字段访问内部函数。
代码清单 12.3 解析器数据类型
type ErrorMessage = String -- #1
type ParseResult a = Either ErrorMessage (T.Text, a) -- #2
newtype Parser a = Parser{runParser :: T.Text -> ParseResult a} -- #3
- #1 为错误消息定义类型同义词
- #2 为解析器返回结果定义类型同义词
- #3 定义新的解析器类型
本章后续都假设模块以限定名 T 导入了 Data.Text。现在可以重写 magicNumberP,但在那之前,应该先思考解析器更基础的构件。我们已经知道,必须为 magic number 解析固定字符串,那么为什么不创建一个通用字符串解析器呢?
可以创建一个函数,读取与指定字符串长度相同的字符数,并将其与该字符串比较。如果比较成功,就从输入中丢弃这些字符并返回结果。该函数如下所示。
代码清单 12.4 固定字符串解析器
string :: T.Text -> Parser T.Text
string str =
Parser $ \t ->
if T.take (T.length str) t == str -- #1
then Right (T.drop (T.length str) t, str) -- #2
else Left $ "failed to parse \"" ++ T.unpack str ++ "\"" -- #3
- #1 将输入开头与指定字符串比较
- #2 返回解析出的字符串,以及去掉已解析字符后的剩余输入
- #3 返回完整输入和错误消息
这个解析器现在可以解析头部中的 magic number:
ghci> runParser (string "P1") "P1 100 100"
(" 100 100",Right "P1")
ghci> runParser (string "P1") "P2 100 100"
("P2 100 100",Left "failed to parse \"P1\"")
可以看到,如果输入不是以指定字符串开头,解析器会失败;解析成功时,它会返回剩余输入。不过,这还不足以定义 MagicNumber 解析器,因为仍然需要把解析出的字符串转换成 Haskell 类型。我们想做的是把 Parser Text 转换为 Parser MagicNumber。这看起来类似 Functor 能做的事情。确实,这里正需要一个 Functor Parser 实例,因为我们想转换解析器内部的值。
在实例所需的 fmap 定义中,可以利用 Functor Either 和 Functor ((,) a) 实例已经存在这一事实。这个实例定义如下所示。
代码清单 12.5 解析器的 Functor 实例
instance Functor Parser where
fmap f p = Parser $ \t -> fmap (fmap f) (runParser p t) -- #1
- #1 在某个输入上运行解析器,并只把指定函数映射到有效结果上
为什么这能工作?由于 fmap 会作用于 Either 的 Right 值,也会作用于元组的最后一个值,所以可以转换解析结果的类型和值:
ghci> fmap (+1) (1,1) :: (Int, Int)
(1,2)
ghci> fmap (+1) (Right 1) :: Either Int Int
Right 2
ghci> fmap (+1) (Left 1) :: Either Int Int
Left 1
记住,Right 表示解析成功,元组中的第二个值是解析结果。因此,外层 fmap 应用于 Either 类型,内层 fmap f 应用于 Right 构造器内部的元组。
对于 magic number,现在可以定义解析器:
ghci> p1P = fmap (const P1) $ string "P1"
ghci> :t p1P
p1P :: Parser MagicNumber
ghci> runParser p1P "P1 100 100"
Right (" 100 100",P1)
ghci> runParser p1P "P2 100 100"
Left "failed to parse \"P1\""
每当想应用形如 fmap (const X) 的表达式时,都可以用 Functor 类型类中正好做这件事的运算符来简化。(<$) 运算符用于为函子映射提供一个常量值。使用这个运算符,可以定义解析器:
magicNumberP1P :: Parser MagicNumber
magicNumberP1P = P1 <$ string "P1"
...
magicNumberP6P :: Parser MagicNumber
magicNumberP6P = P6 <$ string "P6"
现在,我们为每个 magic number 都有了一个解析器。要解析整个文件头部,接下来应该关心如何组合解析器。如何把这些分散的部分组合成更大的结构?
12.1.3 合成效果(Composing effects)
假设现在不尝试解析以通用 magic number 开头的文件,而是解析一个固定的 magic number。我们选择 P1。在这个头部中,图像数据没有最大值,所以头部只包含 magic number、宽度和高度。为了简单起见,不考虑注释,并假设头部是单行,值之间以空格分隔。因此,头部可能如下:
P1 100 100
解析任意数量的空格,可以通过构造一个拥有 takeWhile 功能的解析器来实现。我们已经从 Data.List 和 Data.Text 中熟悉了这个功能:只要输入字符满足某个谓词,就继续读取输入。由于函数处理的是 Text 值,可以使用 Data.Text 中的函数构建解析器,如下所示。
代码清单 12.6 按谓词读取输入的解析器
takeWhile :: (Char -> Bool) -> Parser T.Text
takeWhile p = Parser $ \t -> Right (T.dropWhile p t, T.takeWhile p t) -- #1
- #1 只要指定谓词成立就读取字符,并从仍需解析的剩余输入中移除已读取字符
借助它,可以构造空格解析器,以及由数字组成的字符串解析器:
spaces :: Parser T.Text
spaces = takeWhile (' ' ==)
使用 takeWhile 和 fmap,也可以定义整数解析器:
integer :: Parser Integer
integer = read . T.unpack <$> takeWhile (`elem` ['0' .. '9'])
这个解析器的问题是,当输入为空时会让程序崩溃。稍后我们会为数值写一个更好的解析器。
现在,可以为头部定义类型:
data Header = Header
{ width :: Integer,
height :: Integer
}
deriving (Show)
我们希望创建一个 Parser Header,并拥有一种方式组合 spaces 和 integer 组件,从而构建实际数据类型的解析器。为了指定头部的预期结构,它可能看起来像这样:
Header <_> (string "P1" <_> spaces <_> integer) <_> (spaces <_> integer)
这会让我们能够说明如何读取 magic number、宽度和高度,以及哪些解析结果会被用作 Header 数据类型中的字段。(<_>) 运算符只是占位符。我们需要想出真正的运算符来替代它。不管这些运算符是什么,它们都需要把任意解析器中的错误传播到完整解析器。
为了更好理解这个问题,看看 Header 是什么。它是一个构造器,但同时也是一个类型为 Integer -> Integer -> Header 的函数。暂时想象一下,如果能把这个类型改为 Parser Integer -> Parser Integer -> Parser Header。这样就能把 integer 插入两个参数,最终得到 Parser Header。
由此可以推断,我们想要的是按顺序应用解析器并收集结果。这里的收集指对结果做某种聚合,可能包括忽略某些结果,也可能以某种方式组合它们。本质上,我们想把一个函数(这里是 Header)应用到多个 Parser 值上。
Functor 类已经提供 fmap,可用于把一元函数应用到 Parser。那么,如果把 Header 应用于 integer 会发生什么?
