第 13 章 - 并行图像处理(Parallel image processing)
本章内容包括:
- 使用泛化代数数据类型
- 安全地避免返回类型多态
- 编写用于转换图像数据的通用算法
- 使用并行提升性能
上一章中,我们为 PNM 文件构建了解析器。PNM 是一种简单图像格式。虽然已经介绍了如何读取这些文件,但还没有创建转换它们并写回文件系统的方式。本章会改变这一点。
我们想介绍如何使用 Haskell 的类型系统创建一种数据类型,它可以动态存储多种类型的数据,而不需要使用参数多态,同时仍然能在稍后取回这些数据的类型信息。然后,我们会为解析出的数据定义验证逻辑,并定义一种通用方式映射不同类型的数据。最后,我们会介绍如何并行执行工作,并只用一行代码让程序性能提升一倍以上。
13.1 向调用者提供类型信息(Providing type information to the caller)
上一章完全围绕可移植 anymap 格式(PNM)的图像解析展开。现在这些图像已经进入程序,我们应该对它们做点什么。来处理它们吧!更具体地说,我们想构建一种通用方式,以编程方式改变图像像素。这将允许我们编写不同滤镜,例如:
为了加速处理,我们会使用并行来利用多核 CPU。最终,我们想把图像(无论是否处理过)以 PNG 格式存储到磁盘上,为此会使用 JuicyPixels 库。
13.1.1 返回类型多态性问题(Problems with return-type polymorphism)
首先回顾一下上一章停在哪里。我们已经编写了一个解析器,用于读取 PNM 格式文件。它会读取文件数据,并使用 RawPnm 类型生成 Haskell 表示。引入的类型如下所示。
代码清单 13.1 用于解析 PNM 文件的类型
data MagicNumber = P1 | P2 | P3 | P4 | P5 | P6 -- #1
deriving (Eq, Show)
data Header = Header -- #2
{ magicNumber :: MagicNumber,
width :: Integer,
height :: Integer,
maxVal :: Maybe Word16
}
deriving (Eq, Show)
data RawPixel
= Single Word16 -- #3
| RGB Word16 Word16 Word16 -- #4
deriving (Eq, Show)
newtype RawData = RawData -- #5
{ pixels :: [RawPixel]
}
deriving (Eq, Show)
data RawPnm = RawPnm -- #6
{ header :: Header,
imageData :: RawData
}
deriving (Eq, Show)
- #1 定义 magic number 类型
- #2 定义 PNM 文件头部类型
- #3 定义由单个值组成的像素(灰度或黑白)
- #4 定义由红、绿、蓝通道组成的像素
- #5 定义用于存储原始像素的类型
- #6 定义已解析 PNM 文件的类型
这些类型表示从文件中读取出的原始数据。这些类型的值直接来自解析器,意味着还没有对它们做任何验证。这就是我们首先应该处理的事情。上一章结束时,PNM 解析代码留下了如下模块结构。
代码清单 13.2 第 12 章中的模块结构
src/
└── Graphics
├── PNM
│ ├── Parsing.hs
│ └── Types.hs
└── PNM.hs
现在想创建一个 Graphics.PNM.Validation 模块,它会提供负责验证的函数。回顾一下,PNM 文件可以是位图、灰度图和像素图格式,并且可以用 ASCII 或二进制编码。这由文件头部给出的 magic number 表示。根据格式,像素要么编码为单个数字(位图或灰度图),要么由三个数字编码(像素图)。此外,格式会在头部指定最大值,说明颜色值的最大数值应该是多少。
上一章编写的解析器不会验证它解析的数据。验证需要包含几个步骤,用于检查以下内容:
这个过程应该返回某种可以安全使用的类型。这个类型应该长什么样?首先,像素类型应该长什么样?由于我们知道 PNM 文件要么是 8 位编码,要么是 16 位编码,所以希望保留这种差异。在解析器中,我们用 Word16 编码了 8 位值,这有点浪费,所以不要继续这样做。像素类型可以如下:
import Data.Word (Word8, Word16)
data Pixel8Bit = Pixel8Bit Word8 Word8 Word8
data Pixel16Bit = Pixel16Bit Word16 Word16 Word16
不过,不必重新发明轮子。这些类型已经由 JuicyPixels 包提供,而稍后我们会用它把 PNM 数据转换为 PNG 图像!因此,把这个包中的类型整合进我们的图像类型是合理的。
为此,在 package.yaml 文件中把 JuicyPixels 加入依赖。现在,可以使用 Codec.Picture 模块中的 PixelRGB8 和 PixelRGB16 类型。另外,该模块还为灰度像素提供了 Pixel8 和 Pixel16 类型,它们也会派上用场:
ghci> :t PixelRGB8
PixelRGB8 :: Pixel8 -> Pixel8 -> Pixel8 -> PixelRGB8
ghci> :t PixelRGB16
PixelRGB16 :: Pixel16 -> Pixel16 -> Pixel16 -> PixelRGB16
ghci> :i Pixel8
type Pixel8 :: *
type Pixel8 = Word8
ghci> :i Pixel16
type Pixel16 :: *
type Pixel16 = Word16
稍后如何使用这个包把数据写成 PNG?为此,库提供了 DynamicImage 类型,它会在内部以位深、彩色或灰度、颜色模型等方式编码正在保存的图像类型。为了稍后正确使用这个类型,需要跟踪当前使用的像素类型。
现在可以问一个问题:如何构造图像类型?一个包含图像基本信息的简单类型可能如下:
import qualified Codec.Picture as P
data PnmImage = PnmImage
{ width :: Int,
height :: Int,
pixels :: Either [P.PixelRGB8] [P.PixelRGB16]
}
不过,如果还想存储灰度像素,就需要类似 Either 但有四种选择的类型。这样可能会得到如下类型:
data ArbitraryPixels
= Pixels8Bit [P.PixelRGB8]
| Pixels16Bit [P.PixelRGB16]
| GrayPixels8Bit [P.Pixel8]
| GrayPixels16Bit [P.Pixel16]
data PnmImage = PnmImage
{ width :: Int,
height :: Int,
pixels :: ArbitraryPixels
}
这个方案起初看起来还行,但并不实用。首先,无法指定某个函数只接受特定像素类型的图像,因为 Image 类型没有参数。使用这个类型时,总是需要对 pixels 的构造器做模式匹配,以找出内部类型。另外,PNM 格式还有一个扩展,可以使用 32 位像素值。如果有一天想支持它,就必须继续扩展这个类型,以及所有对它做模式匹配的函数。所以这个方案并不实用。
可以通过给 Image 类型添加参数来解决这一点。这样,就能在类型系统中指定正在处理哪种图像:
data PnmImage px = PnmImage
{ width :: Int,
height :: Int,
pixels :: [px]
}
不过,这带来了新问题。我们想构建的验证函数应该长什么样?它的类型是什么?可能看起来像这样:
validatePnm :: RawPnm -> Either String (PnmImage px)
这看起来不错,直到我们思考类型变量 px 在哪里被决定。不能在 validatePnm 内部决定 px 的类型,因为 Haskell 使用返回类型多态,这一点在第 9 章已经介绍过。这意味着函数的调用者决定函数的返回类型!然而,对我们的目的来说,这完全反了。调用者在验证之前不可能知道期望的图像类型。validatePnm 函数应该决定它是哪种图像,检查其有效性,然后产生合适的值。如何把选择类型的责任转移给这个函数?
13.1.2 泛化代数数据类型(Generalized algebraic data types)
我们的问题很简单。调用者在调用验证函数之前无法决定其类型,所以它的类型应该是多态的。不过,当我们想处理解析结果时,需要一种方式细化类型。这意味着需要一种方式把多态类型细化为具体类型。Haskell 类型系统的一个扩展提供了这个功能,名为泛化代数数据类型(GADT)。可以通过 GADTs 语言扩展启用它。
GADT 在很大程度上等价于我们通常使用的代数数据类型。它们由构造器组成,而构造器又由字段组成。不过,遇到的第一个差异是 GADT 使用的语法:
{-# LANGUAGE GADTs #-}
...
data MyAdt a
= AdtCons1 Int Float String
| AdtCons2 Bool a
data MyGADT a where
GadtCons1 :: Int -> Float -> String -> MyGADT a
GadtCons2 :: Bool -> a -> MyGADT a
这两个数据类型是等价的。MyAdt 和 MyGadt 拥有等价构造器、等价字段,以及最重要的等价类型。可以看到,我们的 GADT 两个构造器类型都是 MyGADT a。这正是 ADT 的工作方式,因为它们始终是 MyAdt a 类型。
不过,GADT 的类型可以依赖于所使用的构造器!稍微修改一下定义:
data MyGADT a where
GadtCons1 :: Int -> Float -> String -> MyGADT Bool
GadtCons2 :: Bool -> a -> MyGADT String
现在,由构造器决定多态类型(a)会是什么。
ghci> :t GadtCons1 1 1.0 "Hi!"
