第 8 章 - CSV 工具(A tool for CSV)
本章内容包括:
- 从文本中解析数值
- 定义并使用数据结构上的折叠
- 使用
Functor类型类及其功能处理错误 - 创建一个简单的命令行解析接口
在上一章中,我们开始为一个能够处理 CSV 文件的应用程序搭建骨架。本章将完成这个项目,并为解析和打印我们的 Csv 数据类型提供功能。
本章会从上一章停下的地方继续,展示一些非常重要的概念,例如 Functor 类型类和折叠(folding),帮助你熟悉核心函数式编程概念。最后,我们会把这些新学到的技能组合到一个小程序中,真正使用我们的库。最终,我们还会把创建出的二进制程序安装到本地计算机上。
8.1 数据解析(Parsing data)
接下来,我们希望让程序能够读取并解析 CSV 文件。为此,需要编写一些函数,用于读取文件内容、解析分隔符和字段,并把它们写入数据结构。
解析 CSV 文件是一个困难话题,因为看起来每个应用程序都会以不同方式处理这些文件,尤其是在分隔符和换行符的选择上。CSV 文件的表头也是可选的,但没有可靠方式能判断某个 CSV 文件是否带表头。因此,我们应该为解析提供选项。可以用类型对这些选项建模,如下所示。
代码清单 8.1 CSV 文件解析选项
data Separators = Separators -- #1
{ sepLineSeparator :: Char,
sepFieldSeparator :: Char
}
deriving (Eq, Show)
data HeaderOption = WithHeader | WithoutHeader -- #2
deriving (Eq, Show)
data CsvParseOptions = CsvParseOptions -- #3
{ cpoSeparators :: Separators,
cpoHeaderOption :: HeaderOption
}
deriving (Eq, Show)
defaultSeparators :: Separators
defaultSeparators =
Separators -- #4
{ sepLineSeparator = '\n',
sepFieldSeparator = ','
}
defaultOptions :: CsvParseOptions
defaultOptions =
CsvParseOptions -- #5
{ cpoSeparators = defaultSeparators,
cpoHeaderOption = WithoutHeader
}
- #1 定义行分隔符和字段分隔符
- #2 定义是否存在表头
- #3 定义完整的 CSV 解析选项
- #4 默认使用换行符分隔行、逗号分隔字段
- #5 默认假设文件没有表头
这些选项可以放在新的 Csv.Parsing 模块中,并且同样可以在 Csv 模块中重新导出。稍后,我们可以通过命令行设置这些选项。作为合理默认值,我们假设文件不包含表头,并且字段由逗号分隔。
在思考解析规则时,需要对 CSV 文件的处理方式做出一些假设。正如开头所说,我们认为 CSV 文件:
- 每行包含一条记录,并由换行符分隔
- 在整个文件中使用相同分隔符划分记录字段
- 每条记录拥有相同数量的字段
- 可能包含一个可选表头行
此外,我们会跳过空行,并且不认为空行是格式错误。不过,我们会完全忽略带引号字段以及引号字段中可能出现的转义双引号,因为这会让当前学习任务变得过于复杂。
即便如此,我们仍希望解析器在失败时给出一定描述。也就是说,当两行包含不同数量字段时,解析器应该能说明问题。虽然智能构造器已经能做到这一点,但我们还希望得到发生解析失败的行号。
为此,需要先把文本拆分成单独的行,再把这些行拆分成字段,并检查字段数量是否匹配。幸运的是,Data.Text 已经提供了拆分函数:split 根据布尔谓词拆分 Text,splitOn 根据特定子串拆分:
ghci> import qualified Data.Text as T
ghci> :t T.split
T.split :: (Char -> Bool) -> T.Text -> [T.Text]
ghci> :t T.splitOn
T.splitOn :: T.Text -> T.Text -> [T.Text]
ghci> T.split (== '\n') "a\nb\nc"
["a","b","c"]
ghci> T.splitOn "\n" "a\nb\nc"
["a","b","c"]
因此,把 Text 拆成行,再把这些行拆成字段,都可以通过 splitOn 和 CsvParseOptions 中的分隔符完成。接下来,我们应该处理如何把任意文本解析成有意义的数据。
8.1.1 数值解析(Parsing numeric values)
解析时,我们唯一处理的类型是 Text。最终,我们希望把 CSV 表中解析出的 Text 转换为更适合处理的值,例如明确的数值和文本值,也就是转换为 DataField 值。因此,我们希望能够把 Text 转换成这个类型。
对于 Int 转换,可以使用 Text.Read 模块中的 readMaybe。这个函数可以把拥有 Read 类型类实例的值从 String 解析为对应值,如果转换失败则返回 Nothing:
ghci> import Text.Read
ghci> :t readMaybe
readMaybe :: Read a => String -> Maybe a
ghci> readMaybe "100" :: Maybe Int
Just 100
ghci> readMaybe "abc" :: Maybe Int
Nothing
可以用它编写一个函数,把 Text 转换为 DataField 值。此外,我们还提供一个函数,把 DataField 转回 Text。代码如下。