ghci> :t Header <$> integer
Header <$> integer :: Parser (Integer -> Header)
结果是一个内部类型为函数的 Parser。请记住,<$> 运算符只是 fmap 的中缀版本。接下来如何继续?如何应用这个解析器?这就引出了一个新的类型类:Applicative。
Applicative functor,简称 applicative,是 functor 的扩展。它允许把函子上下文中的函数应用到该上下文中的另一个值上,从而可以按顺序组合这些操作。为了更清楚地理解,看看 Applicative 的类定义:
class Functor f => Applicative f where
pure :: a -> f a
(<*>) :: f (a -> b) -> f a -> f b
liftA2 :: (a -> b -> c) -> f a -> f b -> f c
(*>) :: f a -> f b -> f b
(<*) :: f a -> f b -> f a
{-# MINIMAL pure, ((<*>) | liftA2) #-}
这个类型类中最重要的函数是 pure 和 (<*>)。pure 用于接收一个值,并把它放入由 f 表示的函子上下文中。(<*>) 用于把这个上下文中的函数应用到上下文中的值上。本质上,可以把这个运算符类型重写成 f (a -> b) -> (f a -> f b),意思是该运算符把上下文内部的函数转换成上下文外部的函数。这正是 applicative 的特殊之处。Functor 可以把普通函数转换为处理函子包装值的函数,如图 12.4 所示。
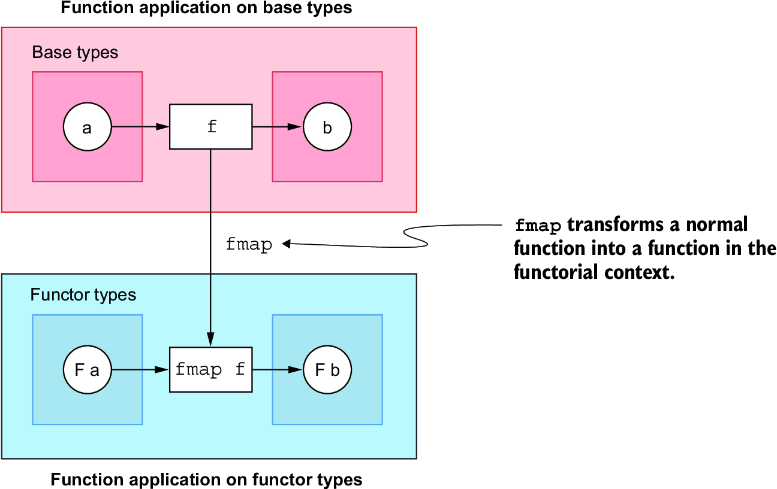
图 12.4 Functor 功能的抽象视图
Applicative 则接收函子上下文中的函数,并把它们“解除提升”到普通上下文中,让我们可以组合它,如图 12.5 所示。
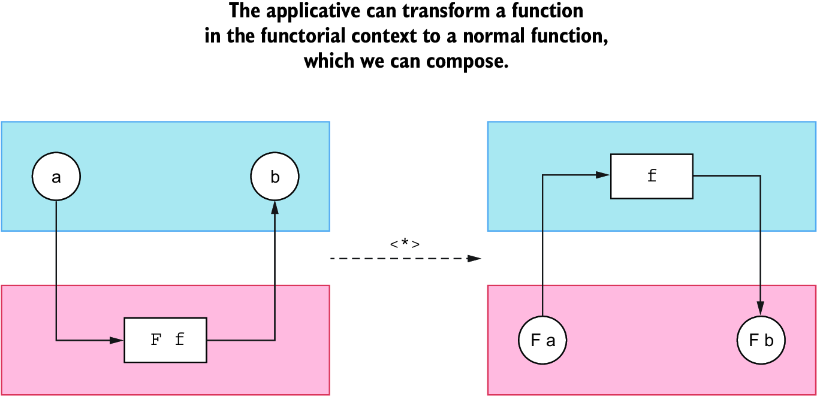
图 12.5 Applicative 功能的抽象视图
在关心其他函数之前,先看一个例子。Maybe 类型拥有 Applicative 实例,其中 (<*>) 会在函数被 Just 构造器包装,并且值也在 Just 构造器中时应用该函数。如果任意 Maybe 值是 Nothing,最终结果也是 Nothing:
ghci> Just (+1) <*> Just 1 :: Maybe Int
Just 2
ghci> Just (+1) <*> Nothing :: Maybe Int
Nothing
ghci> Nothing <*> Just 1 :: Maybe Int
Nothing
ghci> Nothing <*> Nothing :: Maybe Int
Nothing
ghci> pure 100 :: Maybe Int
Just 100
现在可以愉快地组合函数,也可以把它们应用到 Maybe 上下文中的更多值:
ghci> add3 x y z = x + y + z
ghci> pure add3 <*> Just 1 <*> Just 2 <*> Just 3 :: Maybe Int
Just 6
使用 pure 把函数提升到上下文中是很常见的,但借助部分函数应用和 fmap(就像 Header 示例中看到的),可以获得稍微更干净的语法:
ghci> add3 <$> Just 1 <*> Just 2 <*> Just 3 :: Maybe Int
Just 6
那么 Applicative 类中的其他函数是什么?liftA2 用于把任意二元函数提升为可作用于函子上下文中的参数:
ghci> liftA2 (+) (Just 1) (Just 2) :: Maybe Int
Just 3
(<*) 和 (*>) 比较特殊,它们会丢弃第一个或第二个参数的结果,但仍然求值其效果。这里的意思是,该参数的结果会影响最终结果。对于 Maybe,如果在顺序组合它们时任意参数求值为 Nothing,整个项也会求值为 Nothing。这些丢弃版本的 (<*>) 同样如此:
ghci> Just (1 :: Int) <* Just (2 :: Int)
Just 1
ghci> Just 1 <* Nothing :: Maybe Int
Nothing
这与我们有什么关系?Applicative 类让我们能够按顺序组合解析器。输入会被顺序解析:序列中后面的解析器会在前面解析器留下的输入上调用。起初,必须为“函数值的 Parser”构造函数可能看起来奇怪,但真正应用它时就会合理。Applicative Parser 实例代码如下所示。
代码清单 12.7 解析器类型的 Applicative 实例
instance Applicative Parser where
pure x = Parser $ \t -> Right (t, x) -- #1
(<*>) a b =
Parser $ \t ->
case runParser a t of -- #2
Left msg -> Left msg -- #3
Right (rest, f) -> runParser (fmap f b) rest -- #4
- #1 返回一个不消耗输入、但返回固定值的解析器
- #2 把第一个解析器应用到输入上
- #3 如果第一个解析器解析失败,则返回失败结果
- #4 如果第一个解析器成功,则把第二个解析器应用到剩余输入,并把第一个解析器得到的函数应用到第二个解析器的结果上
pure 创建一个不消耗任何输入并返回固定值的解析器。(<*>) 运算符先在第一个解析器上运行输入;如果该解析步骤不成功,就返回 ErrorMessage 和消息剩余部分。否则,就在剩余输入上运行第二个解析器,并通过 fmap 应用第一个解析器返回的函数。
现在可以尝试顺序组合 Parser。例如,可以规范化两个单词之间的空格:
ghci> :{
ghci| helloWorldP = (\x _ z -> x <> " " <> z)
ghci| <$> string "Hello"
ghci| <*> spaces
ghci| <*> string "World"
ghci| :}
ghci> runParser helloWorldP "Hello World"
Right ("","Hello World")
ghci> runParser helloWorldP "Hello World"
Right ("","Hello World")
ghci> runParser helloWorldP "Helloooo World"
Left "failed to parse \"World\""
这里可以看到,每个解析器都会处理前一个解析器留下的输入。同样的定义也可以用 (<*) 写出:
ghci> :{
ghci| hw = (\x y -> x <> " " <> y)
ghci| <$> string "Hello"
ghci| <* spaces
ghci| <*> string "World"
ghci| :}
这终于让我们可以完成示例头部的解析器。可以使用前面的 Header 和 (<$>),再借助 (<*>) 完成它:
ghci> :{
ghci| headerP = Header
ghci| <$> (string "P1" *> spaces *> integer)
ghci| <*> (spaces *> integer)
ghci| :}
ghci> runParser headerP "P1 100 200"
Right ("",Header {width = 100, height = 200})
ghci> runParser headerP "P2 100 200"
Left "failed to parse \"P1\""
ghci> runParser headerP "P1 100 "
Right ("",Header {width = 100, height = *** Exception:Prelude.read: no parse
这种 applicative 风格的解析器写法很常见,因此值得稍微研究。Applicative 和 Functor 一样,是阅读 Haskell 代码时经常遇到的类。它的作用很简单:组合效果。这帮助我们编写仍然可以自由组合、但语义遵循严格规则的代码。所有这些都仅由类型系统保证!到目前为止,我们遇到的许多类型,例如 Maybe、Either,甚至 IO,都有这个类的实例。
练习:Monoidal functor 和 applicative functor
Applicative functor 等价于所谓的*(lax)monoidal functor*。可以用它们把两个函子值组合成元组,从而组合它们。
为了让这个类等价于 Applicative,必须能够把任意一个类的实例转换成另一个类的实例。请说明这是可能的!