GadtCons1 1 1.0 "Hi!" :: MyGADT Bool
ghci> :t GadtCons2 True (1 :: Int)
GadtCons2 True (1 :: Int) :: MyGADT [Char]
这有什么帮助?它允许定义多态但受 GADT 类型约束的函数:
data GiveMe a where
SomeString :: GiveMe String
SomeInt :: GiveMe Int
giveMe :: GiveMe a -> a
giveMe SomeString = "Hello"
giveMe SomeInt = 1
giveMe 的定义完全合法,即使它会根据匹配到的构造器返回不同类型。这是因为 GiveMe 的类型。由于 SomeString 的类型是 GiveMe String,这意味着 giveMe SomeString 必须是 String 类型,因为 GiveMe a 中的 a 被 GiveMe String 中的 String 替换了。Haskell 足够聪明,可以根据匹配到的构造器静态推断所需类型。因此,这个定义能够通过类型检查,并按预期工作:
ghci> giveMe SomeString
"Hello"
ghci> giveMe SomeInt
1
GADT 是类型类的重要对应物。类型类把类型映射到项,而 GADT 把项映射到类型。类型类用于让我们编写多态代码,同时仍然使用具体实现。GADT 能够在构造器被匹配时细化多态类型。这正是 giveMe 定义能按预期工作的原因。
可以在代码中利用这一点,让验证函数调用者知道正在使用哪种像素类型。假设使用这样的图像类型:
data Image px where
Image8Bit ::
Int ->
Int ->
[P.PixelRGB8] ->
Image P.PixelRGB8
Image16Bit ::
Int ->
Int ->
[P.PixelRGB16] ->
Image P.PixelRGB16
现在,可以为这个类型的值创建函数,并对构造器做匹配。与 ADT 的不同之处在于,匹配 GADT 会在匹配分支内部细化类型。看一个例子:
to16Bit :: Image px -> Image P.PixelRGB16
to16Bit img =
case img of -- #1
Image8Bit w h pxs -> Image16Bit w h (map pixel8To16 pxs) -- #2
Image16Bit {} -> img -- #3
where
pixel8To16 :: P.PixelRGB8 -> P.PixelRGB16
pixel8To16 (P.PixelRGB8 r g b) = -- #4
let f x = 256 * fromIntegral x -- #5
in P.PixelRGB16 (f r) (f g) (f b)
- #1 对类型为
Image px的输入参数做匹配 - #2 匹配
Image8Bit构造器,并细化pxs的类型(Haskell 现在静态知道pxs的类型是[PixelRGB8]) - #3 匹配
Image16Bit构造器(忽略其字段),并返回匹配到的参数,因为它已经符合所需类型 - #4 定义把
PixelRGB8映射为PixelRGB16值的函数 - #5 把
Word8缩放为Word16
从这个例子可以看到,参数类型 Image px 是多态的。不过,函数可以把这个多态类型合并为 PixelRGB16,而不会牺牲任何类型安全。Haskell 能够静态推断存在哪些构造器、它们隐含哪些类型,以及我们是否正确使用这些类型。
13.1.3 Vector 类型(The Vector type)
现在可以思考如何设计图像类型。它应该能够保存图像宽度、高度,以及以某种像素值类型编码的图像数据。上一章中,我们使用简单列表存储像素。虽然列表适合较小数据量,但在访问元素方面性能特征较差。由于稍后这会很重要,所以希望使用其他数据结构。
在我们的用例中,可以使用 vector 包中的 Vector 数据类型。Vector 类似其他语言中的数组,可以在常数时间内索引值。常见操作,例如 take、drop 或 splitAt,也能在常数时间内执行。不过,对于添加新元素或追加多个 Vector 值这样的操作,Vector 类型会更慢。这一点也很像其他语言中的普通数组,动态扩容数组必须在内存中一次又一次复制。
在库中,我们想存储图像数据,稍后还要高效地映射它。为此,也希望能够读取图像中的单个像素,以便后续组合它们。因此,我们执行的大部分工作是读取数据,而不是写入数据,这让 Vector 类型成为不错候选。
可以在 package.yaml 的依赖部分加入 vector 包。Vector 值可以通过 cons 和 snoc 在前面或后面添加值来创建,也可以简单地用 fromList 函数把普通列表转换成 vector:
ghci> import Data.Vector as V
ghci> :t V.empty
V.empty :: Vector a
ghci> :t V.cons
V.cons :: a -> Vector a -> Vector a
ghci> V.cons 1 V.empty :: V.Vector Int
[1]
ghci> V.fromList [1..10] :: V.Vector Int
[1,2,3,4,5,6,7,8,9,10]
一个好想法是先惰性构建列表,稍后再把它转换为 vector。这样可以利用许多允许我们从简单函数构建列表的函数(想想上一章中的解析器组合子),然后构建更紧凑、索引和读取速度更快的表示。
注意 Vector 在结构上并不总是惰性的。这意味着通常不能像普通列表那样创建无限
Vector值。下面的代码会持续吃掉内存,直到程序崩溃:V.take 100 $ V.concat [V.empty, (V.fromList [1..])]。
现在,可以向上一章中的 Graphics.PNM.Types 模块添加一个新类型。这个类型会提供四个构造器,用于编码 8 位和 16 位变体中的灰度图和彩色图。每个构造器都会保存宽度、高度和像素信息。后者会用 Vector 类型编码。
代码清单 13.3 存储 PNM 图像的类型
{-# LANGUAGE GADTs #-} -- #1
module Graphics.PNM.Types where
import qualified Codec.Picture as P -- #2
import qualified Data.Vector as V -- #2
...
data PnmImage px where -- #3
PnmGray8Bit :: -- #4
Int ->
Int ->
V.Vector P.Pixel8 ->
PnmImage P.Pixel8
PnmGray16Bit :: -- #5
Int ->
Int ->
V.Vector P.Pixel16 ->
PnmImage P.Pixel16
PnmColor8Bit :: -- #5
Int ->
Int ->
V.Vector P.PixelRGB8 ->
PnmImage P.PixelRGB8
PnmColor16Bit :: -- #5
Int ->
Int ->
V.Vector P.PixelRGB16 ->
PnmImage P.PixelRGB16
- #1 启用
GADTs语言扩展,以便在文件中使用 GADT - #2 导入所需模块
- #3 定义用于编码已验证 PNM 图像的数据类型
- #4 为不同种类的 PNM 图像定义构造器
- #5 为不同种类的 PNM 图像定义构造器
这个定义中能不能使用记录语法?理论上,定义 GADT 时可以使用记录语法,但在这个上下文中不能使用,因为第三个字段(像素)在每个构造器中类型不同,并不能与多态类型 px 匹配。不过,我们应该写几个函数来访问宽度、高度和像素数据。对于像素,这个函数现在确实能工作,因为它在 px 类型变量上是多态的。这些函数如下所示。
代码清单 13.4 访问 PNM 图像字段的函数
pnmWidth :: PnmImage px -> Int -- #1
pnmWidth (PnmGray8Bit w _ _) = w
pnmWidth (PnmGray16Bit w _ _) = w
pnmWidth (PnmColor8Bit w _ _) = w
pnmWidth (PnmColor16Bit w _ _) = w
pnmHeight :: PnmImage px -> Int -- #2
pnmHeight (PnmGray8Bit _ h _) = h
pnmHeight (PnmGray16Bit _ h _) = h
pnmHeight (PnmColor8Bit _ h _) = h
pnmHeight (PnmColor16Bit _ h _) = h
pnmPixels :: PnmImage px -> V.Vector px -- #3
pnmPixels (PnmGray8Bit _ _ pixels) = pixels
pnmPixels (PnmGray16Bit _ _ pixels) = pixels
pnmPixels (PnmColor8Bit _ _ pixels) = pixels
pnmPixels (PnmColor16Bit _ _ pixels) = pixels
- #1 定义提取
PnmImage宽度的函数 - #2 定义提取
PnmImage高度的函数 - #3 定义提取
PnmImage像素的函数
你可能会疑惑为什么没有为新类型派生 Show 或 Eq。原因是不能对 GADT 使用通常的 deriving 关键字。为了仍然为它们派生类型类实例,必须使用 StandaloneDeriving 扩展,并提供单独表达式来完成这项工作。
代码清单 13.5 为 GADT 派生类型类实例
{-# LANGUAGE StandaloneDeriving #-} -- #1
...