代码清单 8.2 DataField 与 Text 之间的转换函数
textToDataField :: T.Text -> DataField
textToDataField "" = NullValue -- #1
textToDataField raw =
let mIntVal = readMaybe (T.unpack raw) -- #2
in maybe (TextValue raw) IntValue mIntVal -- #3
dataFieldToText :: DataField -> T.Text
dataFieldToText (IntValue i) = T.pack $ show i -- #4
dataFieldToText (TextValue t) = t -- #5
dataFieldToText NullValue = "" -- #6
- #1 空文本被解析为空值
- #2 尝试把文本解析为整数
- #3 解析成功则生成
IntValue,失败则保留为TextValue - #4 将整数值转换回文本
- #5 文本值直接返回
- #6 空值转换为空文本
请注意,类型推断能够判断出多态的 readMaybe 需要返回 Maybe Int。这是因为我们把成功解析出的值传给了 IntValue。
8.2 数据结构折叠(Folding data structures)
为了验证解析后的文件内容,必须检查每一行是否拥有相同数量的字段。我们先处理单行长度检查。在把文件拆分成行之后,会得到一个需要检查的行列表。当然,我们已经知道如何用递归和模式匹配解决这个问题,但不妨后退一步。我们之前已经无数次遇到类似问题:遍历一个类似列表的数据结构,并从中计算某个结果。策略通常如下:
- 递归枚举数据结构中的每个元素。
- 在累加器参数中保存某些状态。
- 在每一步中,根据当前元素和上一步的累加器计算新的累加器。
- 当数据结构为空时,也就是到达最终递归步骤时,直接返回累加器。
这是一种强大的策略。事实上,它在函数式编程中几乎无处不在,因为它本质上替代了循环的需要。这个概念被称为折叠(folding)。在深入折叠能做什么之前,先用一个更轻松的例子解释它。
8.2.1 折叠概念(The concept of folding)
想象你面前有一条小路。路上散落着不同口味的硬糖,当然糖还包在包装纸里。如何建模这种情况?也许可以用列表:
data Candy
= Lemon
| Apple
| Coffee
| Caramel
deriving (Eq, Show)
type CandyTrail = [Candy]
现在,想象你沿着这条路往前走,每遇到一颗硬糖,就要决定怎么处理它。把糖捡起来意味着你手里拿着它们;下一次遇到糖时,可以根据手里已有的糖和新发现的糖决定下一步。显然,一开始你的手是空的;走到小路尽头时,只剩下手里的东西。可以这样表示:
walkOnTrail :: (a -> Candy -> a) -> a -> CandyTrail -> a
walkOnTrail _ hand [] = hand
walkOnTrail f hand (x : xs) = walkOnTrail f (f hand x) xs
借助这个高阶函数,现在可以执行若干动作。例如,只收集水果味糖,或者只收集最后五颗糖,因为手掌只能装这么多:
isFruity :: Candy -> Bool
isFruity c = c == Lemon || c == Apple
collectFruits :: CandyTrail -> [Candy]
collectFruits =
walkOnTrail
( \hand c ->
if isFruity c
then hand ++ [c]
else hand
)
[]
collectLastFive :: CandyTrail -> [Candy]
collectLastFive =
walkOnTrail
( \hand c ->
if length hand == 5
then tail hand ++ [c]
else hand ++ [c]
)
[]
现在,把糖果小路看成普通列表,或者更一般地说,看成任何能像列表一样遍历的数据结构。泛化 walkOnTrail 后,就得到了左折叠的定义。下面是列表上的左折叠。
代码清单 8.3 列表上的左折叠函数
foldLeft :: (b -> a -> b) -> b -> [a] -> b
foldLeft _ z [] = z -- #1
foldLeft f z (x : xs) = foldLeft f (f z x) xs -- #2
- #1 空列表返回累加器
- #2 将当前元素合并进累加器,然后继续处理剩余元素
它被称为左折叠,因为元素从左到右被归约。另一种选择是右折叠:先遍历列表,再应用函数。如下所示。
代码清单 8.4 列表上的右折叠函数
foldRight :: (a -> b -> b) -> b -> [a] -> b
foldRight _ z [] = z -- #1
foldRight f z (x : xs) = f x $ foldRight f z xs -- #2
- #1 空列表返回累加器
- #2 先折叠尾部,再把当前元素与尾部结果组合
折叠是如此通用的概念,以至于它拥有自己的类型类:Foldable。该类提供名为 foldr 的右折叠,以及许多便利函数,例如 null、length、elem、sum、maximum 和 minimum。最小定义只要求实现 foldr,因为其他函数都可以仅从 foldr 推导出来。
练习:Foldable 的力量
再次查看 Foldable 类型类。首先尝试只用 foldr 实现其中的便利函数,可以先只为列表实现。完成之后,看看下面这个简单二叉树类型,并为它实现 Foldable 实例。对于树来说,左折叠和右折叠分别意味着什么?