现在,我们已经为简化头部构建了一个解析器。目前还没有做到的是,让解析器接受多个 magic number。在示例中,也可以允许 P4 作为 magic number,但现在解析器会失败。我们必须找到一种方式,在解析器中编码替代选择。答案又来自另一个类型类。
12.1.4 选择性替代(Choosing alternatively)
解析器中 (<*>) 的实现可以理解为一种然后语义:第一个解析器解析输入,然后第二个解析器也解析。要为解析器编码替代选择,需要实现一种否则语义。这意味着如果第一个解析器失败,原始输入(没有任何内容被消耗)必须传给第二个解析器,希望它不会失败。
这正是 Alternative 类型类实例所需的语义。看看它的定义:
class Applicative f => Alternative f where
empty :: f a
(<|>) :: f a -> f a -> f a
some :: f a -> f [a]
many :: f a -> f [a]
{-# MINIMAL empty, (<|>) #-}
最小定义由 empty 和 (<|>) 组成,看起来与 Monoid 的定义非常相似。事实上,它们确实相似!empty 是 (<|>) 的单位元,而 (<|>) 是 Alternative 的结合性二元操作。实际上,Alternative 是 applicative functor 上的 monoid。
虽然单个参数失败时 (<*>) 就会失败,但 (<|>) 只有在两个参数都失败时才失败。可以再次用 Maybe 快速实验这种语义:
ghci> Just 1 <|> Just 2 :: Maybe Int
Just 1
ghci> Just 1 <|> Nothing :: Maybe Int
Just 1
ghci> Nothing <|> Just 2 :: Maybe Int
Just 2
ghci> Nothing <|> Nothing :: Maybe Int
Nothing
如果把 Nothing 看成“失败”,就能理解我们的解析器应该如何表现。为了给解析器提供更有意义的错误消息,可以编写一个函数,用于修改解析器的错误消息。如下所示。
代码清单 12.8 解析失败时修改解析器错误消息的函数
modifyErrorMessage ::
(ErrorMessage -> ErrorMessage) ->
Parser a ->
Parser a
modifyErrorMessage f p =
Parser $ \t -> case runParser p t of -- #1
Left msg -> Left $ f msg -- #2
result -> result -- #3
- #1 在给定输入上运行解析器
- #2 如果解析器不成功,则修改错误消息
- #3 成功结果保持不变
有了这个函数,就可以为 Alternative Parser 创建实例,如代码清单 12.9 所示。为了让 empty 成为单位元,它必须总是失败,所以可以编写一个甚至不消耗输入、但总是返回某个 Left 值作为结果的解析器。对于 (<|>),必须运行第一个解析器,并在失败时运行第二个解析器,同时使用新的 modifyErrorMessage 函数,把第一个解析器的错误消息前置到可能的第二个错误消息中。
代码清单 12.9 自定义解析器的 Alternative 实例
instance Alternative Parser where
empty = Parser $ \_ -> Left "empty alternative"
(<|>) a b =
Parser $ \t ->
case runParser a t of -- #1
Left msg -> runParser (modErr msg b) t -- #2
right -> right -- #3
where
modErr msg =
modifyErrorMessage (\msg' -> msg ++ " and " ++ msg') -- #4
- #1 运行第一个解析器
- #2 运行第二个解析器,并在失败时修改它的错误消息
- #3 如果第一个解析器成功,则返回其结果
- #4 把给定错误消息追加到要修改的解析器错误消息前面
有了这个实例,就能在解析器中编码选择。这里有趣的一点是,它可以用于高度嵌套的解析器。因此,如果某个解析器已经成功解析了输入的大部分内容,最后才发现解析无法成功,(<|>) 让它可以回滚到原始输入,再用另一个解析器尝试。看一个例子:
ghci> import Control.Applicative
ghci> runParser (string "A" <|> string "B") "A"
Right ("","A")
ghci> runParser (string "A" <|> string "B") "B"
Right ("","B")
ghci> runParser (string "A" <|> string "B") "C"
Left "failed to parse \"A\" and failed to parse \"B\""
注意这里导入了 Control.Applicative。目前讨论过的类型类(Functor、Applicative 和 Alternative)都定义在那里。要使用 (<|>),必须导入它。
虽然 Alternative 实例本身已经非常有用,它还提供另外两个函数:some 和 many。这两个函数会反复应用给定 applicative functor,直到它不能再应用为止;在我们的场景中,这意味着解析器失败。结果会被收集进列表。二者唯一差异是 many 永远不会失败。如果第一次应用失败,就返回空列表。some 则至少需要一次成功应用才能成功。因此,some 表示一个或多个,many 表示零个或多个。
练习:many 与 some
many 可以这样定义:
要么获得一个或多个元素,要么返回空列表。那么 some 可以如何定义?请尝试想出一个实现。
使用这两个函数,现在可以创建一个任意多次解析某个 token 的解析器:
ghci> runParser (many $ string "A") "AAA"
Right ("",["A","A","A"])
ghci> runParser (many $ string "A") ""
Right ("",[])
ghci> runParser (some $ string "A") "AAA"
Right ("",["A","A","A"])
ghci> runParser (some $ string "A") ""
Left "failed to parse \"A\""
回想一下 spaces 的定义,它使用 takeWhile 解析器实现。如果想创建一个确保输入中至少存在一个空格的解析器,可以很容易地用 some 做到,如下所示。
代码清单 12.10 至少解析一个空格的解析器
someSpaces :: Parser T.Text
someSpaces = T.concat <$> some (string " ") -- #1
- #1 至少解析一个空格,并把得到的字符串连接成更大的字符串;否则失败
最后要讨论的是如何书写包含许多替代解析器的情况。真的想在一个巨大表达式中用 (<|>) 把它们组合起来吗?如果只指定一个解析器列表,然后逐个尝试,会更好。这可以通过 Data.Foldable 中的 asum 函数实现。它会使用给定类型的 Alternative 实例语义折叠给定结构:
ghci> :i asum
asum :: (Foldable t, Alternative f) => t (f a) -> f a
ghci> runParser (asum [string "A", string "B"]) "A"
Right ("","A")
ghci> runParser (asum [string "A", string "B"]) "B"
Right ("","B")
ghci> runParser (asum [string "A", string "B"]) "C"
Left "failed to parse \"A\" and failed to parse \"B\" andempty alternative")
注意错误消息以 empty alternative 结尾。这是我们 Alternative Parser 实现中单位元的错误消息!asum 真正做的是用 Alternative 给出的 monoid 语义组合结构中的所有元素,用 (<|>) 折叠它们,最后一个元素是 empty(这也是空结构的默认值)。
警告
some和many是根据Alternative与Applicative中定义的函数实现的。如果传给它们的参数是常量并且总是成功,就会造成无限循环!一个例子是some (Just 1)。
借助这个方便的函数,可以创建一个别名,让代码更容易理解:
choice :: [Parser a] -> Parser a
choice = asum
替代选择处理完后,只剩最后一块拼图。解析 PNM 文件头部已经几乎可行。可以在解析器中编码 magic number 的选择、跳过任意数量的空格,并读取整数。缺少的是一点逻辑:当 magic number 不是 P1 或 P4 时,才需要解析数据点的最大值。为了解决组合性和错误处理问题,我们从 Functor 升级到了 Applicative。不过,现在想处理的问题需要再进一步。
12.1.5 引入单子(Introducing monads)
到目前为止,解析器只依赖它读取的输入,而不依赖前面解析器的结果。这使得解析器几乎不可能根据已经解析的数据所提供的上下文和额外信息来行动。回顾一下解析 PNM 文件头部时的问题:
P2 3 2 1
1 0 1
0 1 0
这里展示的头部指定了一个最大值为 1 的灰度图文件。因此,唯一可能的值是它和 0。这个文件的解析器需要读取 magic number,从中推断出需要读取最大值,然后继续读取数据。如果 magic number 是 P1,则会跳过最大值并立即读取数据。这里必须根据读取到的 magic number 做分支判断。先为 PNM 头部创建一个更具体的类型,如下所示。
代码清单 12.11 PNM 文件头部类型
data Header = Header
{ magicNumber :: MagicNumber, -- #1
width :: Integer, -- #2
height :: Integer, -- #2
maxVal :: Maybe Integer -- #3
}
deriving (Eq, Show) -- #4
- #1 定义头部 magic number 字段
- #2 定义图像宽度和高度字段
- #3 定义数据点可选最大值字段
- #4 派生
Eq和Show实例
我们必须解析头部的 magic number、宽度和高度。然后必须做一个选择:要么不解析最大值,因为不需要;要么读取它。这个选择基于已经解析出的 magic number。
然而,applicative 不允许这样做!事实证明,它们允许组合解析器,但不允许做分支判断。我们不能基于已经读取的值改变行为。为了解决这个问题,需要引入另一个概念。正如 applicative 是 functor 的扩展,现在我们要看 applicative 的扩展:Monad。
Monad 是 Haskell 中的核心概念,也可能是函数式编程中最有用、最有趣的概念之一。它允许把值包装进一个单子类型,并让任意函数作用于这些值。正如我们在 applicative 中看到的,monad 也允许组合这些函数,同时遵循我们为用例定义的规则。看看这个类型类:
class Applicative m => Monad m where
(>>=) :: m a -> (a -> m b) -> m b
(>>) :: m a -> m b -> m b
return :: a -> m a
{-# MINIMAL (>>=) #-}
在 Haskell 中,所有 monad 也是 applicative。Monad 实例最重要、也是唯一必需的函数是 (>>=),口语上称为 bind。它接收一个单子值 m a,以及一个作用于该单子值内部值的函数,该函数返回新的单子值,类型可能不同,即 m b。这个值随后从 bind 函数返回。第二个函数 (>>) 与 (>>=) 类似。它求值第一个单子值,但忽略其结果,并返回第二个参数。return 不只是看起来像 Applicative 类中的 pure,它本质上就是 pure,用于把一个值包装进单子值。
注意 之前我们把
pure的结果称为函子上下文中的值。现在称它们为单子值,因为这些术语可以互换。有时,我们把单子值m a称为动作,因为它们可能改变底层单子结构中的某些状态。这些动作可以产生效果。区分是否求值一个动作很重要,因为这可能造成巨大差异。
为了感受这个类,我们再次看一个示例实例,也就是 Monad Maybe:
ghci> return 1 :: Maybe Int
Just 1
ghci> (Just 1) >>= (\x -> return (x + 1)) :: Maybe Int
Just 2
ghci> (Just 1) >>= (\x -> return (x + 1)) >>= (\x -> return (x * 2)) :: Maybe Int
Just 4
ghci> Nothing >>= (\x -> return (x + 1)) :: Maybe Int
Nothing
就像某个参数是 Nothing 时 (<*>) 会产生 Nothing 一样,(>>=) 对第一个参数也会这样做!这里可以看到如何使用 bind 函数访问 monad 内部的值,在这个例子中就是 Maybe。传给 bind 的函数可以拥有任意复杂的行为,可以使用喜欢的任何语言特性,只要类型签名能通过。这意味着可以在传给 bind 的函数内部继续使用 bind,从而组合任意数量被单子类型包装的值。作为例子,可以看下面的函数。
代码清单 12.12 单子式相加数值的函数
monadd :: (Num a, Monad m) => m a -> m a -> m a
monadd xm ym =
xm >>= -- #1
(\x -> -- #1
ym >>= -- #2
(\y -> -- #2
return $ x + y -- #3
)
)
- #1 把单子值
xm内部的值绑定到x - #2 把单子值
ym内部的值绑定到y - #3 把
x和y的和作为新的单子值返回
这个函数接收两个单子值,用 (>>=) 解包它们,并把它们的和作为新的单子值返回:
ghci> monadd (Just 1) (Just 2) :: Maybe Int
Just 3
ghci> monadd Nothing (Just 2) :: Maybe Int
Nothing
ghci> monadd (Just 1) Nothing :: Maybe Int
Nothing
ghci> monadd Nothing Nothing :: Maybe Int
Nothing
使用 bind 函数时,我们可以在处理这些值时构造并组合任意逻辑。值得注意的是,不必操心失败状态。从代码清单 12.12 的示例可以看到,我们不必担心值是不是 Nothing(这里使用 Maybe 时)。bind 函数会确保我们要么能够访问到一个值,要么整个表达式简单求值为 Nothing。这个属性让 monad 成为处理副作用的绝佳候选。
注意 有时我们说 Haskell 没有副作用。这并不正确。如果 Haskell 没有副作用,它就不会有
IO。Haskell 只是没有任意副作用;它拥有受控副作用,并由类型系统把这些副作用与纯代码清晰分开!