deriving instance (Show px) => Show (PnmImage px) -- #2
deriving instance (Eq px) => Eq (PnmImage px) -- #3
- #1 启用
StandaloneDeriving语言扩展 - #2 在存在
Show px实例时,为PnmImage px派生Show实例 - #3 在存在
Eq px实例时,为PnmImage px派生Eq实例
有了代码清单 13.5,字段选择器和实例都处理好了,暂时可以认为 PnmImage 类型定义完成。现在这个类型处理完了,我们终于能编写验证函数了吗?
13.1.4 使用存在量化的动态类型(Dynamic types with existential quantification)
遗憾的是,还没准备好写验证函数。引入 GADT 的全部原因,是为了让验证函数能够决定像素类型。不过,当函数返回 PnmImage px 时,返回类型多态仍然会限制我们。使用 GADT 只是解决谜题的第一部分,因为它允许函数调用者细化多态类型。
现在,还必须找到一种方式,禁止调用者选择该类型。需要一种方式把函数返回值中的类型参数隐藏起来。第 11 章已经讨论过一个漂亮技巧,也就是 Haskell 类型系统的另一个扩展:ExistentialQuantification。
简单回顾一下,有了这个扩展,可以创建有效隐藏自身类型变量的数据类型。这让我们可以创建一种能保存多态类型的类型,而它自身并不是多态的。唯一需要关心的是如何再次从该类型取回信息。通常会用类型约束解决这个问题,但在当前场景中,我们稍微幸运一些。
代码清单 13.6 PNM 图像动态数据类型的定义
{-# LANGUAGE ExistentialQuantification #-} -- #1
...
data DynamicPnmImage = forall px. DynamicPnmImage (PnmImage px) -- #2
- #1 启用
ExistentialQuantification语言扩展 - #2 定义一种可以保存任意
px类型的PnmImage px值的类型
观察代码清单 13.6,会发现其实不需要类型约束。为什么?难道最终这个值不会变得没用吗?并不是这样,因为仍然知道放入 DynamicPnmImage 构造器内部的东西是 GADT PnmImage。正如前面讨论过的,匹配 GADT 构造器会细化其类型。这意味着,在匹配构造器内部值之后,我们就知道正在处理哪种图像。我们不会丢失类型信息!现在,终于可以编写验证函数:它接收任意解析结果,并创建 DynamicPnmImage,稍后可以用它弄清验证函数内部存储的是哪种图像类型。
13.2 解析数据验证(Validation of parsed data)
先提醒一下验证函数应该做什么。它应该检查以下内容:
上一章编写的解析器在产生 RawPnm 值时不会执行验证。现在可以编写一个函数,把 RawPnm 转换为 DynamicPnmImage 值,同时检查前面的断言成立。我们希望把这个函数放入名为 Graphics.PNM.Validation 的新模块中,稍后会从 Graphics.PNM 模块重新导出它。
可以从思考如何转换并验证单个像素开始验证过程。对于位图像素,解析器应该返回使用 Single 构造器的 RawPixel 值,颜色值要么是 0,要么是 1,因为位图图像是黑白的。我们会把这些像素映射到 JuicyPixels 包中的 Pixel8 类型,因为它们表示 8 位灰度像素值。这个类型只是 Word8 值的别名,所以可以返回简单数字。记住,在 PNM 中 1 表示黑色。验证单个位图像素的函数如下所示。
代码清单 13.7 把原始像素转换为位图像素的函数
module Graphics.PNM.Validation where
import Graphics.PNM.Types
import qualified Codec.Picture as P
bitmapPixel :: RawPixel -> Either String P.Pixel8
bitmapPixel (Single 1) = Right 0 -- #1
bitmapPixel (Single 0) = Right 255 -- #1
bitmapPixel p =
Left $ -- #2
"Could not convert "
<> show p
<> " to a bitmap pixel"
- #1 根据给定
RawPixel返回黑色或白色像素值 - #2 如果
RawPixel不表示位图像素,则返回错误消息
和前几章一样,我们使用 Either 类型编码验证错误。注意,这里不检查像素值是否超过最大值,因为位图图像不应该设置最大值。稍后会检查这个属性。
当处理灰度图像素时,最大值很重要。根据最大值,需要返回 Pixel8 或 Pixel16,但这个选择会在函数外部决定。由于 Pixel16 是 Word16 的别名,可以返回任意类型。检查值是否小于或等于最大值之后,可以按给定值与最大值之间的比率缩放像素值。如下所示。
代码清单 13.8 把原始像素转换为灰度图像素的函数
import Data.Word
...
graymapPixel ::
(Integral px) =>
Word16 ->
RawPixel ->
Either String px
graymapPixel maxVal pixel@(Single g)
| g > maxVal = -- #1
Left $
"The pixel "
<> show pixel
<> " exceeds the maximum value "
<> show maxVal
| otherwise = Right v -- #2
where
factor = fromIntegral g / fromIntegral maxVal -- #3
v = round $ fromIntegral maxVal * factor -- #4
graymapPixel _ p =
Left $ -- #5
"Could not convert "
<> show p
<> " to a graymap pixel"
- #1 检查给定像素是否超过最大值,并返回错误消息
- #2 返回缩放后的值
- #3 计算给定值与最大值之间的比率
- #4 按给定值与最大值之间的比率缩放最大值
- #5 如果
RawPixel不表示灰度图像素,则返回错误消息
为了使用 round,必须在代码中添加 Integral 类作为类型约束。值如何舍入由返回类型决定,而返回类型由调用者决定。
对于像素图像素,本质上做同样的事,但转换作用于 RGB 值的 RawPixel 类型。结果类型也与之前很不同,因为现在必须返回 PixelRGB8 或 PixelRGB16 值。这两个构造器都接收三个值(类型分别为 Pixel8 或 Pixel16):
ghci> import Codec.Picture
ghci> :t PixelRGB8
PixelRGB8 :: Pixel8 -> Pixel8 -> Pixel8 -> PixelRGB8
ghci> :t PixelRGB16
PixelRGB16 :: Pixel16 -> Pixel16 -> Pixel16 -> PixelRGB16
为了让验证函数尽可能通用,可以要求一个参数,该参数匹配这些构造器的多态版本。调用者随后可以把合适构造器传给函数,以指定结果类型。函数如下所示。
代码清单 13.9 把原始像素转换为像素图像素的函数
pixmapPixel ::
(Integral val) =>
Word16 ->
(val -> val -> val -> px) ->
RawPixel ->
Either String px
pixmapPixel maxVal f pixel@(RGB r g b)
| r > maxVal || g > maxVal || b > maxVal = -- #1
Left $
"The pixel "
<> show pixel
<> " exceeds the maximum value "
<> show maxVal
| otherwise =
Right $
f (transform r) (transform g) (transform b) -- #2
where
factor x = fromIntegral x / fromIntegral maxVal -- #3
transform x = round $ fromIntegral maxVal * factor x -- #4
pixmapPixel _ _ p =
Left $ -- #5
"Could not convert "
<> show p
<> " to a pixmap pixel"
- #1 检查给定红、绿、蓝值是否超过最大值,并返回错误消息
- #2 返回缩放后的红、绿、蓝值,并使用作为参数给出的函数包装它们,产生最终结果
- #3 计算给定值与最大值之间的比率
- #4 按给定值与最大值之间的比率缩放最大值
- #5 如果
RawPixel不表示像素图像素,则返回错误消息
为了构建验证函数,最好能从 magic number 推断正在处理哪种图像。可以创建几个简单辅助函数来帮助我们,如下所示。
代码清单 13.10 验证辅助函数
indicatesBitmap :: MagicNumber -> Bool -- #1
indicatesBitmap P1 = True
indicatesBitmap P4 = True
indicatesBitmap _ = False
indicatesGraymap :: MagicNumber -> Bool -- #2
indicatesGraymap P2 = True
indicatesGraymap P5 = True
indicatesGraymap _ = False
indicatesPixmap :: MagicNumber -> Bool -- #3
indicatesPixmap P3 = True
indicatesPixmap P6 = True
indicatesPixmap _ = False
imageSizeCorrect :: RawPnm -> Bool -- #4
imageSizeCorrect RawPnm {header, imageData} =
let expectedNumPixels =