data Tree a = Leaf a | Node (Tree a) a (Tree a)
谈论列表和其他线性结构时,折叠最容易想象,因为元素按某种顺序排列,可以从左到右或从右到左归约。Data.List 和 Data.Text 分别为列表和 Text 提供了 foldl 与 foldr 实现。不过,折叠也可以定义在许多其他数据结构上。
注意 折叠也存在于其他非函数式编程语言中,例如 Python 和 Java 中的
reduce,以及 C++ 中的accumulate。
虽然“左折叠”和“右折叠”这两个术语似乎暗示元素会从左到右或从右到左求值,但事实并非如此。这两个折叠函数都会从左到右求值。区别在于,foldl 从左侧结合累加函数,而 foldr 从右侧结合。对数据结构执行折叠时,本质上是在用某个函数和结构中的元素构建一个表达式。由于 Haskell 是惰性的,这个表达式在未被强制求值之前不会真正求值。可以想象表达式如下:
ghci> foldl (\a d -> "(" <> a <> "+" <> show d <> ")") "0" [1..9 :: Int]
"(((((((((0+1)+2)+3)+4)+5)+6)+7)+8)+9)"
ghci> foldr (\d a -> "(" <> show d <> "+" <> a <> ")") "0" [1..9 :: Int]
"(1+(2+(3+(4+(5+(6+(7+(8+(9+0)))))))))"
这里可以看到 foldl 的左结合性和 foldr 的右结合性。使用折叠时,我们实质上从数据结构构建出一个新表达式。图 8.1 展示了这个过程。
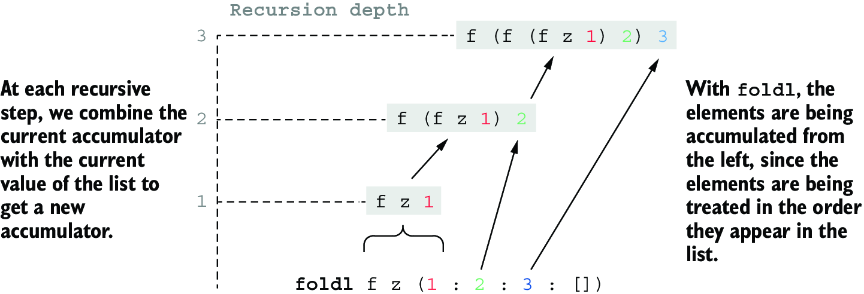
图 8.1 从 fold 构建表达式的例子
Haskell 的惰性可能产生一些意外后果,附录 B 会讨论这些内容。简而言之,它可能导致灾难性的内存低效。为了抵消惰性带来的影响,有时会提供严格版本的折叠。在 Data.List 和 Data.Text 模块中,它们叫作 foldl'。
注意 一般规则是:如果累加函数是惰性的,更具体地说,不严格依赖第二个参数,应使用
foldr;否则通常更偏好foldl'。
此外,有些情况下我们不想为折叠提供累加器的“起始值”,而是使用数据结构的第一个元素。对于这种折叠变体,许多模块会提供以 1 结尾的函数,例如 foldl1,表示要处理的数据结构至少必须有一个元素。
警告 像
foldl1这样的函数是部分函数,如果参数没有至少一个元素,就会抛出异常。
回顾之前项目中的实现,会发现我们本来可以在很多函数中使用折叠。第 5 章甚至有一个练习,要求泛化 addEdges 和 buildDiGraph 中的递归模式。该练习的解法就是实现一种折叠,把针对单个元素的动作应用到元素列表上。
8.2.2 解析结构(A structure for parsing)
现在我们知道了什么是折叠以及如何使用折叠,就可以用它验证 CSV 文件中的行。为此,必须按顺序遍历各行,将它们拆分成字段,并验证长度,同时跟踪当前所在的行号。当然,对任何读过第 3 章的人来说,给一组行添加行号都是小事。使用 zip 给列表加编号,再用 filter 去掉空行即可。
解析函数命名为 parseCsv。它接收 CsvParseOptions 类型的选项和 Text 类型的原始文件内容,并返回 Csv 或错误消息。这个结果可以用 Either 编码。
为了检查字段数量是否正确,我们查看第一行,之后验证所有其他行是否拥有相同数量的字段。执行解析的函数如下。
代码清单 8.5 CSV 解析函数
parseCsv ::
CsvParseOptions ->
T.Text ->
Either String Csv
parseCsv options raw = case lines of
[] -> mkCsv Nothing [] -- #1
((_, firstLine) : rest) ->
let expectedLength = length $ splitFields firstLine -- #2
in case cpoHeaderOption options of
WithHeader ->
let headerFields = splitFields firstLine
in unsafeMkCsv (Just headerFields) -- #3
<$> parseColumns expectedLength rest
WithoutHeader ->
unsafeMkCsv Nothing <$>
parseColumns expectedLength lines -- #4
where
lines :: [(Int, T.Text)]
lines =
L.filter (\(_, t) -> not $ T.null t) $ -- #5
L.zip [1 ..] $ -- #6
T.split -- #7
(== (sepLineSeparator $ cpoSeparators options))
raw
splitFields :: T.Text -> [T.Text]
splitFields = L.map T.strip . T.splitOn separator
where
separator :: T.Text
separator =
T.singleton $
sepFieldSeparator (cpoSeparators options)
parseColumns ::
Int ->
[(Int, T.Text)] ->
Either String [[DataField]]
... -- #8
- #1 空输入会尝试构造没有表头、没有列的 CSV
- #2 第一行决定预期字段数量
- #3 带表头时,第一行被作为表头,剩余行作为数据
- #4 不带表头时,所有行都是数据
- #5 过滤空行
- #6 为每一行添加行号
- #7 根据行分隔符拆分原始文本
- #8 后续实现会解析并验证所有列
这个函数中使用了 <$> 运算符,它是 fmap 函数的运算符形式,用于把 parseColumns 中的 Left 传递到我们自己的返回值中。为了更好理解这个运算符和 fmap 的作用,需要看看 Functor 类型类。
8.2.3 Functor 类型类(The Functor type class)