事实上,从第 3 章开始我们就一直在使用 monad!事实证明,IO 是一个 monad。IO 中产生的副作用由 bind 函数控制和处理。我们与 IO 一起使用过的 return 函数,正是 Monad 类型类中的 return。也可以看出,我们其实已经在不知情的情况下使用了 IO 的 bind 函数。Haskell 提供的 do 记法就是 bind 函数的语法糖!
m >>= f
这个简单项等价于:
do x <- m
f x
另一个 bind 函数更容易翻译:
m1 >> m2
这个项会变成:
do _ <- m1
m2
注意这个片段清楚表明第一个参数会被求值。知道 bind 和 do 记法之间的关系后,可以快速把代码清单 12.12 中的例子重写为 do 记法:
monadd' :: (Num a, Monad m) => m a -> m a -> m a
monadd' xm ym = do
x <- xm
y <- ym
return $ x + y
do 记法清楚展示了何时以及如何使用单子值求值得到的值。
在更深入讨论 monad 之前,先看看如何把它们用于解析器。要创建 Monad Parser 实例,必须定义 return 和 (>>=)。对于 return 的实现,可以直接使用 Applicative 实例中的 pure。bind 函数需要求值作为第一个参数给出的解析器,然后用这个解析器的结果求值第二个参数给出的函数,并在剩余输入上运行该函数求值得到的解析器。如下所示。如果第一个解析器失败,必须短路,因为不存在可传给函数的值,所以在该点直接失败。
代码清单 12.13 解析器类型的 Monad 实例
instance Monad Parser where
return = pure -- #1
(>>=) p f =
Parser $ \t ->
case runParser p t of -- #2
Left msg -> Left msg -- #3
Right (rest, x) -> runParser (f x) rest -- #4
- #1 把
return定义为Applicative实例中的pure - #2 在给定输入上运行第一个解析器
- #3 如果第一个解析器失败,则返回失败解析结果
- #4 把给定函数应用到第一个解析器的结果上,并运行得到的解析器
有了这个实例,现在可以用 do 记法编写解析器了!
helloWorldP = do
h <- string "Hello"
_ <- someSpaces
w <- string "World"
return $ h <> " " <> w
把它和本章前面的 applicative 记法比较一下;功能仍然相同。正如预期,do 块内部解析失败会导致整个解析器失败:
ghci> runParser helloWorldP "Hello World"
Right ("","Hello World")
ghci> runParser helloWorldP "Hello World"
Right ("","Hello World")
ghci> runParser helloWorldP "Bye Bye World"
Left "failed to parse \"Hello\""
不过,引入 monad 并不是为了替代 applicative,而是为了扩展它们。具体来说,我们想能够基于已解析的值做决策。这可能包括转换解析出的字符串,从而改进之前的 integer 解析器。
使用 do 记法,可以像之前那样读取数值字符。然后使用 readMaybe 检测转换为 Integer 值是否失败或成功。代码如下所示。
代码清单 12.14 整数值解析器
import Text.Read (readMaybe)
...
integer :: Parser Integer
integer = do
intStr <- takeWhile (`elem` ['0' .. '9']) -- #1
case readMaybe (T.unpack intStr) of -- #2
Just value -> return value -- #3
Nothing -> -- #4
Parser $ \_ ->
Left $
"Could not convert \""
++ T.unpack intStr
++ "\" as an integer"
- #1 从输入中读取数字字符
- #2 尝试把读出的字符串转换为
Integer - #3 如果转换成功,则返回转换后的值
- #4 如果转换不成功,则返回错误消息
这个解析器现在会安全读取输入中的字符,并把转换失败变为解析失败。我们能做到这一点,是因为 monad 允许我们根据前一个动作求值得到的值采取行动。
现在,终于可以构造头部解析器了。我们读取 magic number、至少一个空格、宽度、至少一个空格、高度,然后根据 magic number 可选地读取更多空格和最大值。这通过下面的解析器实现。
代码清单 12.15 PNM 头部解析器
headerP :: Parser Header
headerP = do
magicNumber <-
choice -- #1
[ magicNumberP1P,
magicNumberP2P,
magicNumberP3P,
magicNumberP4P,
magicNumberP5P,
magicNumberP6P
]
_ <- someSpaces -- #2
width <- integer -- #3
_ <- someSpaces -- #4
height <- integer -- #5
maxVal <-
if magicNumber == P1 || magicNumber == P4
then return Nothing -- #6
else Just <$> (someSpaces *> integer) -- #7
return Header {..} -- #8
- #1 解析任意 magic number
- #2 解析至少一个空格并忽略结果
- #3 解析图像宽度的数值
- #4 解析至少一个空格并忽略结果
- #5 解析图像高度的数值
- #6 如果 magic number 表示头部不应存在最大值,则返回
Nothing - #7 解析至少一个空格,然后解析一个被包装在
Just构造器中的Integer - #8 从解析出的数据构造完整
Header值
这里展示的头部解析器使用了目前讨论过的全部概念。本章前面引入的 magic number 解析器由 choice 组合。列表中第一个能解析 magic number 的解析器会被选中。由于它们解析的是不同字符串,没有歧义,所以写下它们的顺序并不重要。不过,如果某个解析器只解析另一个解析器的前缀,顺序就会重要。我们使用 someSpaces 解析并忽略值之间的空格。
注意 我们使用
_ <- someSpaces忽略空格,表示结果值不应绑定到任何名称,因此使用_。必须这样做是因为someSpaces的结果不是();否则,就可以直接放弃绑定。可以用Control.Monad中的void函数把结果映射为(),从而简化这一点。因此,它可以重写为void someSpaces,明确表明我们正在忽略该动作的结果。
宽度和高度由代码清单 12.14 中的 integer 解析器解析。最大值解析器在新的 do 块中构造。在那里,可以根据前面已经解析出的值做分支判断。在需要解析最大值的情况下,也会解析一些空格,但通过 Applicative 实例中的 (*>) 忽略它们。值得注意的是,如果这些解析器中的任何一个失败,整个解析器都会失败。这正是 monad 的重要属性,它让我们更简单、更容易地构建复杂应用,同时不必直接思考效果和错误,因为它们由 Monad 实例的定义处理。
12.1.6 关于单子的讨论(A discussion on monads)
如果不进一步讨论 monad,这一节就不算完整。关于 functor、applicative 和 monad,有几点需要注意:
Applicative 和 monad 最重要的属性之一,是它们帮助我们用纯代码管理和控制效果。仅从定义上看,我们见过的类都是纯的,但它们能做的事情不一定纯。IO monad 是一个典型例子。在 IO monad 内部,可以与环境交互。这就是效果!不过,它不是我们通常认为的副作用,因为它并不发生在纯函数内部,而是在纯函数之外的 IO monad 中。当然,为了让 Haskell 程序做任何有用的事情,必须得出一个合理结论:所有代码最终都必须生活在 IO monad 中。这就是为什么 main 的类型是 IO ()。
这会让我们疑惑:为什么不能跳出 monad?为什么没有类型为 (Monad m) => m a -> a 的函数,让我们能在纯代码中访问 monad 内部的值?因为这会破坏我们使用 monad 的理由!Monad 类给出的方法只允许把值带入单子上下文(使用 return),但不允许提取它们,除非使用 bind 函数。这是有意设计的。我们不应该在没有仔细处理可能管理的状态时跳出 monad。
注意 显式允许从结构中跳出的结构是 comonad,Hackage 上有它自己的包。
以 Maybe monad 为例。失败时,它通常采用 Nothing 值。对于这个类型,不可能构造一个 Maybe a -> a 函数,除非让函数变成部分函数。fromMaybe 确实提供了类似功能,但需要一个默认值。因此,我们可以跳出 Maybe monad,但必须确保自己能处理可能的错误状态。允许不安全地跳出 Maybe 的函数是 fromJust,如果值是 Nothing,它会失败。