fromIntegral $ width header * height header
numPixels = length $ pixels imageData
in numPixels == expectedNumPixels
- #1 定义一个检查给定 magic number 是否表示位图图像的函数
- #2 定义一个检查给定 magic number 是否表示灰度图图像的函数
- #3 定义一个检查给定 magic number 是否表示像素图图像的函数
- #4 定义一个检查头部建议的图像大小是否与像素数量匹配的函数
为方便起见,还添加了一个函数,用于检查值中存在的像素数量是否等于头部建议的数量。注意,为了让这个定义合法,必须启用 NamedFieldPuns 扩展。现在思考如何检查图像中的像素是否正确。我们已经写了检查单个像素的函数,但需要检查原始图像的所有像素。另外,希望在转换像素期间返回发生的第一个错误(Left 值)。幸运的是,不必为此编写特殊函数,因为可以利用 Either a 是一个 monad 这一事实。
回想上一章,我们学到,如果计算中任何地方出现 Nothing,Maybe monad 总会合并为 Nothing。Either a 和 Left 构造器也类似。因此,必须把像素转换函数映射到像素列表上,并把这些计算视为 Either a monad 中的计算。事实证明,我们在第 4 章已经见过正好做这件事的函数:mapM。
ghci> :t mapM
mapM :: (Traversable t, Monad m) => (a -> m b) -> t a -> m (t b)
ghci> :{
ghci| f :: Int -> Either String Int
ghci| f 0 = Left "zero is not allowed"
ghci| f x = Right x
ghci| :}
ghci> mapM f [1..10]
Right [1,2,3,4,5,6,7,8,9,10]
ghci> mapM f [0..10]
Left "zero is not allowed"
之前没有讨论过 mapM 函数的完整类型,因为当时还不了解类型约束和 monad。mapM 在单子上下文中操作一个 Traversable(列表就是)。传给 mapM 的函数会为每个元素求值得到一个单子动作(m b),这些结果被收集到结果 m (t b) 中。mapM 本质上遍历列表,并逐个应用单子动作。由于 Either a monad 会短路为 Left,整个计算也会如此!
注意 严格来说,可以把
mapM替换为traverse,它的类型是Applicative f => (a -> f b) -> t a -> f (t b)。mapM功能基本等价,但使用Monad约束而不是Applicative。对于Either a,这没有区别。
现在所有拼图都处理好了,可以编写验证函数了。它应该检查所有断言,并在验证成功时,把正确类型的 PnmImage 包装进 DynamicPnmImage。函数如下所示。
代码清单 13.11 PNM 解析结果的验证函数
import qualified Data.Vector as V
...
validatePnm :: RawPnm -> Either String DynamicPnmImage
validatePnm img@(RawPnm {header, imageData})
| not $ imageSizeCorrect img =
Left $ -- #1
"The number of pixels given does not match "
<> "the expected size inferred from the header"
| indicatesBitmap magicNum =
case maxVal header of
Nothing -> PnmGray8Bit `withTransform` bitmapPixel -- #2
Just _ ->
Left $ -- #1
"Image seems to be a bitmap image "
<> "but has a maximum value set"
| indicatesGraymap magicNum =
case maxVal header of
Nothing ->
Left $ -- #1
"Image seems to be a graymap image "
<> "but has no maximum value set"
Just maxVal ->
if maxVal <= 255
then
PnmGray8Bit -- #3
`withTransform` graymapPixel maxVal
else
PnmGray16Bit -- #3
`withTransform` graymapPixel maxVal
| indicatesPixmap magicNum =
case maxVal header of
Nothing ->
Left $ -- #1
"Image seems to be a pixmap image "
<> "but has no maximum value set"
Just maxVal ->
if maxVal <= 255
then
PnmColor8Bit -- #4
`withTransform` pixmapPixel maxVal P.PixelRGB8
else
PnmColor16Bit -- #4
`withTransform` pixmapPixel maxVal P.PixelRGB16
| otherwise = Left "Image seems to be of unknown type" -- #5
where
magicNum = magicNumber header
width' = fromIntegral $ width header
height' = fromIntegral $ height header
withTransform ::
(Int -> Int -> V.Vector px -> PnmImage px) ->
(RawPixel -> Either String px) ->
Either String DynamicPnmImage
withTransform c f =
let mConvertedData = mapM f $ pixels imageData -- #6
in fmap mkRes mConvertedData -- #7
where
mkRes = DynamicPnmImage . c width' height' . V.fromList -- #8
- #1 如果断言不成立,则返回错误消息
- #2 返回
PnmGray8Bit,并把原始数据转换为位图像素 - #3 根据最大值返回
PnmGray8Bit或PnmGray16Bit,并把原始数据转换为灰度图像素 - #4 根据最大值返回
PnmColor8Bit或PnmColor16Bit,并把原始数据转换为像素图像素 - #5 如果断言不成立,则返回错误消息
- #6 使用给定转换参数转换图像数据中的像素;如果转换失败,则提前停止
- #7 从成功转换创建最终结果
- #8 把像素数据转换为
Vector,并用作为参数给出的构造器把数据包装进DynamicPnmImage
这个定义乍看可能有点吓人,但只要理解 withTransform 函数,就变得可以掌控。它接收两个参数:c 是用于构建 PnmImage 的函数。这里只会使用 PnmImage 类型中的构造器。f 是转换函数,用于把原始图像数据翻译成 c 参数所需的像素类型。withTransform 使用中缀风格,让代码更可读。构造器与给定函数搭配使用,完成像素数据转换。
可以看到,validatePnm 能根据传入的数据(magic number 和图像数据)完全决定 PnmImage 的种类,并返回被包装在 DynamicPnmImage 中的特定构造器。像素也会被适当转换。注意,这个函数的调用者无法决定返回哪个 PnmImage。validatePnm 拥有完整责任。
13.3 通用图像转换算法(A generic algorithm for image conversion)
既然现在有了验证和编码图像的方式,就希望能够真正对图像做点事情。我们可能想对图像进行像素化,甚至创建模糊滤镜,但该如何做到?由于像素数据的类型会根据 PnmImage 构造器不同而不同,可能需要为不同像素类型编写多个版本的滤镜。能否提供一种通用方式来映射图像中的像素?
这样做迫使我们以通用方式处理像素。我们需要把具体像素类型(例如 Pixel8 或 PixelRGB16)转换成更通用的东西。这意味着要把某个类型映射到某种函数,以提供转换。正如已经讨论过的,类型类正是为这个目的而生。因此,我们定义一个表示通用像素的类型,以及一个提供到这种通用像素的转换函数和从这种通用像素转换回来的类型类,如下所示。
代码清单 13.12 通用像素类型和类型类
module Graphics.PNM.Conversion where
type GenericRGB = (Double, Double, Double) -- #1
class GenericPixel px where -- #2
toGenericRGB :: px -> GenericRGB -- #3
fromGenericRGB :: GenericRGB -> px -- #4
- #1 定义类型别名,把通用像素表示为三个
Double值 - #2 声明新的类型类定义
- #3 在
GenericPixel类型类中声明把多态类型转换为GenericRGB值的函数 - #4 在
GenericPixel类型类中声明把GenericRGB值转换回多态类型的函数
可以把代码清单 13.12 放入新模块,命名为 Graphics.PNM.Conversion。GenericRGB 类型表示像素的红、蓝、绿通道,范围是 0 到 1。这会让像素值计算更容易,因为不必在映射内部反复把整数值转换为 Double 再转换回来。
说到这里,由于像素是整数类型,需要一种方式把它们缩放到 GenericRGB 类型内部的范围。所有像素类型要么由 Word8 组成,要么由 Word16 组成,所以可以提供函数来适当缩放这些值。如下所示。
代码清单 13.13 在整数类型和 Double 之间转换的辅助函数
import Data.Word
...