fmap 来自哪里?这个名字看起来有点奇怪。GHCi 可以告诉我们一些信息:
ghci> :t fmap
fmap :: Functor f => (a -> b) -> f a -> f b
ghci> :i fmap
type Functor :: (* -> *) -> Constraint
class Functor f where
fmap :: (a -> b) -> f a -> f b
fmap 函数来自名为 Functor 的类型类。它的类型与列表的 map 类型非常相似:
ghci> :t map
map :: (a -> b) -> [a] -> [b]
ghci> :t fmap
fmap :: Functor f => (a -> b) -> f a -> f b
那么 Functor 的目的是什么?它允许我们定义可以被映射的类型。大多数情况下,这些类型是包含可映射值的容器。更具体地说,这些类型包含可以被映射的自由类型变量。
我们还没有在类型表达式中见过类似 f a 的形式,其中 f 是 functor 类型,a 是它的类型变量。什么类型可以替换 f?例如 Maybe 可以,因为它包含一个自由类型变量。列表也是候选者。这两个类型都有 Functor 类型类实例。我们已经见过 Maybe 上的 fmap,它没有什么特别之处;列表上的 fmap 更无聊,它就是 map。
不过,回到带类型变量的类型这个话题。并非每个类型都有这种性质,例如 Int 没有。这意味着我们不能为 Int 实例化 Functor。GHCi 的输出也能说明这一点:
ghci> :i fmap
type Functor :: (* -> *) -> Constraint
这里看到的是 Functor 类型的 kind。kind 之于类型,就像类型之于值。常见 kind 很容易读:
*(读作 type)表示单态类型,例如Int、Maybe String或Maybe [Bool]。* -> *表示接收一个类型参数的类型。类似地,接收两个参数的类型写作* -> * -> *,也可以读作* -> (* -> *)。Constraint是用于约束的类型,例如类型类约束中的内容。
现在可以理解 (* -> *) -> Constraint 了。它表示一种类型:接收另一个带一个类型参数的类型,并生成一个约束。用 GHCi 的 :kind(可缩写为 :k)命令探索一下:
ghci> :kind Int
Int :: *
ghci> :kind []
[] :: * -> *
ghci> :kind [Int]
[Int] :: *
ghci> :kind Functor []
Functor [] :: Constraint
这也是一个重要区别:Int 是类型,而 [] 是参数化类型。反过来,Functor [] 不是类型,而是约束,因此不能用它定义新数据类型:
ghci> newtype MyFun = MyFun (Functor [])
<interactive>...: error:
• Expected a type, but 'Functor []' has kind 'Constraint'
• In the type '(Functor [])'
In the definition of data constructor 'MyFun'
In the newtype declaration for 'MyFun'
思考哪些类型可以实例化时,观察 Functor 的 kind * -> * 至关重要。我们只能用这种 kind 的类型实例化它。这与 Semigroup、Monoid 和我们自己的 Sliceable 不同,它们的 kind 是 * -> Constraint。
8.2.4 使用折叠解析(Using folding for parsing)
现在可以处理 parseColumns 了。这个函数会把行拆分成字段,并验证每行字段数量。此外,我们希望把解析后的行转换成可用于 Csv 的列。正如前面讨论过的,折叠可能是这个函数的正确解法。折叠按顺序遍历每一行,将它转换为字段并验证预期长度,成功时返回 Right,失败时返回带有合适错误消息的 Left。
在折叠中,如果之前已经发现错误,就要返回该错误;否则继续累积解析出的行。把行转换成列可以通过“旋转”结果完成。行列表变成列列表,就是翻转组成该列表的两个维度。Data.List 模块中的 transpose 函数可以完成这个操作:
ghci> import Data.List (transpose)
ghci> transpose [[1,2,3], [4,5,6]] :: [[Int]]
[[1,4],[2,5],[3,6]]
同样,可以使用 fmap 向外传播错误状态。代码如下。
代码清单 8.6 将文本行解析为 CSV 表列的函数
parseColumns ::
Int ->
[(Int, T.Text)] ->
Either String [[DataField]]
parseColumns expectedLength lines =
let textColumns =
L.transpose -- #1
<$> L.foldl' parseRow (Right []) lines -- #2
in fmap (L.map (L.map textToDataField)) textColumns
where
parseRow ::
Either String [[T.Text]] ->
(Int, T.Text) ->
Either String [[T.Text]]
parseRow mRows (lNum, line) =
E.either -- #3
Left
( \rows ->
let fields = splitFields line -- #4
in if length fields /= expectedLength
then
Left $ -- #5
"Number of fields in line "
<> show lNum
<> " does not match"
<> " expected length of "
<> show expectedLength
<> "! Actual length is "
<> show (length fields)
<> "!"