这个属性对 IO 几乎也成立。unsafePerformIO 函数能够跳出 IO monad。不过,使用它可能导致意外效果,例如效果乱序产生或被应用多次。在更复杂的代码中,unsafePerformIO 甚至可能导致运行时类型错误。
警告 这几乎不用说,但你不应该使用
unsafePerformIO。大多数可以用它解决的问题,也能通过其他方式解决。如果你正在使用它,就应该真的知道自己在做什么,并确保它的用法不会给程序带来问题。
Monad 不是处理效果的全部;它们只是处理效果的一种方式。其他语言实现了自己的效果系统,通常是部分支持。Java 要求程序员指定方法可能抛出哪些异常。调用函数随后必须指定它也可能抛出该异常,或者处理该异常。这是异常领域中的效果处理系统。
我们希望函数保持纯的一个原因是引用透明性。简而言之,它表示可以用函数应用的结果值替换该函数应用,而不改变程序结果。看一个小例子:
f x = x + 1
项 f 1 总是求值为 2,所以把 f 1 替换成值 2 没有区别。程序中所有出现 f 1 的地方都可以改成 2。如果所有函数都是引用透明的,就可以把它们所有应用都替换成之前相同应用的结果。遗憾的是,我们做的事情并不全都能引用透明。IO monad 和 getLine 这样的动作就是一个简单例子。读取用户输入或文件数据、与网络或其他接口交互、生成随机数,都不是引用透明的。幸运的是,我们可以,并且确实会,把它们隔离在 IO 和其他 monad 中。虽然 Maybe monad 这样的 monad 是引用透明的,其他 monad 不一定如此。
注意 事实证明,
Applicative的实例比Monad更多。编写适用于单子结构的通用函数时,这一点很重要。有时,可以让函数保持更通用,只假设存在Applicative实例,从而让代码可用于更多类型。
12.1.7 如何失败(How to fail)
最后要处理的是失败。失败是人性的一部分,也是解析工作的本性。解析可能会失败。事实上,我们已经在函数中建模了解析失败。string 和 integer 都可能失败。能否泛化这种行为?事实证明,借助更多类型类可以做到。
第一个来自 Control.Monad.Fail 模块,名为 MonadFail。它被引入是为了解决 monad 内部模式匹配时出现的问题。看一个例子:
mhead :: (Monad m) => m [a] -> m a
mhead m = do
(x : _) <- m
return x
这个单子版本 head 的定义无法编译!原因是列表上隐式执行了不完整模式匹配。这个模式匹配可能失败。在这种情况下,不清楚如何进入 monad 内部的失败状态。这正是 MonadFail 类型类发挥作用的地方,它通过 fail 方法提供这个功能。这个类很简单:
class Monad m => MonadFail m where
fail :: String -> m a
fail 接收一个错误消息(实现可以选择完全忽略它),并必须提供一个响应该失败的单子值。对于 Maybe,这很简单。fail 直接忽略消息,并得到 Nothing。
现在可以修改单子 head 函数的类型:
mhead :: (MonadFail m) => m [a] -> m a
mhead m = do
(x : _) <- m
return x
它现在可以编译,也可以试试:
ghci> mhead (return [1]) :: Maybe Int
Just 1
ghci> mhead (return []) :: Maybe Int
Nothing
ghci> mhead (return [1]) :: IO Int
1
ghci> mhead (return []) :: IO Int
*** Exception: user error (Pattern match failure in 'do' block at ...
对于 IO monad,会收到异常。我们还没有讲如何处理异常,第 14 章会讨论。
为了处理这一点,并更一般地对待失败,可以为 Parser 类型提供 MonadFail 实例,如下所示。我们已经在 empty 的定义和 integer 解析器的错误中看到过如何编码这样的失败状态。
代码清单 12.16 解析器类型的 MonadFail 实例
instance MonadFail Parser where
fail s = Parser $ \t -> Left s -- #1
- #1 定义失败方法,把错误消息包装进解析器的结果类型中
这允许我们在无法继续解析时使用 fail。借助它,可以清理 integer 解析器:
integer :: Parser Integer
integer = do
intStr <- takeWhile (`elem` ['0' .. '9'])
case readMaybe (T.unpack intStr) of
Just value -> return value
Nothing ->
fail $
"Could not convert \""
++ T.unpack intStr
++ "\" as an integer"
赋予 monad 失败能力的另一种方式是 MonadPlus 类型类。类似于 Alternative 是 applicative 上的 monoid,MonadPlus 是 monad 上的 monoid!它的定义与 Alternative 非常相似:
class (Alternative m, Monad m) => MonadPlus m where
mzero :: m a
mplus :: m a -> m a -> m a
事实证明,mzero 的默认实现是 empty,mplus 的默认实现是 (<|>),二者都来自 Alternative 类型类。如果在定义 MonadPlus Parser 实例时想使用这些默认实现,可以用一行完成:
instance MonadPlus Parser
不过,也许我们想修改 mzero 方法的错误消息。如下所示。
代码清单 12.17 解析器类型的 MonadPlus 实例
import Control.Monad
instance MonadPlus Parser where
mzero = modifyErrorMessage (const "mzero") empty -- #1
- #1 返回一个默认使用错误消息的解析器
在这个定义中使用 empty 是有意为之,因为我们希望 empty 定义的变化能反映到 mzero 中。二者应该表现相似。MonadPlus 与 Alternative 类似,允许实现失败、monad 之间的选择(msum),以及动作结果上的过滤(mfilter):
ghci> import Control.Monad
ghci> smallerTen = mfilter (< 10) integer
ghci> greaterTwenty = mfilter (> 20) integer
ghci> px = msum [smallerTen, greaterTwenty]
ghci> px' = modifyErrorMessage (const "value not < 10 or > 20") px
ghci> runParser px' "1"
("",Right 1)
ghci> runParser px' "100"
("",Right 100)
ghci> runParser px' "15"
("15",Left "value not < 10 or > 20")
注意,这些函数不仅适用于我们的 Parser 类型。它们适用于所有 monad。许多函数,例如 msum 和 mfilter,都定义在 Control.Monad 和 Control.Applicative 中,能帮助你更好地组合功能。
这就结束了关于 monad 的讨论。虽然这看起来像是多余的绕路,但理解它们非常重要。单子式编程是一种帮助我们控制效果的范式,而 Haskell 的独特之处在于,它在核心语言中支持这种范式。
到目前为止,解析器可以处理图像文件的头部。现在,是时候扩展它,让它终于能读取完整图像数据了。
12.2 大规模解析(Parsing on a bigger scale)
我们已经介绍了如何编写一个可组合且抗失败的解析器。也已经看到如何为 PNM 文件头部实现一个解析器。现在,是时候为整个图像文件构建解析器了,也就是解析头部,并继续解析图像数据。在解析期间,必须验证数据是否足够或过多,以及是否超过了头部中可选的最大值。
此外,还需要讨论一个目前一直忽略的问题。根据 magic number,数据可能不是以 Text 给出,而是以字节给出。我们的解析器并不支持这一点。另外,我们的解析器也有局限,缺少对若干事情的支持:
解决这些问题并不简单,所以我们想把注意力转向一种新的解析器,它能解决所有这些问题。解析这个主题在 Haskell 世界中已经被广泛研究。从这项工作中诞生了一些库。也许最有影响力的是 Parsec 库,它提供了与我们编写的解析器非常相似的解析器。这个库的核心思想是,单子解析器可以由解析器组合子构建。这些组合子只是头等函数。我们已经在不知情的情况下使用过解析器组合子,例如 takeWhile、choice 和单子 bind 函数。
练习:实现组合子
有一个提供很多有用解析器组合子的库,名为 parser-combinators。它提供了 between 这样的函数,可把解析器应用于输入的开头、中间和结尾,也提供 skipMany,用于跳过零次或多次成功应用的解析器。下面是一些例子:
查阅该库提供的函数,并尝试自己重新实现它们!