clamp :: Double -> Double
clamp = max 0 . min 1 -- #1
scaleDown8Bit :: Word8 -> Double
scaleDown8Bit v = clamp $ (fromIntegral v) / 255.0 -- #2
scaleUp8Bit :: Double -> Word8
scaleUp8Bit v = round $ 255 * (clamp v) -- #3
scaleDown16Bit :: Word16 -> Double
scaleDown16Bit v = clamp $ (fromIntegral v) / 65535.0 -- #4
scaleUp16Bit :: Double -> Word16
scaleUp16Bit v = round $ 65535 * (clamp v) -- #5
- #1 把值夹到 0 到 1 的区间内
- #2 把
Word8缩放到 0 到 1 的区间 - #3 把 0 到 1 的区间缩放为
Word8 - #4 把
Word16缩放到 0 到 1 的区间 - #5 把 0 到 1 的区间缩放为
Word16
使用这些函数,可以为不同像素类型定义实例。不过必须记住,Pixel8 和 Pixel16 是类型同义词,必须使用 TypeSynonymInstances 语言扩展才能为它们定义实例。实例声明本身很直接。由于从技术上讲我们拥有红、绿、蓝三个通道,所以必须组合这些通道并对它们归一化,以得到单个灰度通道。理论上,可以使用更精细的通用类型来区分彩色像素和灰度像素,但我们希望保持代码简单,以便更容易定义映射。
代码清单 13.14 GenericPixel 类型类实例
import qualified Codec.Picture as P
...
instance GenericPixel P.Pixel8 where
toGenericRGB p = (p', p', p') -- #1
where
p' = scaleDown8Bit p
fromGenericRGB (r, g, b) = p -- #2
where
p = scaleUp8Bit $ (r + g + b) / 3
instance GenericPixel P.Pixel16 where
toGenericRGB p = (p', p', p') -- #3
where
p' = scaleDown16Bit p / 3
fromGenericRGB (r, g, b) = p -- #4
where
p = scaleUp16Bit $ (r + g + b) / 3
instance GenericPixel P.PixelRGB8 where
toGenericRGB (P.PixelRGB8 r g b) = -- #5
(scaleDown8Bit r, scaleDown8Bit g, scaleDown8Bit b)
fromGenericRGB (r, g, b) = -- #6
P.PixelRGB8
(scaleUp8Bit r)
(scaleUp8Bit g)
(scaleUp8Bit b)
instance GenericPixel P.PixelRGB16 where
toGenericRGB (P.PixelRGB16 r g b) = -- #7
(scaleDown16Bit r, scaleDown16Bit g, scaleDown16Bit b)
fromGenericRGB (r, g, b) = -- #8
P.PixelRGB16
(scaleUp16Bit r)
(scaleUp16Bit g)
(scaleUp16Bit b)
- #1 从单个整数值返回
GenericRGB - #2 从
GenericRGB值返回单个整数值 - #3 从单个整数值返回
GenericRGB - #4 从
GenericRGB值返回单个整数值 - #5 从 RGB 像素返回
GenericRGB - #6 从
GenericRGB值返回 RGB 像素 - #7 从 RGB 像素返回
GenericRGB - #8 从
GenericRGB值返回 RGB 像素
转换处理完后,可以思考映射函数应该长什么样。虽然只提供一个接口,把某个纯函数应用到单个像素上也可以,但这不一定足够强大,无法支持更有趣的图像操作。我们想实现的是映射 kernel 的方式。
13.3.1 图像转换矩阵算法(Image algorithm for conversion matrices)
Kernel,有时称为卷积矩阵,在图像处理中用于把多个像素组合成单个像素。可以把 kernel 看作一个在图像上“滑动”的矩阵,矩阵中心放在每个单独像素上,用来计算一个新像素。图 13.1 直观展示了这一点。把这种卷积应用到图像上会产生新图像。不同矩阵会产生不同效果,例如锐化和模糊。更复杂的技术,例如边缘检测,也可以使用 kernel 实现。
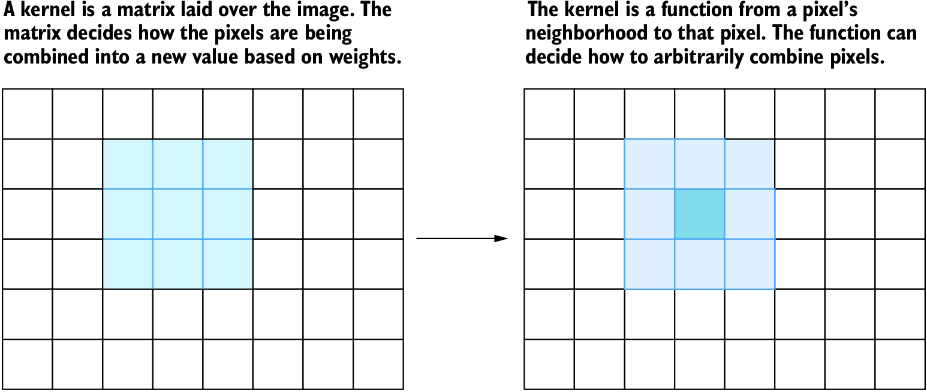
图 13.1 被解释为函数的图像 kernel 功能
不过,我们不只是想创建一个无聊的 kernel。我们想把 kernel 泛化成一个函数,它可以自由读取图像中的任意像素来产生新值。这样就可以模拟 kernel,也可以编写仅靠 kernel 无法实现的函数。
为此,创建一个类型别名,表示能够完成这个任务的函数。它接收当前像素的坐标,以及一个用于从图像中取回任意像素的函数。如果这个函数收到图像外的坐标,应该返回 Nothing 而不是值。最后,该函数接收当前像素。代码清单 13.15 展示了这一点。
代码清单 13.15 通用像素映射的类型同义词
type PixelMapping =
( Int -> -- #1
Int -> -- #2
(Int -> Int -> Maybe GenericRGB) -> -- #3
GenericRGB -> -- #4
GenericRGB -- #5
)
- #1 当前像素在 x 方向上的位置
- #2 当前像素在 y 方向上的位置
- #3 一个函数,给定坐标(x 和 y 值)后从图像中取回像素
- #4 图像中当前正在映射的像素
- #5 映射后当前坐标处得到的像素
有了这个定义,可以为每个像素创建简单映射、kernel,甚至更复杂的东西。为了构造映射函数,可以使用 Data.Vector 中的 imap,在遍历所有像素时拿到当前索引:
ghci> import qualified Data.Vector as V
ghci> vec = V.fromList [1..10] :: V.Vector Int
ghci> V.imap (\i x -> (i, x)) vec
[(0,1),(1,2),(2,3),(3,4),(4,5),(5,6),(6,7),(7,8),(8,9),(9,10)]
使用 imap 和 GenericPixel 类中的函数,可以创建一个 map 函数。它接收 PixelMapping,并把它应用到 DynamicPnmImage 内部的像素上,同时保持 PnmImage 的类型不变。如下所示。
代码清单 13.16 映射图像数据的通用函数
import qualified Data.Vector as V
import Graphics.PNM.Types
...