else Right $ rows ++ [fields] -- #6
)
mRows
- #1 将行列表转置为列列表
- #2 严格左折叠逐行解析
- #3 如果之前已有错误,则继续返回错误
- #4 将当前行拆分成字段
- #5 字段数量不匹配时返回描述性错误
- #6 字段数量正确时把该行加入结果
把已经构建的功能组合起来,就得到了 parseCsv 函数,它可以从简单的 Text 中解析 Csv 值。为了方便,可以创建两个包装不同选项的函数:一个用默认选项解析,另一个用默认选项并启用可选表头。为此,需要更新之前创建的 defaultOptions。可以通过在记录标识符后的花括号中指定新值来做到这一点。代码如下。
代码清单 8.7 CSV 表解析辅助函数
parseWithHeader :: T.Text -> Either String Csv
parseWithHeader =
parseCsv (defaultOptions {cpoHeaderOption = WithHeader}) -- #1
parseWithoutHeader :: T.Text -> Either String Csv
parseWithoutHeader = parseCsv defaultOptions -- #2
- #1 用默认选项解析,但启用表头
- #2 用默认选项解析,不启用表头
现在,可以开始解析一些文件了。本章代码仓库中包含几个 CSV 文件,可用于测试这些新功能:
ghci> file <- readFile "cities.csv"
ghci> fileText = T.pack file
ghci> Right csv = parseWithHeader fileText
ghci> csvHeader csv
Just ["LatD","LatM","LatS","NS","LonD","LonM","LonS","EW","City","State"]
ghci> numberOfRows csv
128
我们已经走了很远,可以解析并验证文件了。但目前只能把文件中的值解释为 Text,这不足以支持更复杂任务。接下来,我们会把这些 Text 值映射成更适合处理的数据。
8.3 打印 CSV(Printing a CSV)
如果不能把 CSV 表输出到终端或文件,这个工具就不完整。为此,我们创建一个名为 Csv.Print 的模块,包含打印和写入所需的所有功能。首先,处理如何把 Csv 转换成 CSV 文件格式并写入文件系统。
我们希望先用 transpose 把 Csv 的列转换成行。之后,必须把 DataField 值转换为 Text,并使用 Data.Text 模块中的 intercalate 组合行内字段。intercalate 会用某个 Text 连接列表中每一对相邻元素。可以用它用逗号分隔字段,用换行符分隔行。接下来要处理的是如何把 Text 写入文件。Data.Text.IO 模块提供了直接处理 Text 的 readFile 和 writeFile 等函数。下面的代码提供了把 Csv 写入文件的函数,其中 Data.Text.IO 以 TIO 导入。
代码清单 8.8 将 CSV 值写入文件的函数
toFileContent :: Csv -> [T.Text]
toFileContent Csv {..} =
let rows = L.map (L.map dataFieldToText) $ L.transpose csvColumns -- #1
in L.map (T.intercalate ",") $ -- #2
M.maybe rows (: rows) csvHeader -- #3
writeCsv :: FilePath -> Csv -> IO ()
writeCsv path = TIO.writeFile path . T.intercalate "\n" . toFileContent -- #4
- #1 把列转成行,并把字段转换为文本
- #2 用逗号连接每一行的字段
- #3 如果存在表头,将其放到最前面
- #4 把行用换行符连接并写入文件
这个定义中又出现了一个新运算符:简单的点号 .。该运算符表示函数组合。简单来说,它接收两个函数作为参数,先应用第二个函数,再应用第一个函数。它的定义很简单:
ghci> (.) f g x = f (g x)
ghci> f = (+1) . (*3)
ghci> f 10
31
它让我们能够快速串联功能,同时仍然使用部分函数应用。这能保持定义简短。这个运算符甚至可以用于组合存储在数据结构中的函数:
ghci> f = foldl (flip (.)) id
ghci> f [(+1), (*100), (/50)] 1
4.0
函数组合有时不太容易一下子理解,因此稍微展开一下。在函数式编程中,函数是一等对象,所以可以把函数当作值处理:把它们传给其他函数,从其他函数返回它们,给它们命名,把它们放入数据结构,并从函数计算出新函数。我们在声明式编程时,本质上一直都在组合函数,因为我们不是像命令式语言那样定义一系列操作,而是在描述某些函数的结果如何传给其他函数。无论使用 let 绑定,还是使用点号和美元符号运算符,本质并无不同。上面的 writeCsv 就是一个例子:我们从一组函数组合出最终写 CSV 到文件的 IO 动作。
注意 RecordWildCards 语言扩展以及 $、. 运算符如何在代码中很好地协同。Haskell 以及函数式编程通常都围绕函数组合展开,而这里正好展示了不同功能如何组合成大于各部分之和的整体。
最后,我们想处理美观打印,也就是以人类可读形式展示信息。当然,这件事非常主观。因此,本章会把这部分主要作为练习。我们会讨论架构结构,实际实现留给读者完成。
先讨论美观打印接口应该是什么样。一个问题是 Csv 是参数化的。它可以包含任意类型,甚至包括无法打印的类型。因此,美观打印应该限制为至少能够转换成 Text 的类型。此外,在打印时,我们希望按列打印摘要,而这并没有在 Csv 类型中显式建模。为了表示这个额外约束,并更好地区分普通值和值得美观打印的值,定义一个新类型,如下所示。
代码清单 8.9 美观 CSV 类型
data PrettyCsv = PrettyCsv
{ pcHeader :: Maybe [T.Text], -- #1
pcColumns :: [[T.Text]], -- #2