Haskell 中先进的解析器组合子库包括 Megaparsec 和 Attoparsec。Megaparsec 是解析器组合子库中的瑞士军刀。它可用于解析文本或字节,支持出色的详细错误消息,并提供大量方法,用于更好地控制解析器行为。另一方面,Attoparsec 是一个高度专门化的库,用于构造原始字节数据解析器,重点是性能。一个显著特性是内置支持增量输入,因此可以解析大文件,而无需在开始解析前把完整文件内容加载进内存。不过需要注意的是,由于解析器支持任意回溯,一旦完整输入被提供给解析器,整个输入就会驻留在内存中。
就我们的目的而言,我们会把注意力转向 Attoparsec,并用它构造 PNM 文件解析器。事实上,这应该是一个轻松切换,因为库中的解析器在大多数方面都和我们的解析器表现相同。就像我们的库一样,Attoparsec 提供 string 函数。不过,这些解析器不处理 Text,而是处理 ByteString 类型。这个类型拥有类似 Text 的函数,由 bytestring 包提供,所以可以把它当作通常处理文本数据方式的替代品。
ByteString 是一种类似列表的数据结构,其元素类型是 Word8,也就是 8 位无符号整数。这意味着单个字符只是 0 到 255 之间的整数。如果想把常规 Char 类型和 ByteString 结合使用,Data.ByteString.Internal 模块提供了 c2w 和 w2c 函数,用于在 Char 和 Word8 之间转换。幸运的是,IsString ByteString 实例已经存在,所以可以写普通字符串,并让它们重新解释为 ByteString。
12.2.1 Attoparsec 简介(An introduction to Attoparsec)
为了使用新类型和新库,需要把 bytestring 和 attoparsec 加入 package.yaml 的依赖中。完成后,可以尝试新类型。Attoparsec 解析器由非常简单的构件组成。它的核心类型是 Parser,用于解析 ByteString 值。这个类型和解析所需的大多数函数都可以从 Data.Attoparsec.ByteString 模块导入。还有 Data.Attoparsec.Text 模块,它暴露了处理 Text 值的等价函数和类型,就像我们的解析器一样。不过,由于需要处理二进制数据,我们会选择前者:
ghci> import Data.Attoparsec.ByteString as AP
ghci> AP.parse (AP.string "Hello") "Hello"
Done "" "Hello"
ghci> AP.parse (AP.string "Hello") "hello"
Fail "hello" [] "string"
ghci> AP.parse (AP.string "Hello") "He"
Partial _
在 GHCi 中使用限定名导入模块,这样可以避免它与我们自己解析器模块中的名称冲突。可以看到,该模块导出了类型为 ByteString -> Parser ByteString 的 string 函数,它的工作方式和之前的 string 函数一样。parse 是类型为 Parser a -> ByteString -> Result a 的函数,会把解析器应用到给定输入。Result 类型与我们在解析器中构建的结果类型略有不同。它有三个构造器:Done 表示解析成功,Fail 表示失败,Partial 表示解析器没有严格失败,但输入不足,无法完成解析。Done 和 Fail 在第一个字段中携带未解析的剩余输入。不过,Partial 持有一个延续函数,可用于剩余输入:
ghci> Partial c = AP.parse (AP.string "Hello") "He"
ghci> Partial c2 = c "l"
ghci> c2 "lo"
Done "" "Hello"
在这个例子中,我们忽略了不完整模式匹配产生的编译器警告。可以看到,部分结果中的函数可用于增量解析输入。本章基本不关心这个特性,只解析完整输入。为此,可以使用类型为 Parser a -> ByteString -> Either String a 的 parseOnly 函数,它与 runParser 函数非常相似。二者工作方式相同。parseOnly 的结果不会是 Partial,要么成功,要么失败。
我们有一组不错的函数可以用于构建解析器:
可以看到,大多数函数都专门处理 Word8。如果想使用 Char,可以改用 Data.Attoparsec.ByteString.Char8 模块,它暴露了用于解析 ASCII 字母和数字的函数,通常也让处理 Char 值更容易。
12.2.2 图像解析(Parsing images)
现在,可以认真解析图像数据了。首先,定义要处理的数据类型。我们已经有一个头部类型,但想做一个小调整。PNM 文件中任意数据的绝对最大值是 65535,也就是 16 位无符号整数的最大值。可以用 Data.Word 模块中的 Word16 表示。因此,我们会把可选最大值中的 Maybe Integer 换成 Maybe Word16。实际原始数据只是一堆 Word16 值。我们可以追求更紧凑的像素值存储方式,因为对位图使用 16 位多少有些浪费,但目前不优化这个框架。类型如下所示。
代码清单 12.18 解析 PNM 文件的类型
data MagicNumber = P1 | P2 | P3 | P4 | P5 | P6 -- #1
deriving (Eq, Show)
data Header = Header -- #2
{ magicNumber :: MagicNumber,
width :: Integer,
height :: Integer,
maxVal :: Maybe Word16
}
deriving (Eq, Show)
data RawPixel
= Single Word16 -- #3
| RGB Word16 Word16 Word16 -- #4
deriving (Eq, Show)
newtype RawData = RawData -- #5
{ pixels :: [RawPixel]
}
deriving (Eq, Show)
data RawPnm = RawPnm -- #6
{ header :: Header,
imageData :: RawData
}
deriving (Eq, Show)
- #1 定义 magic number 类型
- #2 定义 PNM 文件头部类型
- #3 定义由单个值组成的像素(灰度或黑白)
- #4 定义由红、绿、蓝三个通道值组成的像素
- #5 定义用于存储原始像素的类型
- #6 定义已解析 PNM 文件的类型
要用 Attoparsec 构造头部解析器,需要对最初的头部解析器做一个小调整。我们也趁机用库提供的函数替换自己编写的函数。后续代码清单中,假设已经导入这些模块:
import Data.Attoparsec.ByteString
import qualified Data.Attoparsec.ByteString.Char8 as C8
import qualified Data.ByteString as BS
这些模块处理好后,就可以开始解析头部。解析 magic number 与之前的解析器实现没有区别。由于库中的 Parser 类型拥有与我们定义等价的 Functor、Applicative 和 Monad 实例,可以使用 (<$) 运算符解析输入并返回 MagicNumber,如下所示。
代码清单 12.19 PNM magic number 解析器
magicNumberP1P :: Parser MagicNumber
magicNumberP1P = P1 <$ string "P1" -- #1
...
magicNumberP6P :: Parser MagicNumber
magicNumberP6P = P6 <$ string "P6" -- #2
- #1 解析
"P1"并返回P1值 - #2 解析
"P6"并返回P6值
这样,就可以解析固定字符串,并立即把它翻译成 Haskell 值。
注意 使用
OverloadedStrings时,可以省略固定字符串解析器中的string。只需写出字符串即可,例如P1 <$ "P1"。不过,这可能不如显式使用string可读,因此本章选择不走这个捷径。
Data.Attoparsec.ByteString.Char8 模块还提供了替代 integer 解析器的 decimal 解析器,它的类型是 Integral a => Parser a,用于解析十进制值。需要解决的一个问题是跳过空白。在 PNM 格式中,空白是以下任意字符:' '、\n、\r、\f、\v 和 \t。和之前类似,可以使用 satisfy,检查给定 Char 是否是我们认为的空白。不过,在某些位置,我们想至少解析一个空白字符。为此,可以使用 skipMany1,它至少应用一次给定解析器,并完全忽略读取到的值。如下所示。
代码清单 12.20 跳过空白的解析器
import Control.Monad (void)
...
whitespace :: Parser ()
whitespace =
void $ -- #1
C8.satisfy $ -- #2
\c -> -- #3
c == ' '
|| c == '\n'
|| c == '\t'
|| c == '\r'
|| c == '\v'
|| c == '\f'
whitespaces :: Parser ()
whitespaces = skipMany1 whitespace -- #4