mapImagePixels ::
PixelMapping ->
DynamicPnmImage ->
DynamicPnmImage
mapImagePixels f (DynamicPnmImage img) =
case img of
PnmGray8Bit _ _ pxs ->
PnmGray8Bit `withPixels` mapping pxs -- #1
PnmGray16Bit _ _ pxs ->
PnmGray16Bit `withPixels` mapping pxs -- #1
PnmColor8Bit _ _ pxs ->
PnmColor8Bit `withPixels` mapping pxs -- #1
PnmColor16Bit _ _ pxs ->
PnmColor16Bit `withPixels` mapping pxs -- #1
where
w = pnmWidth img
h = pnmHeight img
withPixels ::
(Int -> Int -> V.Vector px -> PnmImage px) ->
V.Vector px ->
DynamicPnmImage
withPixels c pxs = DynamicPnmImage $ c w h pxs -- #2
mapping :: GenericPixel px => V.Vector px -> V.Vector px
mapping pixels =
flip V.imap pixels $ \i px ->
let x = i `mod` w -- #3
y = i `div` w -- #3
getPixel x' y' =
toGenericRGB <$> pixels V.!? (y' * w + x') -- #4
result = f x y getPixel $ toGenericRGB px -- #5
in fromGenericRGB result -- #6
- #1 匹配
PnmImage,并用映射后的像素创建新的DynamicPnmImage - #2 把
PnmImage构造器和匹配类型的像素包装进DynamicPnmImage,同时保留正确宽度和高度 - #3 根据当前像素索引计算 x 和 y 坐标
- #4 定义一个函数,安全访问
Vector中的像素并把它转换为GenericRGB - #5 使用当前坐标、从图像中取回任意像素的函数,以及当前像素调用
PixelMapping函数 - #6 把结果转换回正确的像素类型
这里使用 withPixels 的方式,与之前在 validatePnm 函数中使用 withTransform 类似。注意 V.!? 的用法,它是 Vector 普通索引的安全变体,会返回 vector 类型的 Maybe:
ghci> import Data.Vector as V
ghci> vec = V.fromList [1..10] :: V.Vector Int
ghci> (V.!?) vec 0
Just 1
ghci> (V.!?) vec (-1)
Nothing
ghci> (V.!?) vec 10
Nothing
13.3.2 导出图像为 PNG(Exporting images as PNG)
现在已经可以处理 PNM 图像,还需要处理最后一步:把它们写回文件系统。可以再次把数据序列化为 PNM 格式,但我们想使用 JuicyPixels 包的能力,把图像数据写成 PNG 文件。要做到这一点,需要把 DynamicPnmImage 转换成该包的 DynamicImage 类型。
这个类型与我们的 DynamicPnmImage 非常相似,因为它也保存由内部像素类型区分的不同图像类型。不过,它既不是 GADT,也不是存在量化类型,而是一个简单 ADT,包含对应不同像素类型的不同构造器。这些构造器包括用于灰度图像的 ImageY8 和 ImageY16,以及用于彩色图像的 ImageRGB8 和 ImageRGB16。Codec.Picture 模块提供了 generateImage 函数,用于从函数构造图像;它的签名是 Pixel px => (Int -> Int -> px) -> Int -> Int -> Image px。它接收一个函数,用于返回给定坐标处的像素,同时接收图像宽度和高度。第一个参数的签名看起来与我们在图像映射中取回任意像素的函数签名很像,所以已经知道如何编写这个函数。图像宽度和高度也已知,剩下的就是区分图像类型,并据此构建正确图像。函数如下所示。
代码清单 13.17 把 PNM 图像转换为 JuicyPixels 图像值的函数
dynamicPnmToDynamicImage :: DynamicPnmImage -> P.DynamicImage
dynamicPnmToDynamicImage (DynamicPnmImage img) =
case img of
PnmGray8Bit {} -> P.ImageY8 $ pnmToImage img -- #1
PnmGray16Bit {} -> P.ImageY16 $ pnmToImage img -- #1
PnmColor8Bit {} -> P.ImageRGB8 $ pnmToImage img -- #1
PnmColor16Bit {} -> P.ImageRGB16 $ pnmToImage img -- #1
where -- #1
pnmToImage :: P.Pixel px => PnmImage px -> P.Image px
pnmToImage pnmImg =
P.generateImage build (pnmWidth pnmImg) (pnmHeight pnmImg) -- #2
where
build x y = -- #3
pnmPixels pnmImg V.! (y * (pnmWidth pnmImg) + x)
- #1 匹配
PnmImage构造器,并返回合适的图像 - #2 从
PnmImage像素数据构建图像 - #3 定义从坐标取回像素的函数
这里使用 Data.Vector 中的 (!) 运算符,因为可以确信索引会在 vector 长度内。否则,就是我们写程序时犯了错误。你可能会疑惑为什么在每个匹配分支中重复 pnmToImage img。不能写成这样吗?
dynamicPnmToDynamicImage (DynamicPnmImage img) =
let img' = pnmToImage img
in case img of
PnmGray8Bit {} -> P.ImageY8 img'
PnmGray16Bit {} -> P.ImageY16 img'
PnmColor8Bit {} -> P.ImageRGB8 img'
PnmColor16Bit {} -> P.ImageRGB16 img'
答案是不行!这是因为对 GADT 的 case 匹配很特殊。它们不仅会细化类型,而且这种类型细化只在 case 匹配表达式内部有效,不会在外部 let 绑定或 where 绑定中有效。我们正是利用这种细化来确定 pnmToImage 结果类型。
最后,现在可以编写一个动作,把图像数据作为 PNG 写入文件系统。为此,可以使用类型为 FilePath -> DynamicImage -> IO (Either String Bool) 的 writeDynamicPng。既然已经有函数把 DynamicPnmImage 转换为 DynamicImage,就可以简单组合这两个函数。如下所示。
代码清单 13.18 把动态 PNM 图像保存为 PNG 的动作
writeAsPng ::
FilePath ->
DynamicPnmImage ->
IO (Either String Bool)
writeAsPng path img =
P.writeDynamicPng path $
dynamicPnmToDynamicImage img
如果无法转换或保存,writeDynamicPng 会把错误编码为 Either 返回。这样,Graphics.PNM.Conversion 模块就完成了。可以把新函数添加到 Graphics.PNM 模块中,该模块会重新导出内部模块中的数据类型和函数。
代码清单 13.19 重新导出内部模块定义的模块
module Graphics.PNM
( module PNMC, -- #1
module PNMP, -- #1
module PNMT, -- #1
module PNMV, -- #1
)
where
import Graphics.PNM.Conversion as PNMC -- #2
import Graphics.PNM.Parsing as PNMP -- #2
import Graphics.PNM.Types as PNMT -- #2
import Graphics.PNM.Validation as PNMV -- #2
- #1 导出已导入模块的定义
- #2 使用别名导入模块
现在可以进入有趣部分,开始为库编写映射函数了,因为到目前为止只是构建了工具。现在是使用它们的时候了。
13.4 使用并行处理转换数据(Using parallelism to transform data)
来为图像处理库编写不同映射,玩一点有趣的东西。我们会在图 13.2 所示的图像上测试它们。本书代码仓库提供了这张图供你尝试。

图 13.2 用于处理的图像
先写一个非常简单的映射:通过求红、绿、蓝通道之和并归一化结果,把彩色图像变成灰度图像。这个映射如下所示,它忽略了 PixelMapping 大部分能力。
代码清单 13.20 灰度映射
module Main where
import Graphics.PNM
grayScale :: PixelMapping
grayScale _ _ _ (r, g, b) = (v, v, v) -- #1
where
v = (r + g + b) / 3 -- #2
- #1 返回灰度像素
- #2 相加颜色通道并归一化该值
现在来点更有趣的:一个像素化图像的映射。像素化时,我们想增大某些像素的尺寸,并覆盖其他像素。由于 PixelMapping 知道当前位置,它可以检查自己正被调用在哪个放大的像素上,然后取回那个像素。但如何确定放大的像素?可以用固定常数对坐标求除法余数。借助这一点,可以取回当前坐标负偏移位置处的像素,如下所示。
代码清单 13.21 像素化映射
import Data.Maybe
...