pcSummaries :: Maybe [T.Text] -- #3
}
deriving (Eq, Show)
- #1 可选表头
- #2 已转换为文本的列
- #3 可选列摘要
请注意,我们使用类型缩写 pc 作为字段前缀,以避免与 Csv 类型中的字段名冲突。使用这个新类型,可以把 Csv 转换为 PrettyCsv,再添加摘要并创建足以让用户欣赏的漂亮输出。不过,美是主观的,所以我不想在这里规定某个固定标准。现在轮到你编写美观打印算法了。可以使用下面的模板代码。
代码清单 8.10 美观打印函数模板
fromCsv :: Csv -> PrettyCsv
fromCsv = ... -- #1
withSummaries ::
PrettyCsv ->
[T.Text] ->
Either String PrettyCsv
withSummaries = ... -- #2
pretty :: PrettyCsv -> String
pretty = T.unpack . prettyText
prettyText :: PrettyCsv -> T.Text
prettyText = ... -- #3
项目源码包含这些函数的可能实现,但依然鼓励你先尝试自己实现。
8.3.1 CSV 操作(Operations on CSVs)
到目前为止,我们已经为 CSV 表实现了一些有用操作,并能在屏幕上显示附加摘要。现在,是时候为列摘要填入有意义的内容了。为此,我们希望按列折叠 Csv 值,把列中的所有值合并成一个摘要。
可以通过映射每一列并分别折叠它们来做到这一点。
代码清单 8.11 在 CSV 表上折叠,将每列合并为一个值
foldCsv :: (DataField -> b -> b) -> b -> Csv -> [b]
foldCsv f z (Csv {csvColumns}) = map (foldr f z) csvColumns -- #1
- #1 对每一列执行右折叠
遗憾的是,不能用这个 fold 为 Csv 创建 Foldable 实例,因为 Csv 的 kind 是 *,而不是 * -> *。
处理这些数据时,另一个有用操作是对表行执行搜索。类似列表的 filter 函数,我们可以为 Csv 定义过滤函数。为此,需要把列转置为行,过滤它们,然后再转置回来。
代码清单 8.12 CSV 表过滤函数
filterCsv :: (DataField -> Bool) -> Csv -> Csv
filterCsv p csv@(Csv {csvColumns}) = -- #1
let rows = L.transpose csvColumns -- #2
filtered = L.filter (any p) rows -- #3
in csv {csvColumns = L.transpose filtered} -- #4
- #1 使用
@模式绑定保留整个csv值 - #2 将列转换为行
- #3 保留至少一个字段满足谓词的行
- #4 将过滤后的行转回列,并更新 CSV
any 是列表函数,如果给定谓词对列表中任意元素成立,它就返回 True。在我们的代码中,只要某行至少一个字段满足谓词,就接受该行。
这个定义还展示了 Haskell 的另一个语法技巧:@ 称为模式绑定。它会把某个模式的一部分绑定到名称。在我们的函数中,第二个参数被模式匹配,同时绑定到名称 csv,因此未拆开的完整值也能在函数定义中访问。
现在已经构造了两个非常通用的函数,可以定义更具体的功能。对于 Csv 值,可以用 foldCsv 统计所有非空值,因为空值用 NullValue 表示。类似地,也可以统计某个特定 DataField 出现的次数。最后,还想定义一个过滤器:如果 Csv 的某个条目包含指定 Text,则匹配。实现如下。
代码清单 8.13 基于折叠和过滤的 CSV 表操作
countNonEmpty :: Csv -> [Int]
countNonEmpty = foldCsv f 0 -- #1
where
f NullValue acc = acc
f _ acc = acc + 1
countOccurences :: DataField -> Csv -> [Int]
countOccurences df =
foldCsv (\x acc -> if x == df then acc + 1 else acc) 0 -- #2
searchText :: T.Text -> Csv -> Csv
searchText t = filterCsv (\f -> dataFieldToText f `contains` t) -- #3
where
contains = flip T.isInfixOf
- #1 统计每列非空值数量
- #2 统计指定字段值在每列出现的次数
- #3 搜索包含指定文本的行
这些函数现在可以作为 CSV 操作的基础。我们可以把它们放入一个新模块 Csv.Operations,并再次从 Csv 模块重新导出。
练习:摘要和过滤器
当然,还有许多可能的摘要和过滤器等待实现。例如,可以创建一个摘要,统计某个特定 Text 在一列中出现多少次;也可以统计某些数值高于或低于指定数值的次数。
更勇敢的读者可以尝试使用 regex 包,并基于正则表达式实现 Csv 过滤器。这需要阅读该包的文档。
8.4 简单命令行解析器(A simple command-line parser)
在这个项目中,我们已经实现了大量处理 CSV 文件的功能。可以解析它们、切片它们、拼接它们、映射它们,并写入文件或打印到终端。不过到目前为止,这些功能还比较松散,没有真正用起来。现在,我们将看看如何把代码转换成一个真正的工具。
为此,我们会再次查看如何从命令行解析参数。不过,这一次,我们希望使用新学到的技能编写小型解析器,用于判断某些键是否被设置。
首先,需要以某种方式包装 System.Environment 中的 getArgs 函数,让它返回 Text 而不是 String。再看一下它的类型:
getArgs :: IO [String]
这里可以看到,我们需要映射这个 IO 动作返回的列表,并把所有 String 元素打包成 Text。虽然已经知道如何用 do 记法实现这一点,但还有更简单的方式:IO 也有 Functor 实例!这意味着可以使用 fmap 和 <$> 映射 IO 动作的内部类型和值。在这个例子中,我们希望把一个把 String 列表打包成 Text 列表的函数映射进 IO:
getArguments :: IO [T.Text]
getArguments = map T.pack <$> getArgs
getArgs 的结果会用 T.pack 映射。请记住,<$> 运算符是 fmap 的中缀版本。它让 map T.pack 直接作用于参数。不过,从 fmap 的类型可以清楚看到,这意味着结果本身仍然是 IO。这是一般规则:对列表使用 fmap 时结果仍是列表;对 Maybe 使用时仍是 Maybe。
基于此,可以创建更多 IO 动作用于解析参数。这些函数的实现留给读者,虽然项目仓库会包含完整源码。这里我们讨论参数应如何组织和格式化。
程序的所有参数都应以 -- 开头。任何不是布尔标志但包含数据的参数,都应格式化为 --argument-name=value,其中 value 可以拥有某种指定格式。应支持以下参数类型:
Bool:如果参数被设置则为True,否则为False,例如--argument-nameChar:表示输入的字符,但只有在它是单个字符时才成立,例如--argument-name=,,而不是--argument-name=abcText:表示值中的输入文本Interval:由单个逗号分隔的Int区间,例如--argument-name=1,5
应放入独立模块的相关函数如下:
getBool :: T.Text -> IO Bool
getChar :: T.Text -> IO (Maybe Char)
getText :: T.Text -> IO (Maybe T.Text)
getInterval :: T.Text -> IO (Maybe (Int, Int))
在示例中,这些函数实现在 Util.Arguments 模块中,并在代码中以限定名称 Args 引用。再次轮到你实现这些函数。如果觉得懒,也可以从代码仓库复制。编写一个辅助函数读取一般的 --key=value 形式会很有帮助。
注意 当然,大多数人不会实现自己的参数解析器,因为已经有许多库可用于此目的。其中之一是
optparse-applicative,你也可以在这个项目中使用它。后续章节会介绍这个库。
8.4.1 支持标志与复杂参数(Supporting flags and complicated arguments)
参数解析完成后,可以思考如何把目前构造出的各种功能组合起来。为此,我们想使用参数工具来定义解析器行为、数据转换方式,以及如何打印或写出结果。希望支持以下参数:
--in=<path>:使用<path>处的 CSV 文件作为主输入--append=<path>:使用<path>处的 CSV 文件作为额外输入,追加到主输入数据右侧--field-separator=<char>:指定主输入和额外输入文件解析时的字段分隔符--with-header:让解析器在主输入和额外输入文件中寻找表头--slice=<x>,<y>:在指定索引处对结果 CSV 切片--search=<term>:过滤 CSV,保留包含搜索词的行--count-non-empty:在美观输出中添加每列非空字段数量摘要--no-pretty:禁用默认启用的美观 CSV 输出--out=<path>:指定写入转换后 CSV 的路径;如果路径为-,则把内容打印到标准输出
因为我们希望有多个参数会读取 CSV 文件,并且在解析时还使用额外标志,所以应把读取文件的功能封装到自己的 IO 动作中。它会根据给定参数创建解析选项,并据此解析。代码如下。
代码清单 8.14 使用参数指定的解析选项读取文件的动作
parseInFile :: T.Text -> IO (Either String (Csv.Csv T.Text))
parseInFile key = do
mInFile <- Args.getText key -- #1
mFieldSep <- Args.getChar "field-separator" -- #1
hasHeader <- Args.getBool "with-header" -- #1
let separators =
Csv.defaultSeparators
{ Csv.fieldSeparator =
M.fromMaybe -- #2
(Csv.fieldSeparator Csv.defaultSeparators)
mFieldSep
}
headerOpt =
if hasHeader -- #3
then Csv.WithHeader
else Csv.WithoutHeader
parseOpts =
Csv.CsvParseOptions
{ Csv.separators = separators,
Csv.headerOption = headerOpt
}
case mInFile of
Just inFile -> do
contents <- TIO.readFile $ T.unpack inFile -- #4
return $ Csv.parseCsv parseOpts contents -- #5
_ -> return $ Left "argument not set" -- #6
- #1 读取命令行参数
- #2 如果没有指定字段分隔符,则使用默认值
- #3 根据标志选择是否解析表头
- #4 读取指定输入文件
- #5 使用构造出的选项解析文件内容
- #6 输入文件参数缺失时返回错误
构造好这个函数之后,可以思考如何编写 main 动作。显然,首先必须检查 in 参数是否被设置。如果没有,就简单打印错误消息并结束程序:
main :: IO ()
main = do
mCsv <- parseInFile "in"
case mCsv of
Left _ -> putStrLn "no input file given (do so with --in=...)"
Right csv -> do
...
下一步更具挑战性。必须对解析出的 Csv 执行转换。该怎么做?虽然可以检查每一个参数,并基于它们执行转换,但还有一种可以说更漂亮的方式。由于函数只是值,当然可以像处理其他数据一样处理它们。这意味着可以收集函数(例如放入列表),并从它们计算出新值,也就是这里的新函数。我们的策略是:把参数查找结果映射为操作,然后把这些操作组合成一个单一转换操作,再对目标 Csv 值调用它。
代码清单 8.15 读取可选参数并推导行为
...