- #1 忽略结果,并把它映射为
() - #2 读取一个满足谓词的字符
- #3 定义 PNM 文件中的空白谓词
- #4 至少跳过一个空白
接下来,还希望能够解析并忽略可能出现在头部中的注释。这样的注释以 % 字符开头,并在某个换行处结束。可以用 char :: Char -> Parser Char 解析器读取字符,并用 takeWhile 读取字符直到找到换行,从而把它翻译成解析器。代码如下。
代码清单 12.21 注释解析器
comment :: Parser BS.ByteString
comment = C8.char '%' >> C8.takeWhile (/= '\n') -- #1
- #1 读取
%字符,然后继续读取字符直到遇到换行,返回%后读取的字符串
值得注意的是,这个解析器要求必须读取注释。因此,如果想用它可选地解析注释,需要忽略失败。在头部中,我们想忽略空白和注释。遗憾的是,不知道它们会在头部何处出现,所以需要在 magic number 和其他读取值之间忽略它们。为此,可以构造另一个解析器,跳过这些额外信息。
代码清单 12.22 跳过空白和注释的解析器
skipWhitespace :: Parser ()
skipWhitespace =
option () $ -- #1
choice -- #2
[ comment >> skipWhitespace, -- #3
whitespaces >> skipWhitespace -- #4
]
- #1 让解析器可选,并始终返回
() - #2 运行后续解析器,并应用成功解析器的效果
- #3 解析注释,并递归调用该解析器
- #4 解析空白,并递归调用该解析器
如代码清单 12.22 所示,可以通过提供“读取注释或空白”的选择,并在之后递归调用解析器来继续读取另一条注释或另一组空白,从而构造跳过空白的解析器。不过,如果遇到真正数据,而解析这些东西失败,会发生什么?为覆盖这种情况,我们使用 option :: Alternative f => a -> f a -> f a。它会尝试应用第二个参数中的动作,如果失败,则提供第一个参数给出的默认值。
现在,可以把所有这些解析器组合起来,解析代码清单 12.18 中的新头部类型。在解析器元素之间,允许任意注释和空白,并使用 skipWhitespace。在头部末尾,也解析一个单独空白,因为规范要求头部以一个空白结束。这一次,我们使用 Data.Attoparsec.ByteString.Char8 中的 decimal 来解析 Word16 值。除此之外,与上一次实现相比变化不大。新解析器如下所示。
代码清单 12.23 使用 Attoparsec 的 PNM 头部解析器
headerP :: Parser Header
headerP = do
skipWhitespace
magicNumber <-
choice -- #1
[ magicNumberP1P,
magicNumberP2P,
magicNumberP3P,
magicNumberP4P,
magicNumberP5P,
magicNumberP6P
]
skipWhitespace
width <- C8.decimal -- #2
skipWhitespace
height <- C8.decimal -- #2
maxVal <- do
if magicNumber == P1 || magicNumber == P4
then return Nothing
else Just <$> (skipWhitespace *> C8.decimal) -- #3
whitespace
return Header {..}
- #1 解析 PNM 文件的 magic number
- #2 解析宽度和高度的十进制值
- #3 按需解析另一个十进制值作为最大值
头部处理完后,就可以解析图像数据了。
12.2.3 格式选择(Choosing between formats)
PNM 文件格式中的不同格式以不同方式编码数据。回顾一下这些格式。对于 magic number P1(位图)、P2(灰度图)和 P3(像素图),数据以 ASCII 编码。对于位图,只有两个可能值,也就是 1 和 0;对于灰度图和像素图,接受的值取决于头部给出的最大值。灰度图的像素值是单个十进制值,而像素图中每个像素有三个十进制值。magic number P4(位图)、P5(灰度图)和 P6(像素图)有类似规则。不过,数据以二进制编码。对于二进制位图,每一位对应单个像素,并且像素按位出现的相同顺序出现,这意味着文件必须逐字节读取,从最高有效位解析到最低有效位。当需要读取的像素数量不能被 8 整除时,多余的位会被忽略。对于二进制灰度图和像素图,规则与其 ASCII 对应格式相同。不过,根据最大值有一个特殊规则。默认情况下,一个字节构成一个值。如果最大值大于 255,该值无法放入单个字节,因此每个像素值必须读取两个字节。
先为 ASCII 编码文件编写解析器。目前只关心解析单个像素,稍后再用它们解析完整数据。从前面的讨论可知,位图的像素数据归结为解析常量(1 和 0)。解析灰度图和像素图要求解析十进制值。在解析器中,不立即检查是否超过头部中给出的最大值。我们只关心解析文件中存在的原始数据。这些解析器代码如下。
代码清单 12.24 ASCII 编码 PNM 图像数据解析器
p1PixelP :: Parser RawPixel
p1PixelP =
Single
<$> choice -- #1
[ 1 <$ C8.char '1',
0 <$ C8.char '0'
]
p2PixelP :: Parser RawPixel
p2PixelP = Single <$> C8.decimal -- #2
p3PixelP :: Parser RawPixel
p3PixelP = do -- #3
r <- C8.decimal
whitespaces
g <- C8.decimal
whitespaces
b <- C8.decimal
return $ RGB r g b
- #1 只解析
1和0字符,并把它们映射到合适的值 - #2 解析单个十进制值
- #3 把三个十进制值解析为一个 RGB 像素值
类型为 Integral a => Parser a 的 decimal 解析器可以解析任意整数值。Haskell 可以推断,在这些实例中被解析的值类型是 Word16,因为构造器给出的类型就是如此。在 p1PixelP 和 p2PixelP 的实现中,我们使用 (<$>) 把单值构造器应用到解析出的数据上。对于 p3PixelP,我们使用 do 记法在十进制值之间解析任意数量空白,因为文件格式规范没有强制规定值之间空白的固定数量。
ASCII 编码像素处理完后,可以继续处理二进制格式。先讨论灰度图和像素图,因为位图稍微特殊。对于这两种格式,每个 magic number 实际上需要两个解析器,因为要么需要读取单个字节(Word8),要么需要读取两个字节(Word16)来得到值。Attoparsec 已经提供 anyWord8 :: Parser Word8 解析器,用于读取单个字节。不过,它没有提供可直接使用的 anyWord16 解析器,所以必须自己构造。
编写这个解析器时,需要稍微思考如何把多个字节组合成更大的 word。假设有两个彼此紧邻的字节。我们想把它们读取为一个 Word16。可以先连续读取第一个和第二个字节。为了组合它们,必须把它们重新解释为 16 位 word,并把第一个字节向左移动 8 位。这样,该字节会填满 16 位 word 的前 8 位,并在低半部分为后面读取的字节腾出空间。假设左移只会在第一个字节原本写入的位置留下 0,就可以通过按位 OR 操作插入第二个字节。这样,第二个字节中为 0 的值保持 0,为 1 的值变成 1。
这些低层操作由 Data.Bits 模块提供。那里可以找到 Bits 类型类,它为多种数据类型定义按位操作,其中包括我们的 word 类型 Word8 和 Word16。在这个类中,也可以找到 shift :: a -> Int -> a 方法,它会把值向左移动;以及 (.|.) :: a -> a -> a 运算符,它执行按位 OR 操作。快速试验一下:
ghci> import Data.Word
ghci> import Data.Bits
ghci> byte1 = 1 :: Word8
ghci> byte2 = 1 :: Word8
ghci> shift byte1 8
0
ghci> shift (fromIntegral byte1 :: Word16) 8
256
ghci> byte1_16 = fromIntegral byte1 :: Word16
ghci> byte2_16 = fromIntegral byte2 :: Word16
ghci> shift byte1_16 8 .|. byte2_16
257
可以看到,把一个只有单个位(位于最低有效位)的 Word8 左移 8 位会得到 0,因为单个字节没有足够空间。使用 fromIntegral 把它转换为 Word16 后,就为该位的移动留出了空间。也可以看到,把一个字节左移 8 位,并与第二个字节做按位 OR,实际上会按我们想要的顺序把二者组合起来。图 12.6 展示了这一点。
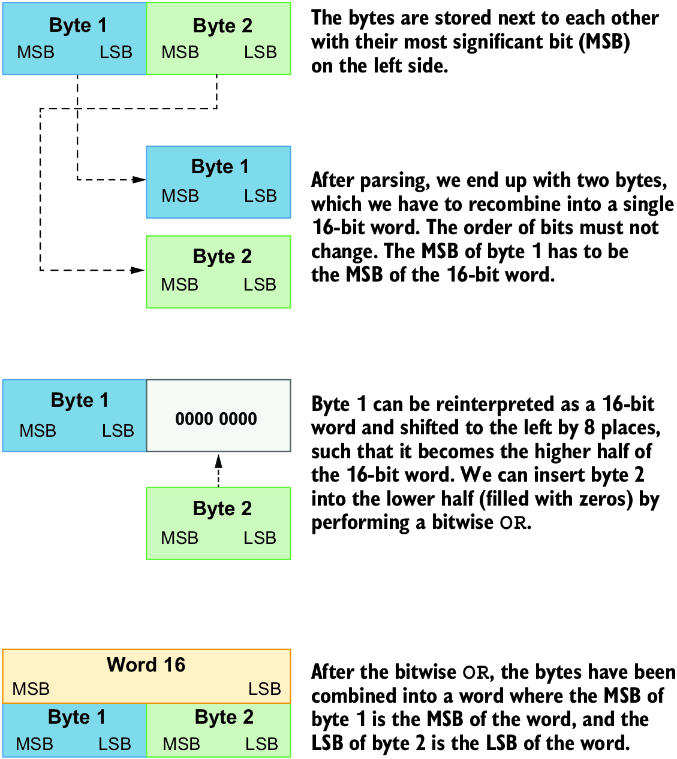
图 12.6 把两个字节组合成 16 位 word 的过程
可以利用这一点构建 anyWord16 解析器:读取两个字节,并按上述方式组合它们。实现如下所示。
代码清单 12.25 16 位 word 解析器
import Data.Bits
...