pixelate :: Int -> PixelMapping
pixelate pixelSize x y getPx curPx =
let xDiff = x `mod` pixelSize -- #1
yDiff = y `mod` pixelSize -- #1
in fromMaybe curPx $ getPx (x - xDiff) (y - yDiff) -- #2
- #1 计算当前像素与要放大的像素之间的差值
- #2 取回要放大的像素,并默认回退到当前像素
代码清单 13.21 中的映射允许指定像素大小,该大小决定被放大像素的尺寸。用不同像素大小把这个映射应用到原始图像上,会得到图 13.3 所示图像。

图 13.3 使用 pixelate 16 和 pixelate 64 进行像素化的图像
本章介绍的最后一个映射是模糊效果。模糊图像有很多方式,这里看看最直接的实现:box blur。之所以叫 box blur,是因为模糊是通过在应被模糊的像素周围绘制一个预定义大小的方框,并计算该方框内所有像素的平均像素来实现的。在 PixelMapping 中,可以通过枚举该方框内的像素,并计算每个颜色通道的平均值来完成。这个映射如下所示。
代码清单 13.22 Box blur 映射
boxBlur :: Int -> PixelMapping
boxBlur boxSize x y getPx _ =
let nbrs =
catMaybes -- #1
[ getPx (x + dx) (y + dy) -- #2
| dx <- [(-boxSize) .. boxSize], -- #2
dy <- [(-boxSize) .. boxSize] -- #2
]
(rx, gx, bx) = unzip3 nbrs -- #3
numPixs = fromIntegral $ length nbrs -- #4
in ( sum rx / numPixs, -- #5
sum gx / numPixs, -- #5
sum bx / numPixs -- #5
)
- #1 丢弃因为坐标位于图像尺寸之外而无法取回的像素
- #2 枚举当前坐标周围方框内的像素
- #3 把
(Double, Double, Double)列表拆成三个列表,分别对应不同颜色通道 - #4 统计能从图像中取回的像素数量
- #5 通过对颜色通道取平均值,计算平均像素
应用这个映射会创建图 13.4 所示的图像。在前面的定义中,我们使用了 unzip3,它是 unzip 的一个版本,作用于包含三个元素的元组列表,并返回三个列表,分别包含元组第一、第二和第三位置的元素。

图 13.4 由 boxBlur 8 模糊后的图像
运行这个映射所花费的时间值得注意,因为它比其他映射明显更久。因此,本章剩余部分会使用并行来加速它。
13.4.1 时间测量(Measuring time)
测试时使用下面的 main 模块。为了让代码更简单,程序期望只给出一个参数,如果验证或解析期间发生任何错误,就会崩溃。我们把程序硬编码为执行 box blur。
代码清单 13.23 用于测试的示例 main 模块
module Main (main) where
...
import Graphics.PNM
import System.Environment (getArgs)
main :: IO ()
main = do
[filePath] <- getArgs
Right rawImg <- readPnmFile filePath
let Right pnmImg = validatePnm rawImg
pnmImg' = mapImagePixels (boxBlur 8) pnmImg
_ <- writeAsPng "test.png" pnmImg'
return ()
在本书代码仓库中的示例图像 large/p6.ppm 上运行这个程序,在 2021 款 MacBook Pro 上大约需要 33 秒。可以通过添加运行时选项 -s 检查这一点,运行方式如下:stack run -- <path to the pnm image> +RTS -s。输出会包含程序运行耗时信息:
INIT time 0.000s ( 0.004s elapsed)
MUT time 23.866s ( 28.727s elapsed)
GC time 2.794s ( 4.578s elapsed)
EXIT time 0.002s ( 0.009s elapsed)
Total time 26.662s ( 33.318s elapsed)
这……有点令人失望。能不能加速?如果能,该如何加速?先回顾一下程序执行的步骤:
验证和写出图像并不昂贵,不值得改进设计。解析可能花一些时间,但它也不是罪魁祸首,这可以通过在 main 模块中把 boxBlur 换成 pixelate 快速检查。现在程序不到 2 秒就能运行完!显然,昂贵的部分是映射。
退一步分析一下 PixelMapping 是什么。核心上,它不过是一个简单纯函数,这从第 2 章开始就一直在处理。这个纯函数被应用到图像中的每个像素上,这意味着对一张 1000 x 1000 像素的图像执行映射,会产生 100 万次计算。由于纯函数不会产生副作用,它们以什么顺序求值基本无关紧要。此外,像素映射中的单次计算互不干扰。那么为什么不并行运行这些计算?
13.4.2 并行原理(How parallelism works)
当编译 Haskell 程序时,生成的二进制文件不只包含我们的代码,还包含一个庞大的运行时系统。这个系统不仅包含垃圾收集器,也包含用于绿色线程(有时称为虚拟线程)的调度器。它们不是在处理器上运行的真实线程,而是程序运行时系统内部的轻量进程。这有许多优点:
像 Haskell 这样的语言几乎所有与副作用有关的东西都受管理,因此它为安全多线程提供抽象是很合理的。对于并发,有几个包提供了异步执行计算的方式:
虽然这些可能性很有意思,但并不完全适用于我们,因为我们不需要并发,而是需要并行。区别在于,我们想并行运行的计算在每次调用中都是相同的。对于这种多线程模型,可以使用 parallel 包。
这个包提供了 Control.Parallel.Strategies 模块,它让我们可以简单表达并行执行。该模块的核心概念是 Strategy 类型,它定义某个东西应该如何被求值。Strategy 是一个类型同义词,表示类型为 a -> Eval a 的函数。Eval 是一个 monad,指定某些计算应如何执行,说明哪些计算应并行求值,哪些计算应强制顺序执行。
为了定义求值顺序,有一些预置策略可用:
rseq 和 rdeepseq 有什么区别?它们不都是求值参数吗?区别在于,Haskell 中的求值并不意味着完全求值,而是求值到所谓的弱头范式。这里不会深入这个主题,简单来说,如果一个表达式至少已经求值到第一个数据构造器,就算求值到了弱头范式。这意味着,如果列表已经求值到第一个 (:) 或 [] 构造器,那么它处于弱头范式。不过,列表中的值不必被求值!这得益于一个叫 thunk 的概念,即尚未求值的数据片段。这些 thunk 只会在需要时求值。这就是 Haskell 惰性的来源。
与 rseq 相比,rdeepseq 会强制求值到范式,也就是说数据必须被完全求值。不过,对我们的用例来说最重要的策略是 rpar,因为它会触发并行求值。
13.4.3 Sparks 图像处理 HECs(Haskell execution contexts)
Spark 是一个类似 thunk 的概念。thunk 构成尚未求值的数据,而 spark 指向这些 thunk。求值一个 spark 意味着求值一个 thunk。不过,区别在于 spark 可以并行求值。为此,运行时系统使用所谓的 Haskell execution context(HEC)。粗略来说,每个执行上下文生活在自己的操作系统线程中,并由运行时系统管理。
HEC 能够求值 spark。为此,它们可以访问 spark pool,这个池由 rpar 填充 spark。并行执行的调度通过工作窃取完成,也就是说,任何能够接手新 spark 的 HEC 都会简单地从 spark pool 中“偷走”它并求值。图 13.5 展示了这个想法。
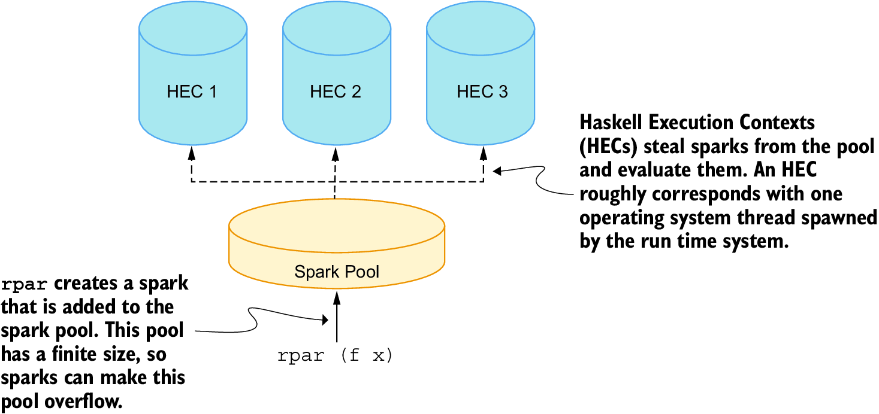
图 13.5 Haskell 执行上下文和 spark pool
当然,故事稍微更复杂,因为 spark 可能在 HEC 接触它们之前被提前求值或被垃圾收集。不过,这些杂乱细节幸运地由运行时系统负责处理。
有了这些知识,让我们编写第一次并行求值。为此,需要把 parallel 包加入 package.yaml 文件的依赖。求值由 Eval monad 控制,并用 runEval 启动以从该 monad 中取回值。看一个例子:
runEval $ do
x' <- rpar x
return x'
这个调用会触发 x 的并行计算,把它放入 spark pool。不过,return 不会等待求值完成。这意味着,如果结果值由调用 runEval 的代码求值,spark 就会失效。我们称这个 spark fizzled。如果 x 在 rpar 求值之前已经被求值,则认为它是一个 dud。能否在 return 之前以某种方式强制求值?
runEval $ do
x' <- rpar x
rseq x'
return x'
在这个版本中,我们先创建 spark,然后在调用 return 之前强制顺序求值。不过,这没有意义,因为我们的目标本来就是执行并行求值。把求值扩展到整个列表。Control.Parallel.Strategies 模块提供了一些辅助函数来完成这件事。
其中一个辅助函数是 evalList,类型为 Strategy a -> Strategy [a]。可以传入一个用于列表单个元素的策略,产生一个随后可用于列表的新策略。调用可能类似这样:
map (^ 100) [1 .. 1000] `using` evalList rpar
这里,映射计算会并行执行。using 是该模块中的函数,用于使用指定策略求值数据结构。也可以用 withStrategy 函数写出这个表达式,它只是写下求值的另一种方式:
withStrategy (evalList rpar) $ map (^ 100) [1 .. 1000]
并行求值类列表结构很有意义,尤其是在对它们执行非常昂贵的映射时。这对我们很重要,因为这正是 PixelMapping 的情况!不过,我们没有像素列表可供映射,而是有一个 Vector,那么该如何指定合适策略?该模块提供 evalTraversable 函数,它定义了一种把策略应用到 Traversable 中每个元素的方式,这可以从其类型 Traversable t => Strategy a -> Strategy (t a) 中看出。幸运的是,Traversable Vector 实例存在!