Right csv -> do
mAppend <- eitherToMaybe <$> parseInFile "append" -- #1
mSliceInterval <- Args.getInterval "slice" -- #1
mSearch <- Args.getText "search" -- #1
let mAppendOp = fmap (flip (<>)) mAppend -- #2
mSliceOp = fmap (uncurry slice) mSliceInterval -- #2
mSearchOp = fmap Csv.searchText mSearch -- #2
transformOp =
foldl -- #3
(\t mOp -> (M.fromMaybe id mOp) . t)
id
[mAppendOp, mSliceOp, mSearchOp]
dataCsv = Csv.toDataCsv $ transformOp csv -- #4
...
eitherToMaybe :: Either b a -> Maybe a
eitherToMaybe (Left _) = Nothing
eitherToMaybe (Right x) = Just x
- #1 读取可能存在的转换参数
- #2 把存在的参数转换成 CSV 转换函数
- #3 把所有可选转换组合成单个转换函数
- #4 将转换后的 CSV 转换为数据 CSV
这里使用的 uncurry 函数接收一个二元函数,并创建一个接收二元组的一元函数,产生相同结果。它的对偶是 curry。这里使用 uncurry,是为了让 slice 函数接受 mSliceInterval 内部的区间元组。
注意
curry这个名字来自柯里化概念。柯里化告诉我们,任何多参数函数都可以重写为一系列一元函数。你可能还记得第 2 章中的例子,我们探索过如何用两个匿名一元函数构造二元函数(f = \x -> \y -> ...)。这正是让我们能把任何有限参数函数重写为一系列一元函数的概念。它由数学家 Haskell Curry 推广;本书学习的编程语言 Haskell 也以他的名字命名。
现在,程序已经通过命令行参数暴露了功能,只需要考虑如何把数据呈现给外部世界。我们希望允许用户把 CSV 表写入文件,或把文件内容打印到标准输出以便进一步处理。或者,用户也可以得到数据的美观表示。幸运的是,为了做到这些,不需要学习任何新的复杂特性。只需要模式匹配,以及一个用于选择性执行 IO 动作的函数:
when :: Bool -> IO () -> IO ()
when True act = act
when False _ = return ()
unless :: Bool -> IO () -> IO ()
unless b = when (not b)
使用 unless,可以写出较大的表达式,而不必把它包进 case 或 if。
代码清单 8.16 读取可选参数并推导输出行为
mOut <- Args.getText "out" -- #1
case mOut of
Just "-" -> TIO.putStrLn $ Csv.toFileContent dataCsv -- #2
Just fp -> Csv.writeCsv (T.unpack fp) dataCsv -- #3
_ -> do
countNonEmpty <- Args.getBool "count-non-empty" -- #1
let mSummary = -- #4
if countNonEmpty
then Just $ Csv.countNonEmpty dataCsv
else Nothing
noPrettyOut <- Args.getBool "no-pretty" -- #1
unless noPrettyOut $ -- #5
TIO.putStrLn $ -- #6
Csv.prettyText $
maybe -- #7
id
(flip Csv.withSummaries)
mSummary
(Csv.fromCsv dataCsv)
- #1 读取输出相关参数
- #2
--out=-时将 CSV 文件内容写到标准输出 - #3
--out=<path>时写入文件 - #4 根据参数决定是否生成摘要
- #5 未禁用美观输出时执行打印动作
- #6 打印美观文本
- #7 如果存在摘要,则附加摘要,否则保持原值
这就完成了我们的实现。我们构造了一个库,可以把 CSV 文件解析成数据模型,并在其上构建算法。我们介绍了处理数据的通用概念,例如 Semigroup 和 Monoid 类型类,甚至引入了自己的类型类,用于切片数据以及处理与 Text 的转换。然后,我们把功能暴露给外部世界,让它们可访问、可配置。
练习:大量选项
现在轮到你了。我们已经为一个可以读取、操作和写入 CSV 文件的工具建立了基础,但还没有释放它的全部潜力。请通过实现更多过滤器、搜索策略或 CSV 输出方式扩展程序。下面是一些起步思路:
- CSV 表连接
- 数值过滤(
> n和< n) - 为文件输出配置格式
- 为输入和追加指定多个文件
- 查找并替换行中的字符串
- 将 CSV 表导出为 SQL
CREATE语句 - 支持更多数据类型,例如浮点数或布尔值
- 使用分隔符嗅探,也就是让程序推断文件中可能使用了哪些分隔符
更有冒险精神的读者可以尝试实现一些需要更多工作的额外功能:
- CSV 文件与 JSON 文件之间的转换。为此可以查看
aeson包。 - 带终端用户界面的交互模式,用于探索更大的 CSV 表。可以查看
brick包,它能帮助你构建命令行用户界面,并提供可用于在屏幕上打印表格的Table类型。
最后,我们想把工具安装到计算机上。当然,这一步是可选的,但当我们构建有用软件时很值得做。运行 stack install 后,程序会被构建并安装到本地目录。把该目录路径加入环境变量 PATH 后,就可以使用程序了。在我们的例子中,csview 是现在可用于所有 CSV 探索需求的可执行文件。
总结
Text.Read模块中的readMaybe可用于安全解析数值。- 折叠用于把复杂数据归约为单个值。
foldl从左侧结合其函数,而foldr从右侧结合。- Functor 用于映射包含在某个类型中的数据。
- kind 之于类型,就像类型之于值。
(<$>)是fmap的中缀版本。(.)运算符用于函数组合,并满足(.) f g x = f (g x)。