anyWord16 :: Parser Word16
anyWord16 = do
h <- fromIntegral <$> anyWord8 -- #1
l <- fromIntegral <$> anyWord8 -- #1
return $ shift h 8 .|. l -- #2
- #1 读取 8 位 word 并转换为 16 位 word
- #2 把两个值组合为单个 16 位 word
这里再次使用 fromIntegral 把 Word8 值转换为 Word16,这样按位操作才能工作。有了这个功能,就可以构造 8 位和 16 位版本的灰度图与像素图解析器。如下所示,它们的实现足够直接,因为这次不必关心空白。
代码清单 12.26 二进制编码 PNM 文件的 8 位和 16 位解析器
p5PixelWord8P :: Parser RawPixel
p5PixelWord8P = Single <$> (fromIntegral <$> anyWord8) -- #1
p5PixelWord16P :: Parser RawPixel
p5PixelWord16P = Single <$> anyWord16 -- #2
p6PixelWord8P :: Parser RawPixel
p6PixelWord8P = RGB <$> p <*> p <*> p -- #3
where
p = fromIntegral <$> anyWord8
p6PixelWord16P :: Parser RawPixel
p6PixelWord16P = RGB <$> anyWord16 <*> anyWord16 <*> anyWord16 -- #4
- #1 读取单个 8 位 word
- #2 读取单个 16 位 word
- #3 读取三个 8 位 word
- #4 读取三个 16 位 word
现在剩下的就是处理二进制位图。如前所述,必须按位解析这些文件,也就是说,每个位都是一个像素值。我们无法按位解析文件,所以必须重新思考如何从读取的字节中提取值。Data.Bits 中的 Bits 类型类再次提供了有用函数 testBit :: a -> Int -> Bool,它允许检查某个值在特定偏移处的位。使用这个函数,可以解析单个字节并从中返回八个像素值。下面的清单展示了二进制位图格式中像素值解析器的实现。
代码清单 12.27 二进制编码位图解析器
p4PixelP ::
Parser
( RawPixel,
RawPixel,
RawPixel,
RawPixel,
RawPixel,
RawPixel,
RawPixel,
RawPixel
)
p4PixelP = do
w <- anyWord8 -- #1
let parseBitAtIndex n =
Single $ if testBit w n then 1 else 0 -- #2
return
( parseBitAtIndex 7, -- #3
parseBitAtIndex 6, -- #3
parseBitAtIndex 5, -- #3
parseBitAtIndex 4, -- #3
parseBitAtIndex 3, -- #3
parseBitAtIndex 2, -- #3
parseBitAtIndex 1, -- #3
parseBitAtIndex 0 -- #3
) -- #3
- #1 读取单个 8 位 word
- #2 定义一个函数,用于解析 8 位 word 中的特定位
- #3 分别返回解析出的每一位
在这个实现中,我们把每一位分别解析到一个元组中,因为已经知道 Word8 值中有多少位。按照 PNM 文件规范,我们从最高有效位解析到最低有效位。这样就能访问每个位值。不过,在解析完整文件时,需要确保忽略不再属于图像的多余位(如果图像的总像素数不能被 8 整除)。构造了单像素值解析器之后,现在可以为图像文件主体构造解析器。
12.2.4 组合解析器(Putting parsers together)
图像文件主体解析器可以通过对已经解析出的头部做分支判断来构造。根据给定的 magic number 和最大值,从上一小节中选择一个解析器来读取数据。除了二进制位图解析器之外,所有解析器都会读取单个 RawPixel 值,因此只需要把它应用需要的像素数量次,也就是图像宽度乘以高度。另外,我们构造一个可选空白解析器,用于 ASCII 编码数据。对于位图,数据中不需要空白,但我们仍然允许它们,以便捕获换行等。对于二进制灰度图和像素图,必须根据给定最大值选择正确解析器。否则,我们会忽略最大值。这样做是因为如果某个值大于头部中的最大值,解析器不应该在这一阶段失败。我们希望稍后检查这类属性。唯一特殊情况是二进制位图的处理,它必须以稍微不同的方式解析。很快就会处理这个情况。现在先讨论下面清单中的图像数据解析器实现。
代码清单 12.28 PNM 文件图像数据解析器
dataP :: Header -> Parser RawData
dataP (Header {..}) = do
pixels <- case (magicNumber, maxVal) of
(P1, _) -> count' $ whitespaces' *> p1PixelP -- #1
(P2, _) -> count' $ whitespaces' *> p2PixelP -- #1
(P3, _) -> count' $ whitespaces' *> p3PixelP -- #1
(P4, _) -> p4DataP width' height' -- #1
(P5, Just mv) ->
count' $ -- #1
if mv <= 255 -- #2
then p5PixelWord8P -- #2
else p5PixelWord16P -- #2
(P6, Just mv) ->
count' $ -- #3
if mv <= 255 -- #2
then p6PixelWord8P -- #2
else p6PixelWord16P -- #2
_ ->
error $ -- #4
"Internal error: "
++ show magicNumber
++ " without maximum value in header!"
return $ RawData pixels
where
whitespaces' = option () whitespaces -- #5
count' = count (width' * height') -- #6
width' = fromInteger width
height' = fromInteger height
- #1 根据头部 magic number 定义的合适格式解析图像数据,并把特定解析器重复固定次数
- #2 用合适的位宽解析单个像素
- #3 根据头部 magic number 定义的合适格式解析图像数据,并把特定解析器重复固定次数
- #4 如果头部格式不正确,则抛出错误
- #5 定义一个可选跳过空白的解析器
- #6 定义一个组合子,按图像数据应有的像素数量运行解析器
count' 函数会把给定解析器应用需要的次数。对 magic number 和最大值的 case 提供了正确动作,该动作会被求值以读取 pixels 值。我们的类型允许 P5 和 P6 在没有最大值的情况下出现。不过,这是不允许的,应当导致内部错误。如果发生这种情况,头部解析器本应失败。因此,如果碰到这个问题,就说明头部解析器在某种意义上表现不正确。
可以看到,除了二进制位图解析器之外,所有解析器都与 count' 一起使用。这是因为我们从二进制位图解析器中读取的不是单个 RawPixel 值,而是一次读取八个。必须构造一个算法,从字节中解析这些值,但在解析到足够多的值后停止。此外,这些二进制位图包含值的栅格。每一行由图像宽度指定的位数组成。不过,这些行会打包进字节!这意味着每一行可能包含一些必须忽略的额外位。根据规范,可以简单忽略这些多余位。为做到这一点,可以定义一个递归动作,分别解析每一行:递归读取所需数量的位,并忽略其余部分。然后,可以把行连接成一个大型 RawPixel 值列表。实现如下所示。
代码清单 12.29 二进制位图文件中的图像数据解析器
p4DataP :: Int -> Int -> Parser [RawPixel]
p4DataP width height = do
rows <- count height (reverse <$> readRow width []) -- #1
return $ concat rows
where
readRow n pxs
| n <= 0 = return pxs -- #2
| otherwise = do
(b7, b6, b5, b4, b3, b2, b1, b0) <- p4PixelP -- #3
case n of
1 -> return $ b7 : pxs -- #4
2 -> return $ b6 : b7 : pxs -- #4
3 -> return $ b5 : b6 : b7 : pxs -- #4
4 -> return $ b4 : b5 : b6 : b7 : pxs -- #4
5 -> return $ b3 : b4 : b5 : b6 : b7 : pxs -- #4
6 -> return $ b2 : b3 : b4 : b5 : b6 : b7 : pxs -- #4
7 -> return $ b1 : b2 : b3 : b4 : b5 : b6 : b7 : pxs -- #4
8 -> return $ b0 : b1 : b2 : b3 : b4 : b5 : b6 : b7 : pxs -- #4
_ -> -- #4
readRow -- #5
(n - 8) -- #4
(b0 : b1 : b2 : b3 : b4 : b5 : b6 : b7 : pxs) -- #4
- #1 读取与图像高度相同数量的行
- #2 读取完成时返回已读取像素
- #3 用解析器解析一个字节,并提取单像素值
- #4 如果从解析源中还需读取的不足一个字节,则返回正确数量的位
- #5 递归解析更多字节,直到读完一行中指定数量的像素
这里在考虑位顺序时必须小心。我们从最高有效位解析到最低有效位,但会以相反顺序把它们加入每一行的结果列表。随后,这些列表会被反转。我们在 readRow 中跟踪还需要读取多少元素,一旦所需数量少于九,就可以只把正确数量的值放进结果。
注意 为了性能,我们按反向顺序添加值。否则,就不能用
(:)构造器把元素加到前面,而需要使用追加函数(++)。追加函数非常昂贵,因为它必须遍历整个列表才能添加新元素。递归这样做很快会让大列表变得不可行。按反向顺序添加元素,然后在之后反转整个结果,会便宜得多。
读取完所有行之后,可以连接所有值,得到完整的 [RawPixel] 数据。所有格式的解析都处理完后,就能把所有部件组合起来了!
有了 headerP 和 dataP,我们已经为图像文件的头部和主体都构造了解析器。现在把它们组合起来,构造通用 PNM 文件解析器。如下所示。
代码清单 12.30 PNM 文件解析器和解析函数
pnmP :: Parser RawPnm
pnmP = do
header <- headerP -- #1
imageData <- dataP header -- #2
option () whitespaces -- #3
return RawPnm {..}
parsePnm :: BS.ByteString -> Either String RawPnm
parsePnm = parseOnly (pnmP <* endOfInput) -- #4
readPnmFile :: FilePath -> IO (Either String RawPnm)
readPnmFile path = parsePnm <$> BS.readFile path -- #5
- #1 解析头部
- #2 根据头部解析图像数据
- #3 跳过所有尾随空格
- #4 从字节串解析 PNM 图像,并要求解析器到达字符串末尾,否则失败
- #5 解析 PNM 文件,并要求解析器到达文件末尾,否则失败
读取头部和数据之后,还会跳过文件中可能仍然存在的所有空白。这样做是为了确保已经到达文件末尾。在 parsePnm 中,我们主动强制要求:如果没有读取完整输入,解析必须失败。这是通过 endOfInput 实现的。如果应用 pnmP 后解析器没有停在文件末尾,endOfInput 就会直接失败。
练习:解析多张图像
本章展示的解析器只能从文件中读取一张 PNM 图像。不过,规范允许单个文件中存在多张图像。你能修改解析函数以支持这一点吗?
如果想尝试新构建的解析器,本书代码仓库提供了不同大小和格式的示例图像。
我们已经为 PNM 文件格式构建了一个解析器,并且可以从文件中读取图像数据。下一章会关心如何使用并行处理这些数据,以提升执行速度。
总结
- Functor 用于以引用透明的方式修改某个效果求值得到的值。
- Applicative 可用于组合带有效果的动作,例如处理输入或解析文件内容。
Alternative让 applicative 能够在成功和失败的动作之间选择,例如让解析器能够从递归结构深处返回错误消息。- Monad 可用于组合带有效果的动作,同时让前面动作的结果影响新结果,从而有效地串联动作,并仍然保持一致的错误处理。
MonadFail用于赋予单子类型失败能力,从而让 monad 显式进入失败状态。MonadPlus是Alternative的单子版本,让 monad 拥有在成功和失败动作之间选择的能力。- 当需要在低层操作数字和字节串时,可以使用
Data.Bits中的函数完成位级操作。