让我们用它完全并行求值 PixelMapping!为此,只需要在 mapImagePixels 中的 mapping 辅助函数里添加一行代码。如下所示。
代码清单 13.24 有缺陷的并行映射策略
import Control.Parallel.Strategies as S
...
mapping :: GenericPixel px => V.Vector px -> V.Vector px
mapping pixels =
S.withStrategy (S.evalTraversable S.rpar) $ -- #1
flip V.imap pixels $ \i px ->
let x = i `mod` w
y = i `div` w
getPixel x' y' =
toGenericRGB <$> pixels V.!? (y' * w + x')
result = f x y getPixel $ toGenericRGB px
in fromGenericRGB result
- #1 完全并行求值像素 vector
现在可以重新运行程序。使用以下运行时选项运行它:+RTS -N8 -s -RTS。-N8 告诉运行时系统使用 8 个处理器进行求值,这对应 8 个会被使用的 HEC。使用 -s 时,还会收到关于 spark 如何求值的统计信息。
注意 我们能并行运行程序,是因为程序使用
-threaded选项编译,而stack默认会把这个选项添加到构建配置中。
使用这些选项运行程序时,会在输出中收到如下统计信息:
SPARKS: 1318768 (10163 converted, 1210301 overflowed, 0 dud, 0 GC'd, 0 fizzled)
INIT time 0.000s ( 0.003s elapsed)
MUT time 23.793s ( 27.440s elapsed)
GC time 2.758s ( 3.972s elapsed)
EXIT time 0.000s ( 0.011s elapsed)
Total time 26.552s ( 31.427s elapsed)
事实证明,程序性能只略微提升。结果并不值得!但等等,SPARKS 统计信息到底告诉了我们什么?可以看到,总共创建了 1,318,768 个 spark。输入程序的图像是 1397 x 944 像素,这正好是每个像素一个 spark,所以映射似乎确实在工作。其中 10,163 个 spark 被 converted,意思是某个 HEC 从池中拿走并求值了它们。另外,没有 spark fizzled、被垃圾收集,或被归类为 dud,所以这意味着映射没有产生不必要的 spark。如果一个 spark 的求值在 HEC 来得及处理之前就发现不再需要,那么它会被垃圾收集(GC'd)。最惊人的数字是 1,210,301 个 spark overflowed。这是什么意思?
答案很简单:spark pool 有固定大小。如果短时间内创建太多 spark,池可能完全填满并最终溢出。这种情况下,spark 会直接被丢弃,不会发生并行求值。这就是我们搞砸的地方!程序实际上并没有并行计算映射。
那么如何避免填满 spark pool?当然,需要创建更少的 spark,但仍然想并行执行求值。需要让每个单独 spark 做更多工作。可以通过把工作拆分成更大的 chunk,然后把这些 chunk 作为 spark 求值来做到这一点。
Control.Parallel.Strategies 模块提供 parListChunk 函数,它为列表定义一个策略,作用于指定大小的 chunk。不过,这个函数只作用于列表。要应用这个策略,必须把 Vector 转换为列表,执行并行计算,再把列表转换回 Vector。把这个函数写入新的 Data.Vector.Strategies 模块,如下完整清单所示。
代码清单 13.25 用于 Vector 类型分块并行执行的模块
module Data.Vector.Strategies (parVectorChunk) where
import Control.Parallel.Strategies -- #1
import qualified Data.Vector as V -- #1
parVectorChunk :: Int -> Strategy (V.Vector a)
parVectorChunk size =
fmap V.fromList . parListChunk size rseq . V.toList -- #2
- #1 导入所需模块
- #2 定义一种策略,以给定大小的 chunk 并行求值 vector
为什么使用 rseq 策略?因为 parListChunk 已经会并行求值。使用 rpar 会导致策略触发 spark 的 spark,这是无用工作!
现在,可以在 mapping 函数中使用 parVectorChunk。但如何决定使用多少 chunk?遗憾的是,这不是精确科学,因为 spark 并不是没有成本。管理和垃圾收集意味着创建更多 spark(即使它们没有让池溢出)并不一定更快,反而可能更慢。这也强烈依赖单个 spark 能完成多少工作。最终,程序员必须调整这些参数,并通过基准测试验证性能收益。
就我们的目的而言,创建大约 1000 个 spark。可以通过根据图像中的像素总量计算 chunk 应该多大来做到。
代码清单 13.26 用于映射图像像素的并行化映射函数
import Control.Parallel.Strategies as S -- #1
import qualified Data.Vector as V -- #2
import qualified Data.Vector.Strategies as V -- #2
...
mapping :: GenericPixel px => V.Vector px -> V.Vector px
mapping pixels =
S.withStrategy (V.parVectorChunk ((w * h) `div` 1000)) $ -- #3
flip V.imap pixels $ \i px ->
let x = i `mod` w
y = i `div` w
getPixel x' y' =
toGenericRGB <$> pixels V.!? (y' * w + x')
result = f x y getPixel $ toGenericRGB px
in fromGenericRGB result
- #1 导入并行策略模块
- #2 在同一命名空间中导入
Data.Vector和Data.Vector.Strategies - #3 把图像数据切分成约 1000 个 chunk,并并行求值它们
完成这个修改后,可以用前面介绍的 box blur 测试映射。运行后查看统计信息,会看到美妙的结果:
SPARKS: 1001 (1001 converted, 0 overflowed, 0 dud, 0 GC'd, 0 fizzled)
INIT time 0.000s ( 0.004s elapsed)
MUT time 27.682s ( 5.502s elapsed)
GC time 3.085s ( 2.180s elapsed)
EXIT time 0.000s ( 0.000s elapsed)
Total time 30.767s ( 7.686s elapsed)
不仅不再有任何溢出的 spark,我们还只改了一行代码,就把执行时间从 33 秒砍到了约 8 秒!
这就完成了并行图像处理库的构建。我们成功为 PNM 文件构建了验证逻辑,并为数据使用类型安全的动态编码。我们也创建了一种通用方法,用于映射图像中的像素,从而创建不同滤镜和效果。最后,我们借助 Haskell 对并行的内置支持,显著提升了通用算法的性能。
总结
- 泛化代数数据类型用于把多态类型细化为具体类型,方式是为本来多态的类型变量定义构造器的具体类型。
Vector是一种类似列表的高层类型,但拥有类似数组的性能特征:访问速度很快,但动态分配较慢。它适合高效存储需要频繁读取的数据。- 存在量化类型与 GADT 结合使用,可以绕开返回类型多态,同时仍然使用参数多态类型。这让我们可以在被调用函数内部决定结果类型,而不是让调用者决定。
- 均匀应用到一组数据上的纯函数,可以使用
Control.Parallel.Strategies模块中的求值策略轻松并行化。 - Haskell 内置支持并行执行,使用 spark 来实现。spark 可以通过
Evalmonad 和rpar创建,也可以通过任意预置并行策略创建。这让我们无需修改算法,就能把确定性并行透明地引入程序。 - 创建过多 spark 会导致 spark pool 溢出,并让并行无效。解决方式是先把工作拆分成更大的 chunk,然后并行求值这些 chunk。